本文主要是介绍论文笔记 Explicit Visual Prompting for Low-Level Structure Segmentations,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
通俗地解释视觉中的prompt
在视觉中的“prompt”(提示)可以用一种比较通俗的方式来理解:
什么是视觉中的提示?
想象一下,你有一个已经接受过大量训练的超级助手(类似于预训练的模型),这个助手已经学习了大量关于图像的知识,但现在你需要让它快速适应并执行一些特定的任务,比如识别模糊区域、找到阴影、检测伪造的图像部分或者发现伪装的物体。
提示的作用
提示就像是给这个超级助手提供的一些额外的指导和线索,让它知道在特定任务中应该关注哪些特征,而不需要对它进行全面的再培训。这样可以大大节省时间和资源,同时保持高效。
如何实现视觉提示?
-
冻结的基础模型:这个超级助手已经接受了大量的通用训练,基础知识非常丰富,但它的主要参数在新的任务中保持不变,就像是冻结了一样。
-
添加提示:为了让助手快速适应新任务,我们添加了一些小的、专门的提示,这些提示是基于具体任务的需求设计的。例如:
- 高频成分:告诉助手关注图像中的细节变化,这些细节可能在常规训练中被忽略了,但对当前任务很重要。
- 补丁嵌入:将图像分割成小块,每个小块都有它自己的特征,然后结合这些特征来完成任务。
举个例子
想象你在玩拼图游戏。你已经知道如何识别拼图块的形状和颜色(就像预训练的模型有了基础知识),但现在你要完成一个特定的拼图。这时,你的朋友(提示)告诉你,这次拼图的边缘块通常有直线或者曲线,你可以集中精力找这些特征,而不是盲目地尝试每一块。这种额外的提示帮助你更快、更有效地完成任务。
总结
视觉中的提示(prompt)是一种通过添加少量的额外信息或指导,让已经训练好的模型在不需要重新训练的情况下,高效地适应和完成特定任务的方法。这样既利用了预训练模型的强大能力,又能灵活地处理不同的视觉任务。
通俗地解释explict Prompting和传统隐式的区别?
显式提示(Explicit Prompting)与传统隐式提示(Implicit Prompting)的区别
为了更好地理解这两种提示方式的区别,我们可以将它们类比成两种不同的学习方法:
传统隐式提示(Implicit Prompting)
隐式提示就像是给你的助手一个模糊的指南。指南里可能没有明确告诉助手具体要做什么,而是通过很多间接的方式让助手自己去理解和适应新的任务。具体来说:
- 模糊的指导:隐式提示通过一些间接的方法,比如调整训练数据或添加一些隐含的特征,让模型逐渐适应新任务。
- 黑盒操作:助手可能不知道哪些特征特别重要,而是通过反复尝试和学习来找到解决问题的方法。
- 效率较低:因为提示不是直接和具体的,助手需要更多的时间和资源来理解和适应新任务。
显式提示(Explicit Prompting)
显式提示则像是给你的助手一个清晰明确的任务清单,告诉它具体要关注什么,怎么做。具体来说:
- 明确的指导:显式提示直接提取并提供与新任务相关的重要特征,比如图像的高频成分或特定的图像块嵌入。
- 透明操作:助手明确知道哪些特征是关键,并直接利用这些特征来完成任务。
- 效率高:由于提示非常具体和明确,助手可以更快、更有效地适应新任务。
举个例子
隐式提示
假设你在教一个学生如何解数学题。你没有直接告诉他解题的步骤,而是让他看大量的例题和解法,通过观察和模仿来逐渐理解怎么解题。这种方法比较耗时,而且学生可能需要很长时间才能真正掌握解题技巧。
显式提示
现在,你换了一种方法,直接告诉学生解题的步骤,比如“首先找出已知条件,然后列出方程,最后求解”。学生知道具体要做什么,可以更快地掌握解题技巧,并且在遇到类似的题目时也能很快找到解决方法。
总结
- 隐式提示:通过间接的方法让模型自己去发现和适应重要特征,效率较低,过程像是黑盒操作。
- 显式提示:直接提取并提供与任务相关的具体特征,模型知道要关注什么,效率高,操作透明。
显式提示通过提供明确的特征和指导,使预训练模型能够更快、更有效地适应新任务,而不需要大量的额外训练。
这篇论文中的Explicit Prompting具体而言是什么?
