本文主要是介绍hive报Can't call rollback when autocommit=true,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
报:Error rolling back: Can't call rollback when autocommit=true
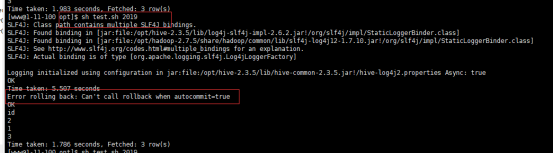
报:hive-site.xml设置为false;

这篇关于hive报Can't call rollback when autocommit=true的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![掌握Hive函数[2]:从基础到高级应用](https://i-blog.csdnimg.cn/direct/49298177ab7c4101b27f72a6abf5b84d.png)


