本文主要是介绍大模型时代的具身智能系列专题(三),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
清华高阳团队
高阳为清华叉院助理教授,本科毕业于清华大学计算机系,博士毕业于UC Berkeley。博士导师是Vision领域的大牛Trevor Darrell,读博期间和Sergey Levine合作开始强化学习方面的探索,博后跟随Pieter Abbeel做强化学习,合作的导师都是RL+Robotics这个领域的大牛。研究方向为计算机视觉和机器人的结合领域,教会机器人通过“看”去操纵周围的事物。RL用在机器人领域有一个问题是现实数据匮乏的问题,高阳的两个工作Efficient Zero和SpeedyZero就是为了解决现实世界样本效率的问题。近期其课题组产生了ViLA、CoPA等代表性工作。
主题相关作品
- ViLA
- CoPA
- ATM
ViLA
最近的进展表明,大型语言模型(Large Language Model,LLM)在机器人任务中具有广泛的知识,特别是在推理和规划方面。然而,LLM在感知环境信息(包括空间布局和对象属性)时缺乏世界grounding能力,依赖外部affordance模型的限制,不能与LLM joint reasoning(虽然LLM拥有丰富的结构化世界知识,但他们对语言输入的完全依赖需要外部组件,如功能模型(RL的值函数、检测模型、行为检测模型),来完成grounding过程。)。文章认为,任务规划器(task planner)应该是一个内在grounded、统一的多模态系统。为此,文章介绍了机器人视觉语言规划(VILA),这是一种用于长期机器人规划的新方法,它利用视觉语言模型(VLM)来生成一系列可操作的步骤。