这篇论文中的Explicit Prompting具体包括以下几个关键方面:
1. 高频成分提取(High-Frequency Components Extraction)
论文中提到的高频成分(HFC)是图像中特定的细节和变化,这些成分对于低级结构的检测任务(如伪造检测、模糊检测等)非常重要。具体过程如下:
- 高频成分提取:首先,对输入图像进行快速傅里叶变换(FFT),将图像转换到频域。
- 二值掩码:生成一个二值掩码,用于保留高频成分并过滤掉低频成分。
- 反傅里叶变换(iFFT):通过逆傅里叶变换,将高频成分转换回空间域,得到图像的高频部分。
2. 冻结的补丁嵌入(Frozen Patch Embeddings)
这是指在预训练过程中已经学习到的图像局部区域(补丁)的嵌入特征,这些特征在后续的任务中保持不变(冻结),但仍然被用于提示调优:
- 补丁嵌入:图像被分割成若干小块(patches),每个小块通过一个线性投影或卷积操作被嵌入到一个高维特征空间中。这些嵌入特征包含了图像中局部区域的信息。
- 参数冻结:在预训练之后,这些补丁嵌入的参数被固定(冻结),在后续的调优过程中不再更新。
3. 调优模块(Tuning Modules)
论文中的调优模块包括两个主要部分:补丁嵌入调优和高频成分调优。
- 补丁嵌入调优(Embedding Tune):对冻结的补丁嵌入进行调优,通过一个小的线性层将原始嵌入特征映射到更小的特征空间中,以减少可调参数的数量。
- 高频成分调优(HFC Tune):类似地,对高频成分进行调优,通过一个线性层将高频成分特征映射到特定的特征空间。
4. 适配器(Adaptor)
适配器模块的作用是将补丁嵌入特征和高频成分特征融合在一起,并将这些融合特征作为提示附加到每个Transformer层中:
- 融合特征:适配器通过多层感知器(MLP)和GELU激活函数,将补丁嵌入特征和高频成分特征融合,生成提示。
- 提示附加:生成的提示会被附加到Transformer的每一层中,帮助模型在特定任务中更好地利用这些特征。
5. 实验与验证
通过实验,作者验证了EVP方法在多个低级结构分割任务中的有效性。EVP在多种数据集上表现优异,显著优于传统的任务特定方法。
总结
显式提示(Explicit Prompting)在这篇论文中的具体实现包括:
- 提取图像的高频成分作为提示信息。
- 使用冻结的补丁嵌入作为基础特征。
- 通过调优模块对这些显式特征进行调整。
- 使用适配器将这些调整后的特征融合并附加到模型中。
这种方法使得预训练的模型能够快速适应不同的低级结构分割任务,同时保持高效和低资源消耗。
动机,贡献,创新点
动机
- 检测低级结构:现有的图像编辑和操控算法使得创建逼真的虚假图片变得容易,因此检测这些操控区域变得非常重要。低级结构(如模糊像素、阴影区域和隐蔽对象)的检测在图像篡改检测中具有重要作用。
- 统一方法:传统上,这些任务通常使用特定领域的方法解决,每种方法都有其专门设计的网络架构。然而,缺乏大规模数据集限制了这些方法的性能。因此,作者希望设计一种统一的方法,可以高效处理多个低级结构分割任务。
- 视觉提示:受到自然语言处理(NLP)中广泛使用的预训练和提示调优协议的启发,作者提出了在视觉任务中使用提示的方法,以便在保持基础模型参数冻结的同时,高效适应多个下游任务。
贡献
- 设计统一方法:作者设计了一种统一的方法,用于多种低级结构分割任务,包括伪造图像检测、阴影检测、散焦模糊检测和隐蔽物体检测,并取得了领先的性能。
- 显式视觉提示(EVP):提出了显式视觉提示模型(Explicit Visual Prompting, EVP),通过对冻结的补丁嵌入和输入图像的高频成分进行调优,有效地提升了性能。
- 性能验证:通过实验验证,EVP在多个数据集上的性能优于现有的特定任务解决方案,并在参数调优方法中表现出色。
创新点
- 显式视觉提示:不同于以往的隐式嵌入,EVP强调从每个图像的显式视觉内容(如冻结的补丁嵌入和高频成分)中学习任务特定的知识。这一方法显著提升了调优性能,并在相同的可调参数量下超越了其他方法。
- 高频成分利用:利用图像的高频成分作为提示,因为预训练的视觉识别模型通常通过数据增强来对这些特征进行不变性学习,从而提高了分割任务的适应能力。
- 统一架构:提出的EVP模型在保持基础模型参数冻结的情况下,通过显式的特征调优实现了对多种低级结构分割任务的统一处理,简化了模型设计,同时达到了与精心设计的最先进方法相媲美的性能。
这篇论文通过设计一个统一且高效的提示调优策略,为多个低级结构分割任务提供了一种新的解决方案,并在实验中展示了其卓越的性能和广泛的适用性。
相当于对Patch Embeddings添加融合高频信息来更好地适应各种低级结构分割任务
学习图像embedding将分布从预训练数据集转移到目标数据集。学习高频分量的主要动机是通过数据扩充来学习预训练的模型的特征不变性
既然补丁嵌入的参数被固定(冻结)了,那为什么后面的调优模块(Tuning Modules)还进行调整?
