本文主要是介绍动手学深度学习24 AlexNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
动手学深度学习24 AlexNet
- 1. AlexNet
- 传统机器学习
- AlexNet
- 2. 代码
- 3. QA
1. AlexNet
传统机器学习



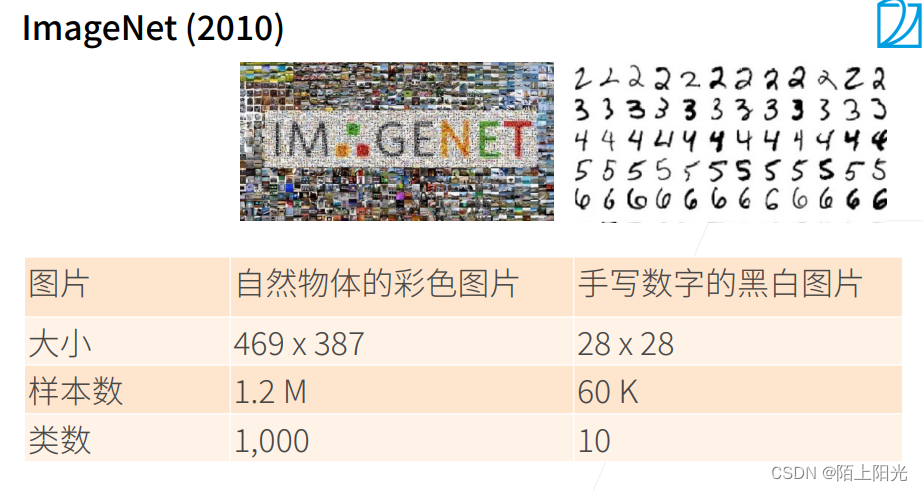
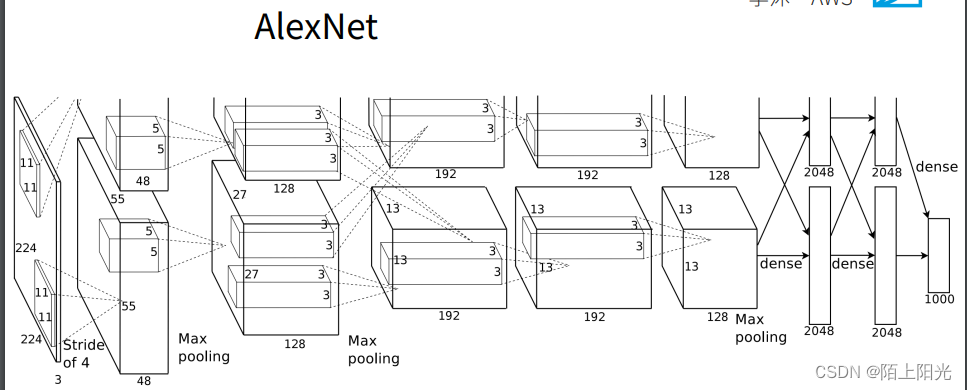
AlexNet

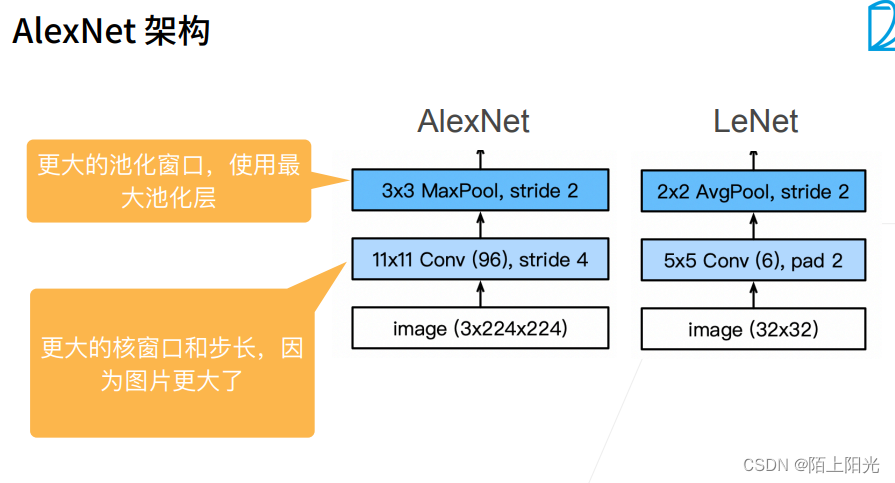
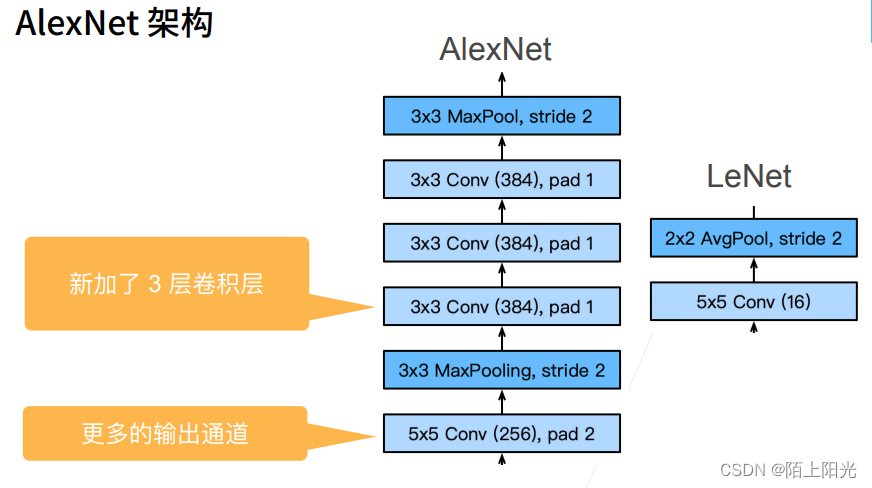
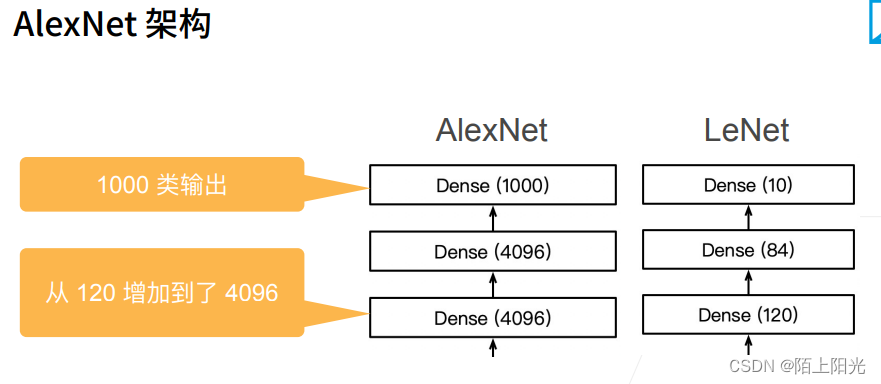
AlexNet & LeNet对比
加了三层隐藏层,通道数和全连接层单元数更多

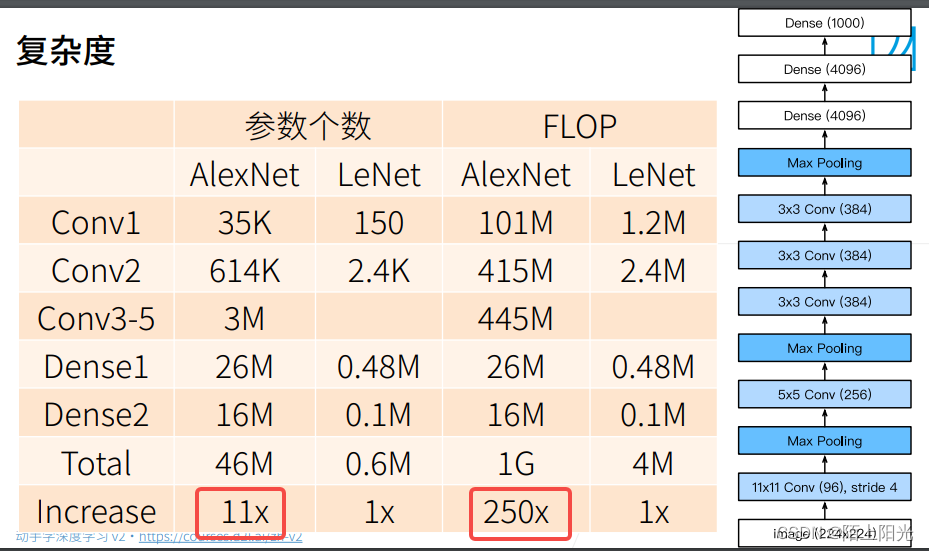
计算需要的浮点数,10亿次浮点数计算。

2. 代码
import torch
from torch import nn
from d2l import torch as d2lnet = nn.Sequential(# 这里使用一个11*11的更大窗口来捕捉对象。# 同时,步幅为4,以减少输出的高度和宽度。# 另外,输出通道的数目远大于LeNetnn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数nn.Conv2d(96, 256, kernel_size=5, padding=2), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),# 使用三个连续的卷积层和较小的卷积窗口。# 除了最后的卷积层,输出通道的数量进一步增加。# 在前两个卷积层之后,汇聚层不用于减少输入的高度和宽度nn.Conv2d(256, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 384, kernel_size=3, padding=1), nn.ReLU(),nn.Conv2d(384, 256, kernel_size=3, padding=1), nn.ReLU(),nn.MaxPool2d(kernel_size=3, stride=2),nn.Flatten(),# 这里,全连接层的输出数量是LeNet中的好几倍。