VILA直接将感知数据整合到其推理和规划过程中,从而能够深刻理解视觉世界中的常识知识,包括空间布局和对象属性。它还支持灵活的多模态目标指定,并自然地结合视觉反馈。文章在机器人和模拟环境中进行了广泛的评估,证明了VILA优于现有的基于LLM的规划器,突出了其在广泛的开放世界操作任务中的有效性。不能与推理。
method
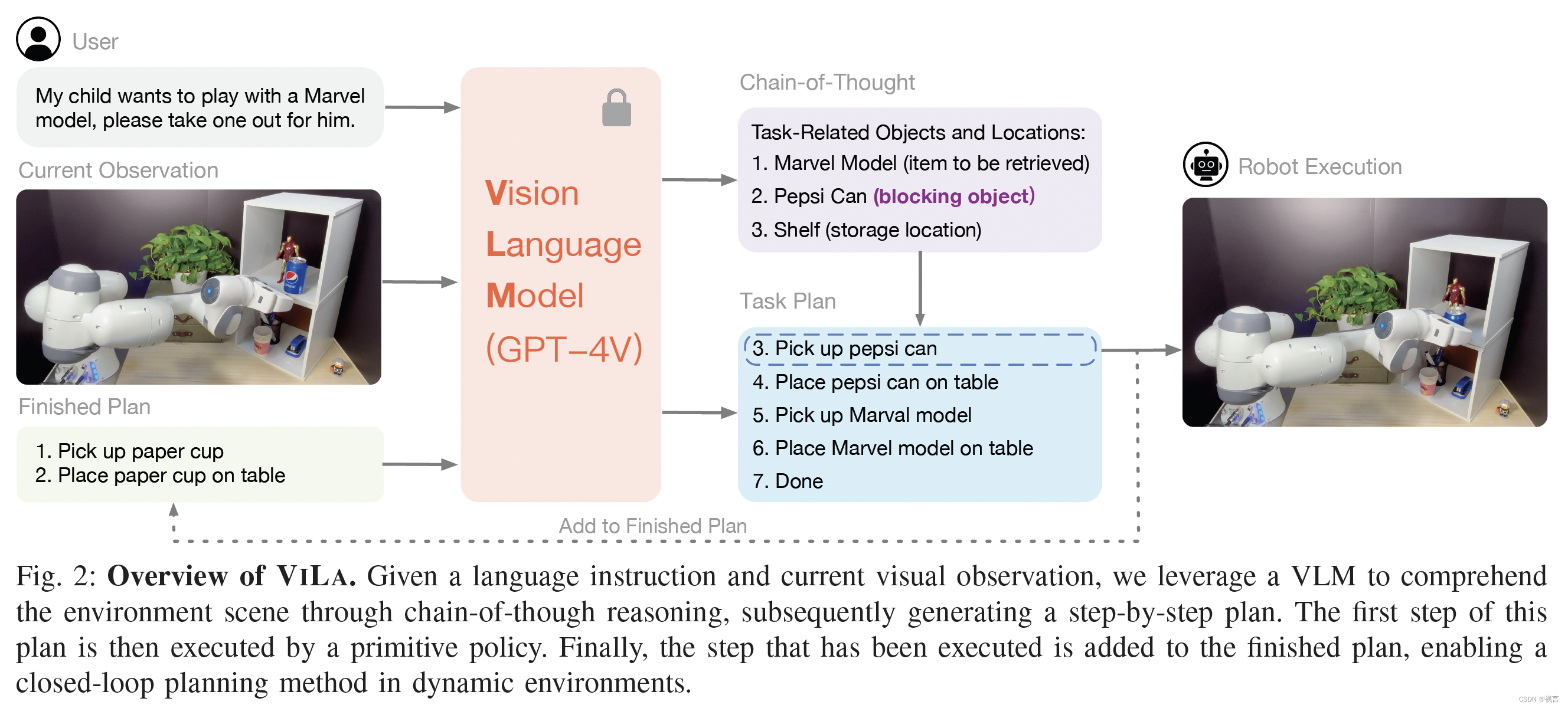
VILA中的VLM(这里采用的是GPT-4V [2])接受三个输入:用户语言指令+当前图像观测+已完成的plan,结合思维链考虑任务相关的物体和位置,输出基于当前情形的新的task plan,并选择第一条执行(调用相应脚本),直到任务完成的标志Done。

VILA的特色
视觉世界的常识理解
空间布局理解:用简单的语言描述复杂的几何结构,特别是空间定位、对象关系和环境约束,可能具有挑战性。考虑一个杂乱的场景,物体a遮挡了物体B。为了到达物体B,一个人必须首先重新放置物体a。仅仅依靠口头语言描述来传达物体之间的微妙关系是不够的。此外,考虑一下所需对象在容器(如橱柜或冰箱)内的情况。在这种情况下,如果使用外部功能模型(如对象检测模型),由于所需对象不可见,功能模型将预测成功检索的概率为零,从而导致任务失败。然而,通过直接将视觉融入推理过程,VILA可以推断出隐藏在视线之外的寻找对象可能在容器内。这种实现需要打开容器作为完成任务的第一步。