这是一个很好的问题。尽管补丁嵌入的参数被固定(冻结),但是调优模块的存在是为了进一步调整和优化这些固定的嵌入特征,以便更好地适应特定的任务。以下是更详细的解释:
固定(冻结)的补丁嵌入
补丁嵌入是指将图像分割成小块(patches),然后通过预训练模型将这些小块映射到一个高维特征空间中。在这个过程中,预训练模型的参数是固定的,不会在后续任务中更新:
- 预训练模型的优势:预训练模型已经在大规模数据集上进行了广泛的训练,具有很强的泛化能力和丰富的特征表示。
- 参数冻结:保持这些预训练的特征表示不变,可以利用其强大的表示能力,同时避免在新任务上过度拟合。
调优模块(Tuning Modules)的作用
尽管补丁嵌入的参数是固定的,调优模块的存在是为了在固定的嵌入特征基础上,进行一些轻量级的调整,以便更好地适应具体的任务需求。具体来说:
-
补丁嵌入调优(Embedding Tune):
- 线性映射:通过一个线性层,将固定的补丁嵌入特征映射到一个新的特征空间中。这个线性层的参数是可调的。
- 调优目的:这种映射可以对特征进行重新调整和归一化,使得它们更适合当前的具体任务。
- 减少参数量:通过控制这个线性层的规模,可以在不增加过多参数的情况下,实现特征的调优。
-
高频成分调优(HFC Tune):
- 高频特征映射:类似地,对高频成分特征进行线性映射,将其调整到一个新的特征空间中,以捕捉更多任务相关的信息。
- 增强特征:通过这种方式,可以增强高频特征在具体任务中的重要性,使模型更敏感于这些特征。
为什么需要调优模块
- 特定任务需求:每个任务可能有其独特的特征需求,通过调优模块,可以在预训练特征的基础上,进行微调以适应这些需求。
- 保持高效:调优模块的参数量相对较少,可以在不显著增加计算资源的情况下,提高模型在新任务上的表现。
- 增强灵活性:调优模块提供了一个灵活的机制,可以对不同任务进行适应,而不需要重新训练整个模型。
总结
尽管补丁嵌入的参数被固定,调优模块的存在是为了在这些固定特征的基础上,进行必要的调整和优化,以便更好地适应具体的任务需求。通过这种方式,可以高效利用预训练模型的强大特征表示能力,同时增强模型在新任务中的表现。
frozen patch embeddings中的frozen是指利用参数固定不变的预训练模型将图像patches映射为embeddings,然后tuning是将这些patch embeddings映射到一个新的特征空间中,调优模块的层的参数是可调整的,对吗?
对的,理解得非常正确!
