本文主要是介绍将mysql表中数据导入到hive分区事务桶表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
3.1.1 逻辑描述
1.删除hv_orders_user_buckets表中对应分区的数据
2.按指定日期从mysql中的数据库查询数据orders0-9和orders_user0-9表的数据导入到hive中的hv_orders_user表指定的分区中。Hv_orders_user是一个分区表,不具有事务
3.将hv_orders_user表中的数据按分区导入到hv_orders_user_buckets表对应的分区中。hv_orders_user_buckets表具有分区和事务。
4.删除指定表hv_orders_use中分区的数据
为何要先把数据加载到hv_orders_user表(只具有分区),再合并到hv_orders_user_buckets(分区事务表)?
因为直接将其加载到hv_orders_user_buckets(具有分区事务)的表中,报错,不支持,只能将数据先存储到hv_orders_user表后,经过中转,合并到hv_orders_user_buckets表中
19/07/10 16:05:05 INFO hive.HiveImport: FAILED: SemanticException Unable to load data to destination table. Error: The file that you are trying to load does not match the file format of the destination table.
19/07/10 16:05:05 ERROR tool.ImportTool: Import failed: java.io.IOException: Hive exited with status 64
at org.apache.sqoop.hive.HiveImport.executeExternalHiveScript(HiveImport.java:384)
at org.apache.sqoop.hive.HiveImport.executeScript(HiveImport.java:337)
at org.apache.sqoop.hive.HiveImport.importTable(HiveImport.java:241)
at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:537)
at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:628)
at org.apache.sqoop.Sqoop.run(Sqoop.java:147)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:183)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:234)
at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)
at org.apache.sqoop.Sqoop.main(Sqoop.java:252)
3.1.2 新建表
#订单用户集成表(临时的中转表没有事务)
create table hv_orders_user(
user_id bigint,
order_no string,
total_amount decimal(10,2),
order_amount decimal(10,2),
mi_amount decimal(10,2),
unlimited_card_amount decimal(10,2),
mi_card_amount decimal(10,2),
give_mi_amount decimal(10,2),
coupon_amount decimal(10,2),
activity_amount decimal(10,2),
pay_status int,
pay_method int,
end_time string)
PARTITIONED BY (ymd string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
#订单用户集成表(具有事务,分区,桶表)
create table if not exists hv_orders_user_buckets(
user_id bigint,
order_no string,
total_amount decimal(10,2),
order_amount decimal(10,2),
mi_amount decimal(10,2),
unlimited_card_amount decimal(10,2),
mi_card_amount decimal(10,2),
give_mi_amount decimal(10,2),
coupon_amount decimal(10,2),
activity_amount decimal(10,2),
pay_status int,
pay_method int,
end_time string)
PARTITIONED BY (ymd string)
clustered by (user_id) into 10 buckets
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
stored as orc
TBLPROPERTIES('transactional'='true');
3.1.3 脚本文件import-ordersdata.sh
#!/bin/bash
#要遍历的表序号
table_name=(0 1 2 3 4 5 6 7 8 9)
analysis_date=$1#开始执行方法
function start(){echo "...........第一步:开始删除hv_orders_user_buckets表中的ymd=${analysis_date}的分区数据.............................................................................."/opt/hive-2.3.5/bin/hive -e "use hv_user_profile;ALTER TABLE hv_orders_user_buckets DROP partition(ymd='$analysis_date');" for str in ${table_name[@]}doecho "...........第二步:str:orders_${str},将mysql中orders_${str}表导入到hive的hv_orders_user表中,分区为:ymd=$analysis_date................................................................................................"sqoop import --connect jdbc:mysql://10.1.11.110:3310/meboth-userprofile?characterEncoding=UTF-8 --username baojia_xm --password 'DgisNKhg' --query "select a.user_id,a.order_no ,a.total_amount,a.order_amount,a.mi_amount,a.unlimited_card_amount,a.mi_card_amount,a.give_mi_amount,b.coupon_amount,b.activity_amount,a.pay_status,a.pay_method,b.end_time from orders_${str} as a ,orders_user_${str} as b where a.order_no=b.order_no and b.end_time like '${analysis_date}%' AND \$CONDITIONS " \--target-dir '/user/hive/warehouse/hv_user_profile.db/hv_orders_user_temp' --delete-target-dir --split-by a.user_id --hive-import --hive-database hv_user_profile --hive-table hv_orders_user --hive-drop-import-delims --hive-partition-key ymd --hive-partition-value ${analysis_date} --fields-terminated-by '\t' --m 5 --lines-terminated-by "\n";echo ".......... 第三步:str:orders_${str}, 将hv_orders_user表分区ymd=$analysis_date的数据执行合并到hv_orders_user_buckets表分区ymd=$analysis_date中........................................................."/opt/hive-2.3.5/bin/hive -e "use hv_user_profile;insert into table hv_orders_user_buckets partition(ymd='$analysis_date') select user_id,order_no,total_amount,order_amount,mi_amount,unlimited_card_amount,mi_card_amount,give_mi_amount,coupon_amount,activity_amount,pay_status,pay_method,end_time from hv_orders_user where ymd='$analysis_date';"echo "...........第四步:str:orders_${str},删除表hv_orders_user表中,分区为:ymd=$analysis_date 中的数据........................................................."/opt/hive-2.3.5/bin/hive -e "use hv_user_profile;ALTER TABLE hv_orders_user DROP partition(ymd='$analysis_date');"echo ".............................本次循环执行表为:orders_${str},分区为:ymd=$analysis_date中的数据成功successfully!!!!!!!........................................................."done
echo "程序执行完成!!!!$1"
}#程序的入口
start
3.1.4 执行脚本
[www@1-11-100 opt]$ sh import-ordersdata.sh 2019-06
3.1.5 查看结果
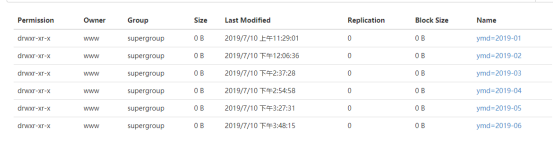
这篇关于将mysql表中数据导入到hive分区事务桶表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