对象属性理解:一个对象是由多个属性定义的,包括它的形状、颜色、材质、功能等。然而,自然语言的表达能力是有限的,这使得它成为一种比较繁琐的媒介来全面地传达这些属性。此外,请注意,对象的属性与手头的特定任务错综复杂地联系在一起。例如,剪刀可能被认为对儿童有害,但它们在剪纸艺术课上却成为必不可少的工具。以前的方法采用独立的功能模型来标识对象属性,但是这种方法只能以单向的方式传递有限的属性子集。因此,当我们的任务要求对一个对象的属性进行全面的理解时,图像和语言之间的主动联合推理就成为了一个至关重要的必要条件。(Joint Reasoning:文章认为之前方法使用外部affordance model将信息转化为自然语言,再输入给LLM进行规划的做法会造成信息的缺失以及偏差。由一个可以统一处理这些信息的模型(VLM)得出plan,能够对这些信息有更好的理解。对于空间理解,如果有一些目前不在视野中的相关物体,外部affordance model就不能很好的识别出他们,进而导致LLM的规划错误,但是使用VLM直接将视觉融入推理过程,就可以推断出不在视野中的相关对象很可能在某个容器内,再做进一步的规划。对于对象属性,剪子可能会被外部affordance model认为是危险的,但对于 ”为孩子准备剪纸课工具“ 又是必须的,这可能会影响LLM的规划结果。)
Versatile Goal Specification
由于使用了VLM,VILA可以很自然地用图像或文字的形式灵活的明确任务目标,甚至对于不好获取goal image的任务,可以只给出合适的文生图,利用GPT-4V对图像的抽象理解能力来完成任务规划。
在许多复杂的、长期的任务中,用目标图像来代表期望的结果通常比仅仅依靠口头指示更有效。例如,要指挥机器人整理桌子,提供一张桌子的照片可以提高效率。同样地,对于食物电镀任务,机器人可以从图像中复制排列。这些任务以前无法用基于LLM的规划方法实现,现在用VILA非常简单。