使用dropout层来减轻过拟合nn.Linear(6400, 4096), nn.ReLU(), nn.Dropout(p=0.5),nn.Linear(4096, 4096), nn.ReLU(),nn.Dropout(p=0.5),# 最后是输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000nn.Linear(4096, 10)
)
X = torch.randn(1, 1, 224, 224)
for layer in net:X=layer(X)print(layer.__class__.__name__,'output shape:\t',X.shape)batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())Conv2d output shape: torch.Size([1, 96, 54, 54])
ReLU output shape: torch.Size([1, 96, 54, 54])
MaxPool2d output shape: torch.Size([1, 96, 26, 26])
Conv2d output shape: torch.Size([1, 256, 26, 26])
ReLU output shape: torch.Size([1, 256, 26, 26])
MaxPool2d output shape: torch.Size([1, 256, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 384, 12, 12])
ReLU output shape: torch.Size([1, 384, 12, 12])
Conv2d output shape: torch.Size([1, 256, 12, 12])
ReLU output shape: torch.Size([1, 256, 12, 12])
MaxPool2d output shape: torch.Size([1, 256, 5, 5])
Flatten output shape: torch.Size([1, 6400])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py:558: UserWarning: This DataLoader will create 4 worker processes in total. Our suggested max number of worker in current system is 2, which is smaller than what this DataLoader is going to create. Please be aware that excessive worker creation might get DataLoader running slow or even freeze, lower the worker number to avoid potential slowness/freeze if necessary.warnings.warn(_create_warning_msg(
training on cuda:0
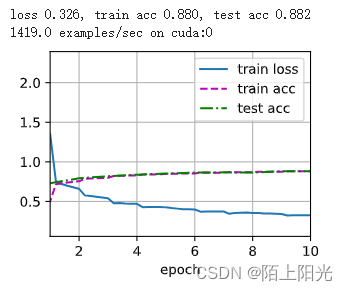
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/conv.py:456: UserWarning: Plan failed with a cudnnException: CUDNN_BACKEND_EXECUTION_PLAN_DESCRIPTOR: cudnnFinalize Descriptor Failed cudnn_status: CUDNN_STATUS_NOT_SUPPORTED (Triggered internally at ../aten/src/ATen/native/cudnn/Conv_v8.cpp:919.)return F.conv2d(input, weight, bias, self.stride,loss 0.326, train acc 0.880, test acc 0.882
1419.0 examples/sec on cuda:0
3. QA
cnn和softmax一起训练的,可能cnn学习到的就是softmax需要的,从模型层面就是一个模型,更高效一些。端到端的学习。
池化层33 22的区别:
33 往左偏往右偏都可以 22 允许往左偏一点点
最后两个全连接层在前面卷积抽取不够深的情况下继续抽取,模型更大。
参数对比, AlexNet 46M Vs LeNet 0.6M
宣传套路。
经典网络设计思路
技术基线已经很高,产品落地。
如果图片size和网络要求的size不一致,怎么处理。
多扣几个图出来。效果不会很大。
这篇关于动手学深度学习24 AlexNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