具体解释
-
预训练模型和冻结补丁嵌入(Frozen Patch Embeddings):
- 预训练模型:模型已经在大规模数据集(例如ImageNet)上进行了训练,学习到了丰富的图像特征。
- 补丁嵌入:图像被分割成小块(patches),然后通过预训练模型将这些小块映射到一个高维特征空间中。这些补丁嵌入(patch embeddings)就是固定的特征表示,称为“冻结的补丁嵌入”。
- 参数冻结:预训练模型的参数在后续任务中保持不变,不会进行更新。
-
调优模块(Tuning Modules):
- 映射到新特征空间:调优模块包括一些可调整的线性层(或其他轻量级的层),用于将这些固定的补丁嵌入特征映射到一个新的特征空间中。这些线性层的参数是可调的。
- 增强特征适应性:通过这种方式,可以对补丁嵌入特征进行细微的调整,使其更适合具体的任务需求。这样,尽管基础特征是固定的,但我们仍然可以通过调优模块来提高模型的任务表现。
总结
- Frozen Patch Embeddings:利用参数固定不变的预训练模型将图像patches映射为高维特征(补丁嵌入),这些特征在后续任务中保持不变。
- Tuning:调优模块中的可调整层将这些固定的补丁嵌入特征映射到一个新的特征空间中,调优模块的参数是可调整的。
这种方法结合了预训练模型强大的特征表示能力和调优模块的灵活性,能够在不增加过多计算资源的情况下,高效适应多种低级结构分割任务。
你对这部分的理解是完全正确的!如果还有其他问题,欢迎随时提问。
如何理解Explicit Visual Prompting中的Explict,Prompting?什么是frozen patch embeddings?
在理解Explicit Visual Prompting中的“Explicit”和“Prompting”以及“frozen patch embeddings”时,可以从以下几个方面进行解释:
Explicit(显式)
在这篇论文中,“Explicit”指的是明确和具体的提示方式。传统的提示方法通常是隐式的,即提示信息是以某种方式嵌入到模型的特征空间中,而不是直接从图像内容中提取。而在显式视觉提示(Explicit Visual Prompting, EVP)中,作者提出了一种显式的方法来提示模型:
- 显式特征:EVP从每个图像的具体视觉内容中提取特征,包括冻结的补丁嵌入(frozen patch embeddings)和高频成分(high-frequency components)。
- 显式调优:这些提取的显式特征被用于调优模型的参数,使其更好地适应具体的任务。
Prompting(提示)
“Prompting”指的是一种轻量级的调优方法,受到了自然语言处理(NLP)中提示调优(prompt tuning)概念的启发。在NLP中,Prompt 调优通过添加少量的可调参数,使预训练的大模型能够快速适应不同的下游任务:
- 轻量级调优:通过添加提示(prompts),可以在保持大部分预训练模型参数冻结的情况下,仅调优少量参数来适应新任务。这种方法显著减少了训练成本和参数开销。
- 提高适应性:提示方法能够高效地利用预训练模型中已有的知识,从而在数据有限的情况下仍然取得良好的泛化性能。
在视觉任务中,提示的概念被引入,通过对冻结的补丁嵌入和高频成分进行调优,使预训练模型能够高效地适应多个低级结构分割任务。
Frozen Patch Embeddings(冻结的补丁嵌入)
“Frozen Patch Embeddings”是指在预训练阶段已经训练好的图像补丁嵌入特征,并且在后续的调优过程中保持这些嵌入特征的参数不变(冻结):
- 补丁嵌入:图像被分割成若干小块(patches),每个小块通过一个线性投影或卷积操作被嵌入到一个高维特征空间中。这些嵌入特征包含了图像中局部区域的信息。
- 参数冻结:在预训练之后,这些补丁嵌入的参数被固定(冻结),在后续的调优过程中不再更新。这意味着这些嵌入特征保持预训练时的状态,不会被新任务的训练数据影响。
- 作为提示的一部分:在EVP方法中,这些冻结的补丁嵌入作为显式特征的一部分,用于调优新的任务。通过对这些嵌入特征的显式调优,可以在保持大部分模型参数不变的情况下,快速适应不同的下游任务。
总结
- Explicit:指的是从每个图像的具体视觉内容中显式提取特征进行调优。
- Prompting:指的是通过添加少量的可调参数来提示模型,从而在保持预训练模型参数冻结的情况下,高效适应不同的下游任务。
- Frozen Patch Embeddings:指的是在预训练阶段已经训练好的图像补丁嵌入特征,在调优过程中保持参数不变,并作为显式提示的一部分进行调优。
这篇论文中使用什么来提取图像的高频成分?