具体来说,VILA不仅可以接受当前的视觉观察x_n和语言指令L作为输入,还可以结合目标图像x_g。这一特征将其与许多现有的目标条件RL/IL算法区分开来,因为它不要求目标和视觉观察图像来自同一域。目标图像只需要传达任务的基本元素,在其形式上提供灵活性-它可以是网络照片,儿童绘画,甚至是用手指指向目标位置的图像。这种通用性大大提高了系统的实用性。此外,在描述任务目标时结合图像和语言的能力在我们的目标规范方法中引入了额外的灵活性和多样性。
(如下图,goal image是由文生图模型获取的)

Visual Feedback
这个也是VILA框架很自然的优点/特点,VILA支持直接使用视觉反馈,其中VLM既识别对象状态,又用作成功条件检测器。(通过对视觉反馈进行推理,VILA使机器人能够根据环境的变化或技能失败时做出更正或重新规划)
具身的环境本质上是动态的,使得闭环反馈对机器人至关重要。为了将环境反馈整合到仅依赖llm的规划方法中,Huang等人研究了将所有反馈转换为自然语言。然而,这种方法被证明是繁琐和无效的,因为大多数反馈最初是通过视觉观察到的。将视觉反馈转换成语言不仅增加了系统的复杂性,而且有可能丢失有价值的信息。我们相信直接提供视觉反馈是一种更直观和自然的方法,正如VILA所展示的那样。在VILA中,VLM既可以作为场景描述符来识别对象状态,也可以作为成功检测器来确定环境是否满足指令定义的成功条件。通过对视觉反馈的推理,VILA使机器人能够根据环境的变化或技能的失败做出纠正或重新规划。
实验
文章在实验分为真实robot和仿真两部分,设计了一些较为真实、开放的任务来测试VILA以及baseline方法。
baselines
• 基于外部affordance模型+LLM框架:SayCan [3] 和 Grounded Decoding (GD) [4]
• CLIPort [5]:只在仿真实验中使用,本质是一个language-conditioned的learning agent
real world results
• 使用的机械臂是Franka Emika Panda (a 7-DoF arm) with a 1DoF parallel jaw gripper
• 相机视角 (VILA实际接受的图像) 所有任务一致:看向桌面的Logitech Brio color camera,区别于为了美观的录制视角
• 任务设置:16 long-horizon manipulation tasks,对每个任务评估10次,有场景布置,光照等的变化
• 考虑5个脚本skills:分别是pick up sth,place sth in/on sth,pour sth into/onto sth,open sth, close sth。简单任务用teleoperation,更复杂的使用kinematic teaching
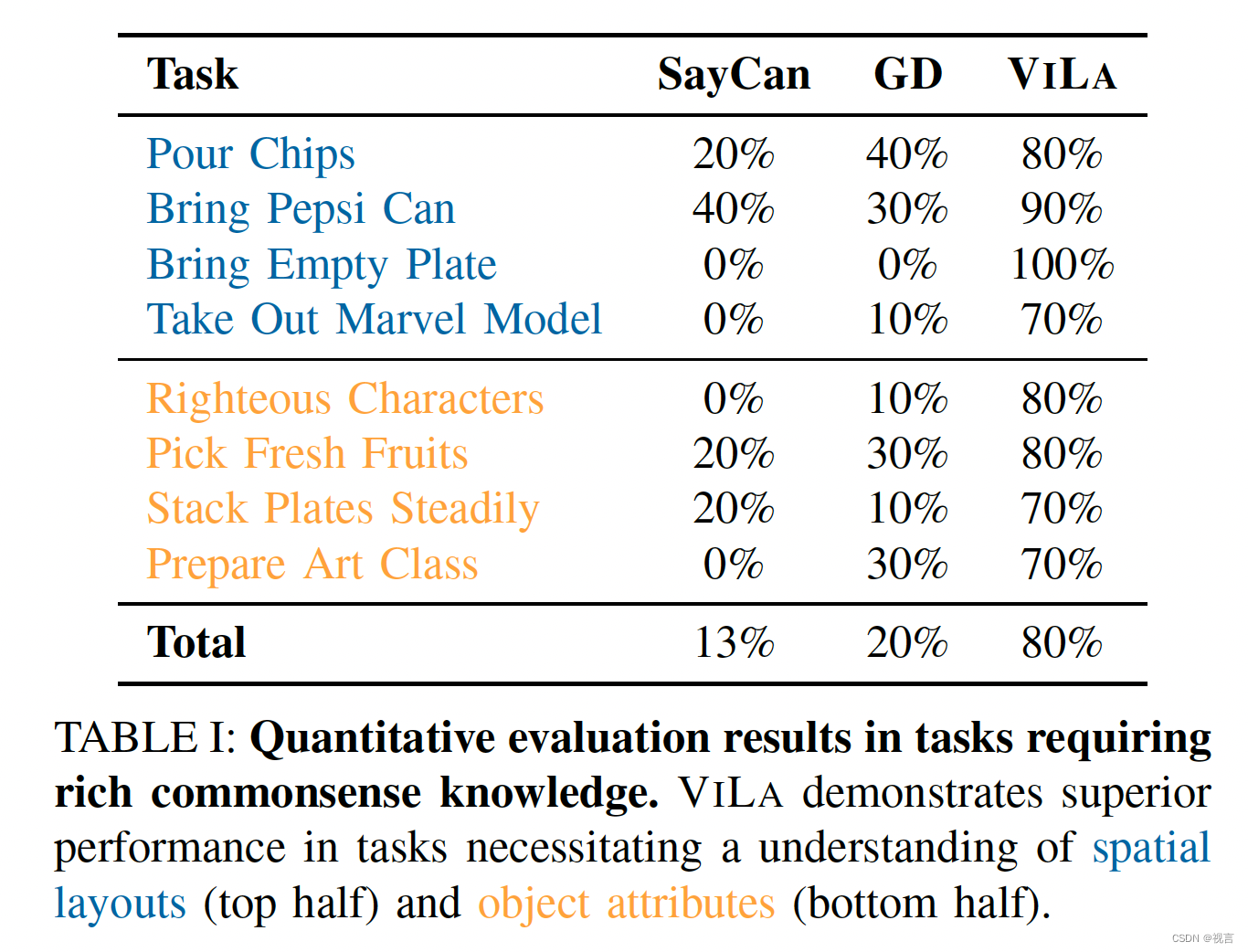
可以看到VILA的成功率远超SayCan和GD,尤其是在复杂任务中,如Take Out Marvel Model(杯子和可乐罐遮挡了漫威模型,需要先拿出来遮挡物)和Righteous Characters(从三个漫威模型中仅按颜色选择角色)。
文章还给出了一些代表示例:在“Bring Empty Plate”任务中,机器人必须先将苹果和香蕉从蓝色盘子中拿下来,然而,SayCan的第一步就是直接拿起盘子;在”Prepare Art Class“任务中,剪刀应该留在桌子上,而SayCan却错误地将剪刀放在了盒子里。