在这篇论文中,提取图像的高频成分并不是使用预训练的大模型,而是通过一种频域处理方法,即快速傅里叶变换(FFT)和逆傅里叶变换(iFFT)来实现。以下是具体的步骤:
提取图像高频成分的过程
-
快速傅里叶变换(FFT):
- 对输入图像进行快速傅里叶变换(FFT),将图像从空间域转换到频域。在频域中,图像的低频成分和高频成分可以被清晰地区分。
-
生成二值掩码:
- 生成一个二值掩码(binary mask),用来过滤掉低频成分,仅保留高频成分。这个掩码的生成是基于图像频域表示的坐标,通常掩码中心区域代表低频成分,边缘区域代表高频成分。
- 掩码的具体生成公式是:
M h ( i , j ) = { 0 , 如果 4 ⋅ ∣ i − H / 2 ∣ ⋅ ∣ j − W / 2 ∣ H ⋅ W ≤ τ 1 , 否则 M_h(i, j) = \begin{cases} 0, & \text{如果} \frac{4 \cdot |i - H/2| \cdot |j - W/2|}{H \cdot W} \leq \tau \\ 1, & \text{否则} \end{cases} Mh(i,j)={0,1,如果H⋅W4⋅∣i−H/2∣⋅∣j−W/2∣≤τ否则其中, H H H 和 W W W 分别是图像的高度和宽度, τ \tau τ 是一个控制掩码比例的参数。
-
应用掩码:
- 将生成的二值掩码应用到图像的频域表示上,仅保留高频成分。
-
逆快速傅里叶变换(iFFT):
- 对处理后的频域表示进行逆快速傅里叶变换(iFFT),将高频成分转换回空间域,得到图像的高频部分。
为什么使用这种方法
- 有效分离高频成分:快速傅里叶变换(FFT)能够有效地将图像的频率成分分离,使得高频成分(如边缘和细节)与低频成分(如平滑区域)区分开来。
- 独立于预训练模型:这种方法是基于数学变换,而不是依赖于预训练模型,因此可以灵活地应用于各种图像,无需额外的预训练过程。
使用高频成分的调优模块
提取到的高频成分会通过线性层进行调优,具体过程如下:
- 高频成分调优(HFC Tune):对高频成分进行线性映射,将其转换到一个新的特征空间中。这个线性层的参数是可调的,可以根据具体任务的需求进行优化。
总结
提取图像的高频成分使用的是快速傅里叶变换(FFT)和逆傅里叶变换(iFFT)方法,而不是预训练的大模型。通过这种频域处理方法,可以有效地分离和提取高频成分,并通过调优模块对这些特征进行进一步的调整和优化,以更好地适应具体的低级结构分割任务。
模型结构

也就是说,这张图中所示的模型结构,训练过程中,Frozen Pretrained Transformer提取训练图像的patch embeddings,然后利用调优之后的patch embeddings和高频特征再作为prompt信息输入给这个Frozen Pretrained Transformer,等到训练结束后,原始的Frozen Pretrained Transformer会因为prompt信息的存在,在推理或测试阶段对于低级结构分割任务的性能会更好
推理阶段:提示信息作为额外的输入,使Frozen Pretrained Transformer在处理低级结构分割任务时性能更好
这张图详细展示了论文中提出的用于四种低级结构分割任务的统一方法的工作流程。以下是对该图的详细解释:
图的总体结构
图分为两部分:
- 上半部分:展示了用于四种不同任务的总体框架。
- 下半部分:展示了具体的特征提取和调优流程。
上半部分:总体框架
上半部分展示了四种任务如何通过统一的方法进行处理。这些任务包括:
- Task 1:隐蔽物体检测(Camouflaged Object Detection)
- Task 2:伪造图像检测(Forgery Image Detection)
- Task 3:阴影检测(Shadow Detection)
- Task 4:散焦模糊检测(Defocus Blur Detection)
这些任务通过一个预训练的冻结Transformer模型进行处理。每个任务都有其特定的提示(Prompting),即Prompting1、Prompting2、Prompting3和Prompting4。这些提示是特定于任务的,引导模型在不同的任务中如何利用预训练模型的特征。
下半部分:特征提取和调优