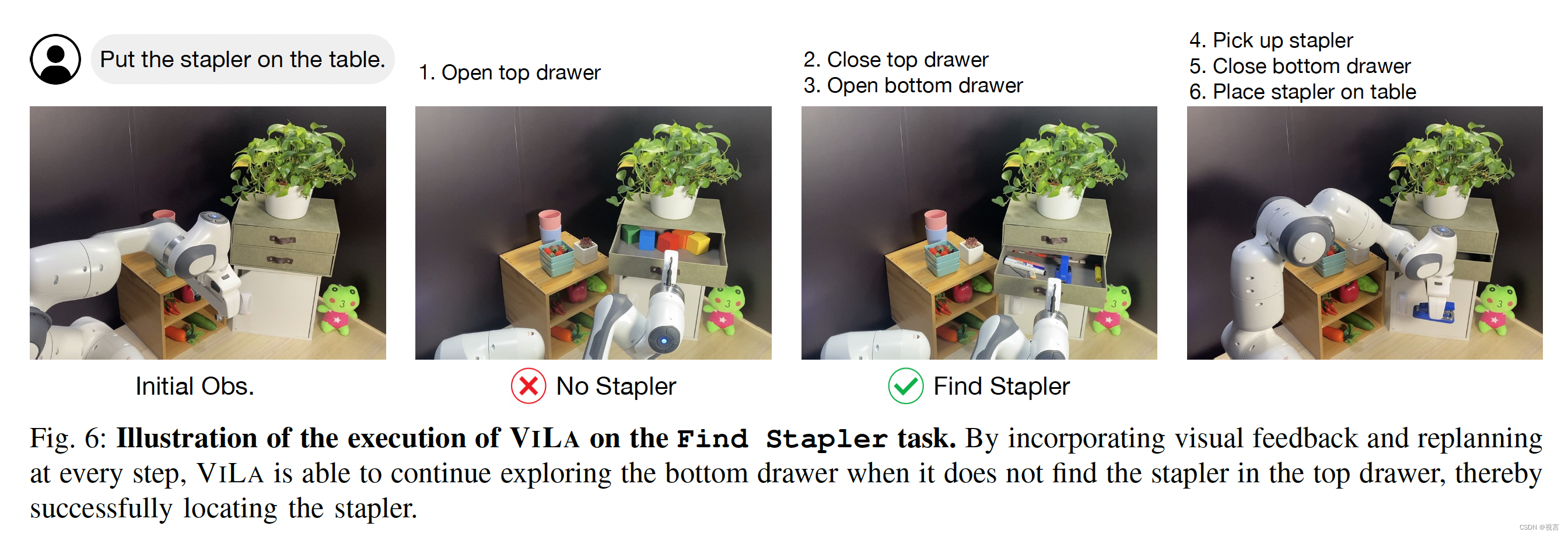
在“Find Stapler”任务中,VILA通过在每个步骤结合视觉反馈和重新规划,当VILA在顶部抽屉中没有找到缝合器时,它能够继续探索底部抽屉,从而成功地定位缝合器:
simulation results
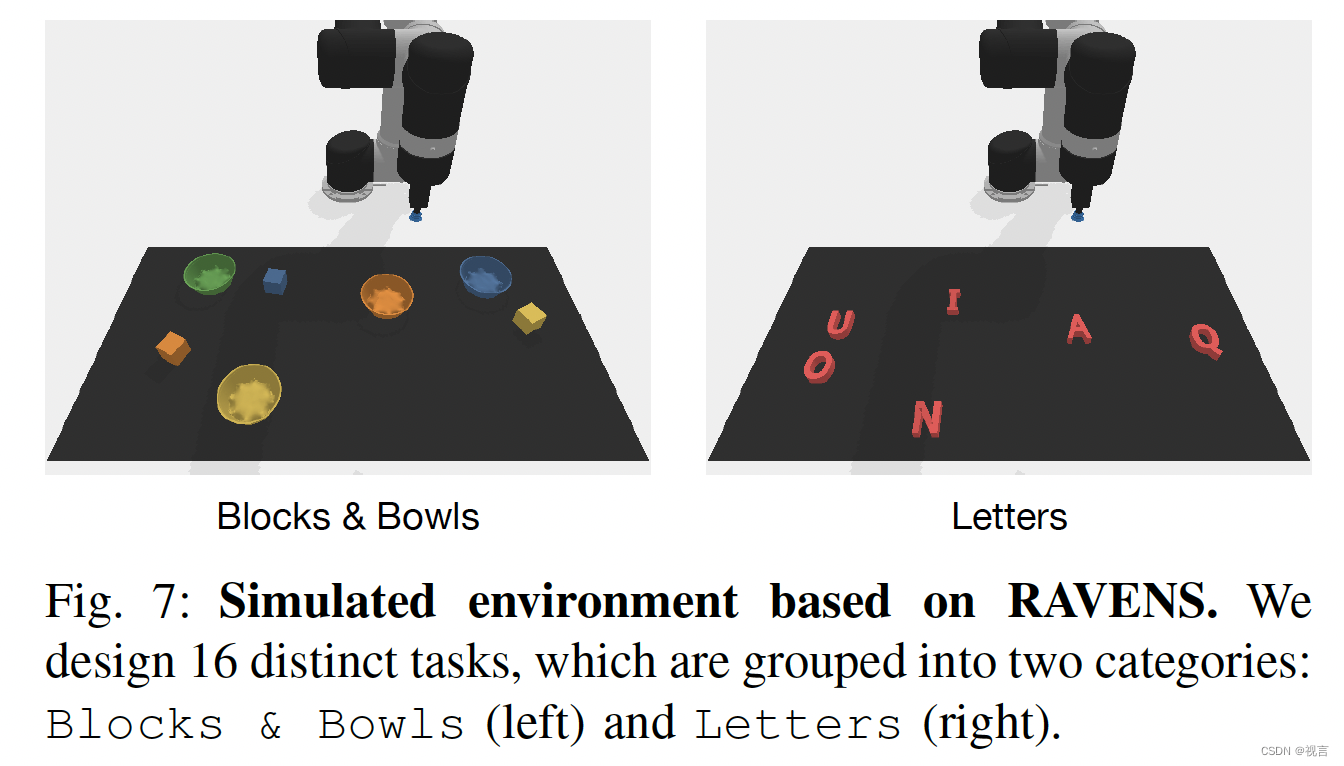
• 仿真部分文章采用RAVENS仿真环境,机械臂采用UR5 robot
• 考虑了16个任务,8个是操作方块和碗,8个是操作字母积木:
• 6 seen tasks: used for few-shot prompting or as training for supervised baselines
• 10 unseen tasks
每个任务评估20次
实验结果如下:
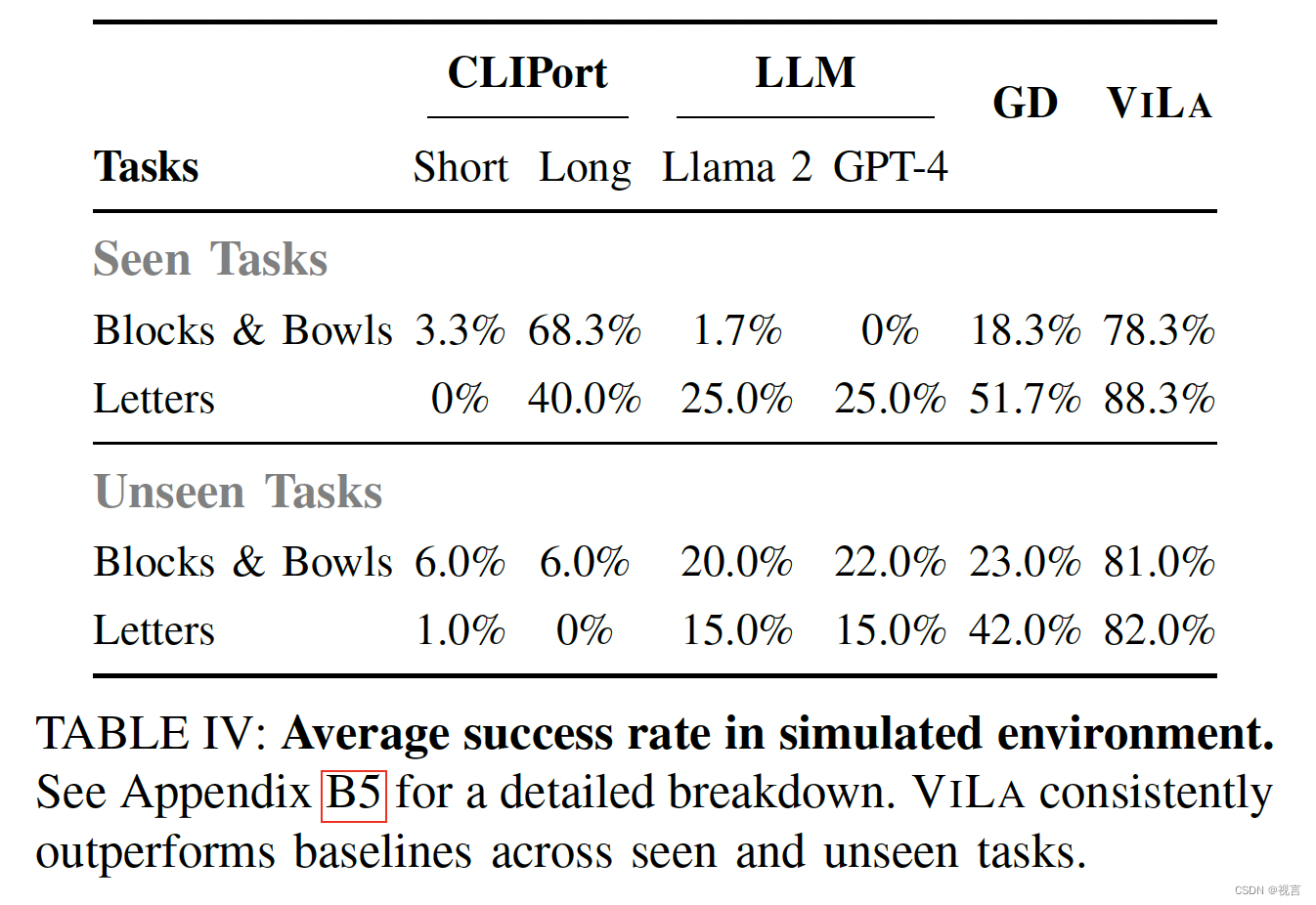
可以得到以下结论:
1. 相比基于LLM/VLM的方法,CLIPort-based方法在unseen tasks上的泛化能力有限,这说明了基于LLM/VLM的方法有着更好的zero-shot泛化能力
2. Llama 2和GPT-4在所有任务中性能接近,确保了GD(基于Llmma 2)和VILA(基于GPT-4V)之间的公平比较。虽然GD(利用外部affordance模型)超越了其他只使用LLM的规划方法(LLM Llama 2/GPT-4),但它明显落后于VILA。这表明VILA引入VLM来执行视觉和语言的joint reasoning对机器人任务的high-level planning更加有效。
总结