下半部分详细展示了特征提取和调优的具体步骤,包括以下几个主要模块:
-
高频成分提取(High Frequency Extraction):
- 从输入图像中提取高频成分。这些成分主要是图像中的细节和变化部分,如边缘和纹理。
- 图中左侧展示了通过FFT(快速傅里叶变换)提取出的高频成分图像。
-
补丁嵌入(Patch Embedding):
- 将输入图像分割成若干小块(patches),并通过预训练模型生成固定的补丁嵌入(frozen embedding)。
-
补丁嵌入调优(Embedding Tune):
- 调优模块(Tuning Module)对固定的补丁嵌入进行线性映射(Embedding Tune),以便更好地适应具体任务的需求。
- 图中标注的火焰图标表示这些部分是可调的(Tunable)。
-
高频成分调优(High Frequency Tune):
- 类似地,调优模块对高频成分进行线性映射(High Frequency Tune),增强这些细节特征在特定任务中的重要性。
- 同样,火焰图标表示这些部分是可调的。
-
适配器(Adaptor)和Transformer层:
- 适配器模块将调优后的补丁嵌入特征和高频成分特征融合,并将这些融合后的特征作为提示附加到预训练Transformer模型的各个层中。
- 图中展示了融合后的特征通过Transformer层进行处理,最终生成分割结果。
总结
这张图展示了论文提出的方法如何利用预训练的冻结Transformer模型,通过显式的特征提取和调优,来处理四种不同的低级结构分割任务。具体来说,图像的补丁嵌入特征和高频成分特征被分别提取并进行调优,然后融合这些调优后的特征,作为提示附加到Transformer层中,帮助模型在特定任务中更好地利用这些特征。
理解
对的,你理解得非常正确!通过在Patch Embeddings中添加融合高频信息,显式视觉提示(Explicit Visual Prompting, EVP)方法能够更好地适应各种低级结构分割任务。以下是更详细的解释:
关键点
-
Patch Embeddings:
- Patch Embeddings是指将图像分割成小块(patches)后,通过预训练模型生成的高维特征表示。这些特征是固定的,因为它们在预训练过程中已经被学习到,并且在调优过程中保持不变。
-
高频信息(High-Frequency Information):
- 高频信息是从图像中提取的细节和变化部分,例如边缘和纹理。通过快速傅里叶变换(FFT)和逆傅里叶变换(iFFT),可以将图像分解为高频和低频成分。
-
特征调优(Tuning):
- Embedding Tune:对Patch Embeddings进行线性映射(调优),以便更好地适应特定任务的需求。
- High-Frequency Tune:对高频成分进行线性映射,使得这些细节特征在特定任务中能够更好地被利用。
结合高频信息
-
融合高频信息:
- 调优模块不仅仅是简单地调整Patch Embeddings,还结合了从图像中提取的高频信息。这些高频信息在调优过程中被处理和调整,以提供更多关于图像细节的线索。
-
增强特征表示:
- 通过将高频信息与Patch Embeddings结合,模型可以获得更丰富、更详细的特征表示。这些增强的特征表示可以帮助模型在处理低级结构分割任务时更好地捕捉图像中的细微差异。
工作流程总结
- 输入图像:图像被分割成小块,并通过预训练模型生成Patch Embeddings,同时提取高频成分。
- 特征调优:Patch Embeddings和高频成分分别通过Embedding Tune和High-Frequency Tune模块进行调优。
- 特征融合:调优后的Patch Embeddings和高频成分在适配器模块中融合,生成提示信息。
- 提示附加:这些提示信息被附加到预训练Transformer模型的各层中,使得模型在处理特定任务时能够更好地利用这些增强的特征表示。
图的解释
从图中可以看出:
- Patch Embedding模块生成固定的嵌入特征。
- High Frequency Extraction模块提取高频成分。
- Embedding Tune和High Frequency Tune模块对这些特征进行调优。