文章提出了VILA框架来做机械臂task planning,通过闭环视觉反馈的机制,可以根据实际任务进展进行replan,有着较好的鲁棒性,可以给相关研究者带来一些启发。VILA在真机上也达到了很好的效果,推进了这一领域的发展。另外,目前文章还有几处可能的局限和问题:
1. 结论解释欠缺:CLIPort-Short(只在单步指令上训练,如:拿起黄色方块)比 CLIPort-Long(在high-level指令上训练,如:把字母按字母序排列)效果差,文章似乎没有对这一点做解释。直观上来看如果是单步的语言指令作为输入,不需要对high-level指令进一步理解,应该效果是更好的,这和文章的结论相反;
2. 实时推理细节不详:把项目地址中的5倍速视频放慢后,每个plan之间的衔接几乎是瞬时的,按理说调用GPT-4V需要几秒钟的反应时间;
3. 感觉文章有些过于强调所提框架使用VLM 相比 LLM+affordance model框架的优势(joint reasoning),但这一点本质是VLM的优势,而不是文章的贡献;
adaptation问题:感觉文章给出的prompt有点像为考虑的16个真实世界任务所定制的,如果有另外的任务类型,可能需要对prompt进行调整。VILA还不算端到端的解决方案,需要预定义的脚本作为下层skill,这也是文章所提到的。
CoPA
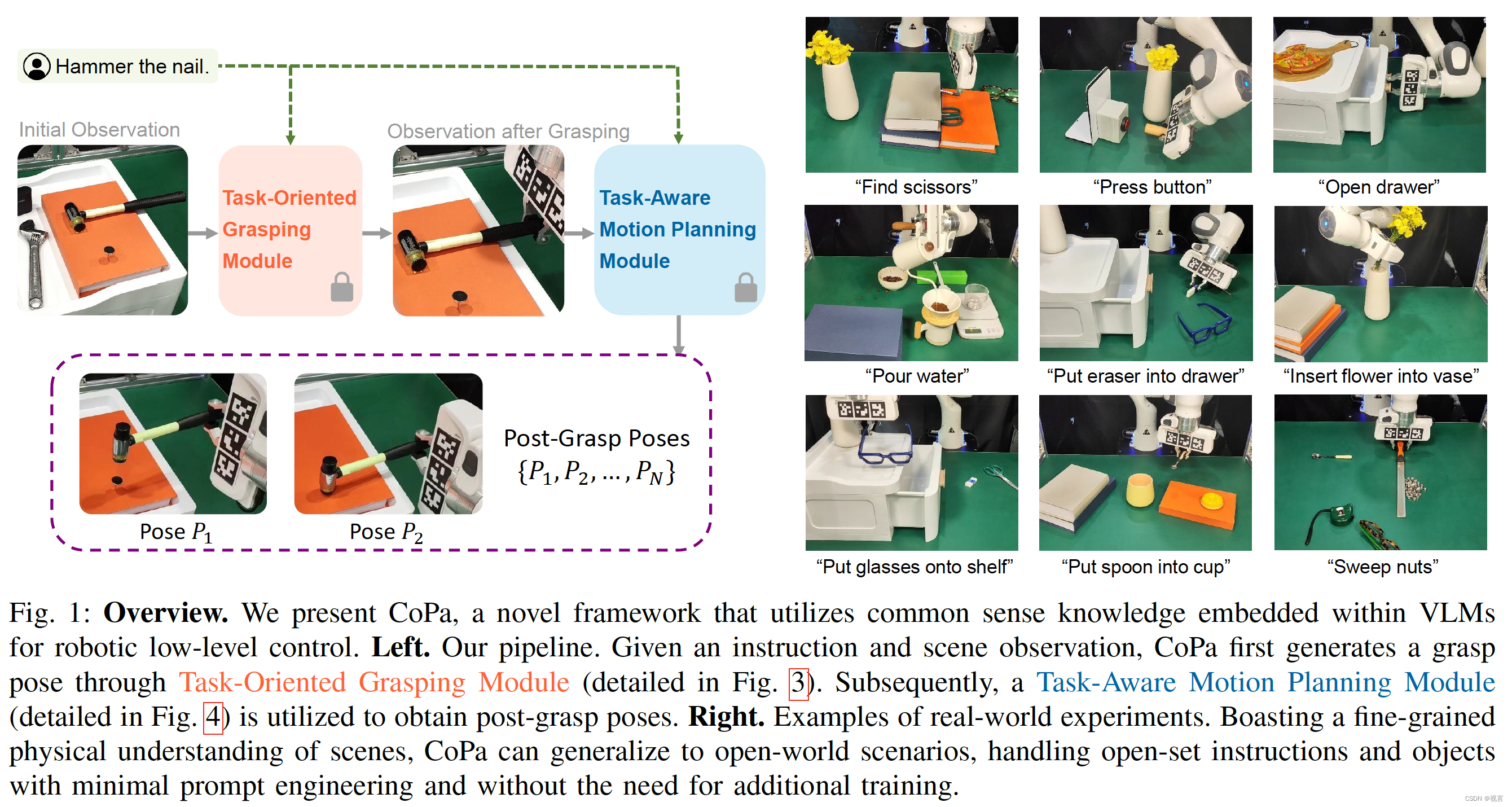
Method
问题形成
大多数的操作任务可以分解为初始的抓取和后续的移动来完成任务。基于此,我们的方法分成两个模块:task-oriented grasping 与task-aware motion planning。此外,假设机器人任务的执行本质上需要为机器人的末端执行器生成一系列目标姿势。相邻目标姿态之间的转换可以通过运动规划来实现。