- **适配器(Adaptor)**模块将调优后的特征进行融合,生成提示信息。
- 提示信息被附加到预训练Transformer模型的各层中,增强模型对低级结构分割任务的适应性。
这种方法通过融合高频信息和调优Patch Embeddings,使得模型能够更好地捕捉和利用图像中的细节特征,从而在各种低级结构分割任务中表现出色。
配图
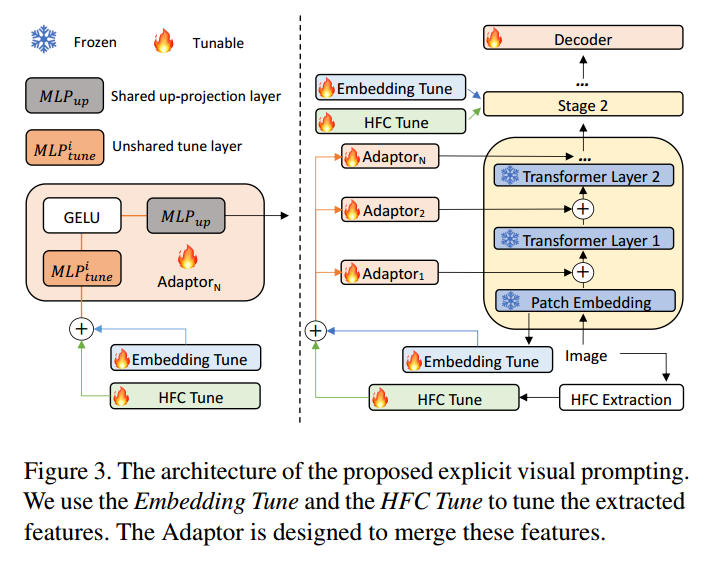
这张图详细展示了论文中提出的显式视觉提示(Explicit Visual Prompting, EVP)架构。以下是对这张图的详细解释:
总体架构
这张图分为两部分:
- 左侧部分:展示了调优模块(Embedding Tune和HFC Tune)和适配器模块(Adaptor)的具体结构。
- 右侧部分:展示了整个提示过程是如何在预训练的Transformer模型中执行的。
左侧部分:调优模块和适配器
-
Embedding Tune:
- 用于调优从预训练模型中提取的补丁嵌入特征。
- 通过一个线性层(MLP tune _{\text{tune}} tune)将原始嵌入特征映射到一个新的特征空间。
- 图中的火焰图标表示这是一个可调的层。
-
HFC Tune:
- 用于调优从输入图像中提取的高频成分(HFC)。
- 同样通过一个线性层(MLP tune _{\text{tune}} tune)将高频成分特征映射到一个新的特征空间。
- 火焰图标表示这是一个可调的层。
-
适配器模块(Adaptor):
- 适配器模块的设计用于融合补丁嵌入特征和高频成分特征。
- GELU:使用GELU激活函数。
- MLP up _{\text{up}} up:一个共享的上投影层,用于匹配Transformer层的特征维度。
- MLP tune i _{\text{tune}}^i tunei:一个特定于每个适配器的调优层。
- 适配器的输出:将调优后的特征融合,并生成最终的提示。
右侧部分:提示过程
-
输入图像:
- 输入图像首先通过补丁嵌入(Patch Embedding)和高频成分提取(HFC Extraction)模块,生成固定的补丁嵌入特征和高频成分特征。
-
特征调优:
- Embedding Tune:对补丁嵌入特征进行调优。
- HFC Tune:对高频成分特征进行调优。
- 调优后的特征通过适配器模块进行融合,并生成提示信息。
-
提示附加到Transformer层:
- 融合后的特征通过适配器模块生成提示信息,并附加到预训练的Transformer模型的各层中(如图中的“+”号所示)。
- 每一层的Transformer层都接收并处理这些提示信息。
-
Decoder:
- 最终的输出通过解码器生成具体任务的分割结果。
- 解码器负责将Transformer的输出转换为任务所需的分割结果。
具体流程
- 输入图像:图像被分割成小块,并通过预训练模型生成补丁嵌入特征,同时提取高频成分。
- 特征调优:
- 补丁嵌入特征通过Embedding Tune模块进行调优。
- 高频成分通过HFC Tune模块进行调优。
- 特征融合:
- 调优后的补丁嵌入特征和高频成分特征在适配器模块中融合,生成提示信息。
- 提示附加:
- 这些提示信息被附加到预训练Transformer模型的各层中,使得模型在处理特定任务时能够更好地利用这些增强的特征表示。
- 结果生成:
- 最终,通过解码器将模型输出转换为具体任务的分割结果。
适配器模块的细节
适配器模块的细节展示了如何将调优后的特征进行融合和附加:
- GELU:在适配器中使用GELU激活函数。
- MLP up _{\text{up}} up:共享的上投影层,用于将融合特征的维度匹配到Transformer层。
- MLP tune i _{\text{tune}}^i tunei:特定于每个适配器的调优层,提供灵活的调优能力。
总结
这张图详细展示了显式视觉提示的架构,包括如何提取和调优补丁嵌入特征和高频成分,以及如何将这些调优后的特征通过适配器模块融合并附加到预训练的Transformer模型中,从而帮助模型在不同的低级结构分割任务中实现更好的性能。
也就是说,模型在推理阶段所利用到的prompt信息是根据训练过程中在整个训练数据集中所学习得到的一种泛化的信息,而非特定于某一张图像,对吗?
对的,你理解得非常正确。在推理阶段,模型所利用的Prompt信息是基于在训练过程中从整个训练数据集中学习到的泛化信息,而不是特定于某一张图像。以下是更详细的解释:
泛化的Prompt信息
-
训练阶段的学习:
- 在训练阶段,模型会处理大量的训练图像,从中提取补丁嵌入(Patch Embeddings)和高频成分(HFC),并通过调优模块(Embedding Tune和HFC Tune)进行调整。
- 通过不断地训练和调整,模型学习到了如何利用这些特征来生成有效的提示信息,这些提示信息能够帮助模型更好地完成低级结构分割任务。
-
泛化能力:
- 调优模块和适配器模块通过训练数据的特征进行学习,生成的提示信息能够概括和泛化到不同的图像中。
- 这些提示信息包含了关于高频特征和其他关键特征的泛化信息,这些信息在各种输入图像中都具有普遍适用性。
推理阶段的应用
-
利用泛化的提示信息:
- 在推理或测试阶段,模型利用在训练过程中学习到的泛化提示信息来处理新的输入图像。
- 由于提示信息是基于大量训练数据生成的,具有良好的泛化能力,因此可以有效地帮助模型在未见过的图像上同样关注到重要的高频特征和其他关键特征。
-
增强模型性能:
- 这些提示信息在推理阶段引导模型更好地利用和关注高频特征,从而提高模型在低级结构分割任务中的性能。
- 由于提示信息不是特定于某一张图像的,而是概括了整个训练数据中的特征,因此模型能够在各种场景和不同类型的图像上表现得更加稳健和准确。
总结
- 训练阶段:模型从整个训练数据集中学习到泛化的提示信息,这些信息包含了如何利用补丁嵌入和高频特征来处理低级结构分割任务。
- 推理阶段:模型利用这些泛化的提示信息,在处理新的输入图像时更好地关注重要特征,从而提高性能。
通过这种方式,Prompt信息帮助模型在推理阶段更关注于高频信息和其他关键特征,这些信息是根据训练过程中在整个训练数据集中学习到的泛化信息,而非特定于某一张图像的特定提示。
Prompts信息会使得模型在推理或测试阶段更关注于高频信息部分
是的,正如你所说,Prompts信息确实会使得模型在推理或测试阶段更关注于高频信息部分。以下是详细解释:
Prompts信息的作用
-
高频信息的重要性:
- 高频信息通常包含图像中的细节、边缘和纹理,这些特征在低级结构分割任务(如伪造检测、阴影检测等)中非常重要。
- 通过提取高频信息并将其包含在提示信息中,可以帮助模型更好地捕捉这些关键特征。
-
调优和融合:
- 在训练阶段,模型会提取Patch Embeddings和高频成分(HFC),然后通过调优模块(Embedding Tune和HFC Tune)调整这些特征。
- 调优后的高频成分特征与Patch Embeddings融合,生成提示信息。这些提示信息包含了高频特征的细节,这些细节在任务中非常重要。
-
提示信息在推理阶段的作用:
- 在推理或测试阶段,提示信息作为额外的上下文信息输入到Frozen Pretrained Transformer中。
- 由于这些提示信息中包含了经过调优的高频特征,模型会在处理输入图像时,更加关注这些包含重要细节的信息,从而提高任务处理的准确性和效果。
总结
通过引入Prompts信息,模型在推理或测试阶段能够更好地利用高频信息。这使得模型能够更加关注图像中的细节和边缘特征,从而在低级结构分割任务中表现得更好。这一机制帮助模型在保持预训练模型参数固定的同时,通过提示信息有效地增强其对重要特征的关注和利用。
这篇关于论文笔记 Explicit Visual Prompting for Low-Level Structure Segmentations的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