给定语言指令 l l l和初始场景观察 O 0 O_0 O0 (RGB-D图像),我们在面向任务的抓取模块中的目标是为指定感兴趣的对象生成适当的抓取姿势。这个过程表示为 P 0 = f ( l , O ) P_0 = f(l, O) P0=f(l,O)。我们将机器人到达 P 0 P_0 P0 后的观测值记为 O 1 O_1 O1 。对于任务感知运动规划模块,我们的目标是推导出抓取后的姿势序列,表示为 g ( l , 0 1 ) → { P 1 , P 2 , . . . , P N } g(l, 0_1)→\{P_1, P_2, ..., P_N\} g(l,01)→{P1,P2,...,PN}
Task-Oriented Grasping
为了生成面向任务的抓取姿态,我们的方法首先使用抓取模型生成抓取姿态proposal,并通过我们的新型抓取部件定位模块过滤出最可行的抓取姿态proposal。
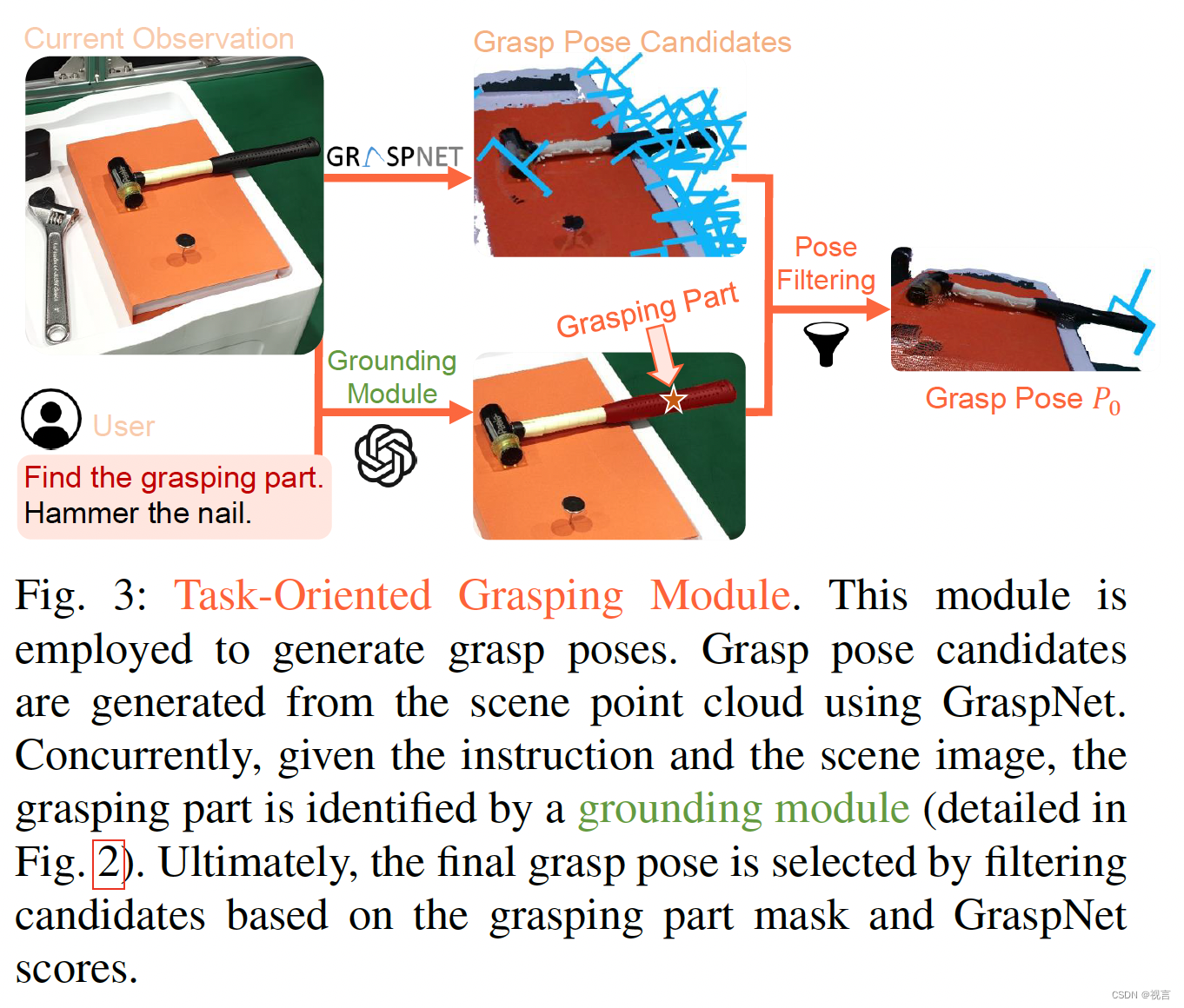
Grasp pose proposals:我们利用预先训练的抓取模型来生成抓取姿势proposals。为了实现这一点,我们首先通过将RGB-D图像反向投影到3D空间中将其转换为点云。然后将这些点云输入到GraspNet中,这是一个在包含超过10亿个抓取姿势的庞大数据集上训练的模型。GraspNet输出6自由度抓握候选对象,包括抓握点、宽度、高度、深度和“抓握得分”,这表明成功抓握的可能性。然而,考虑到graspnet在一个场景中产生所有潜在的抓取,我们有必要采用一种过滤机制,根据语言指令概述的特定任务选择最佳抓取。
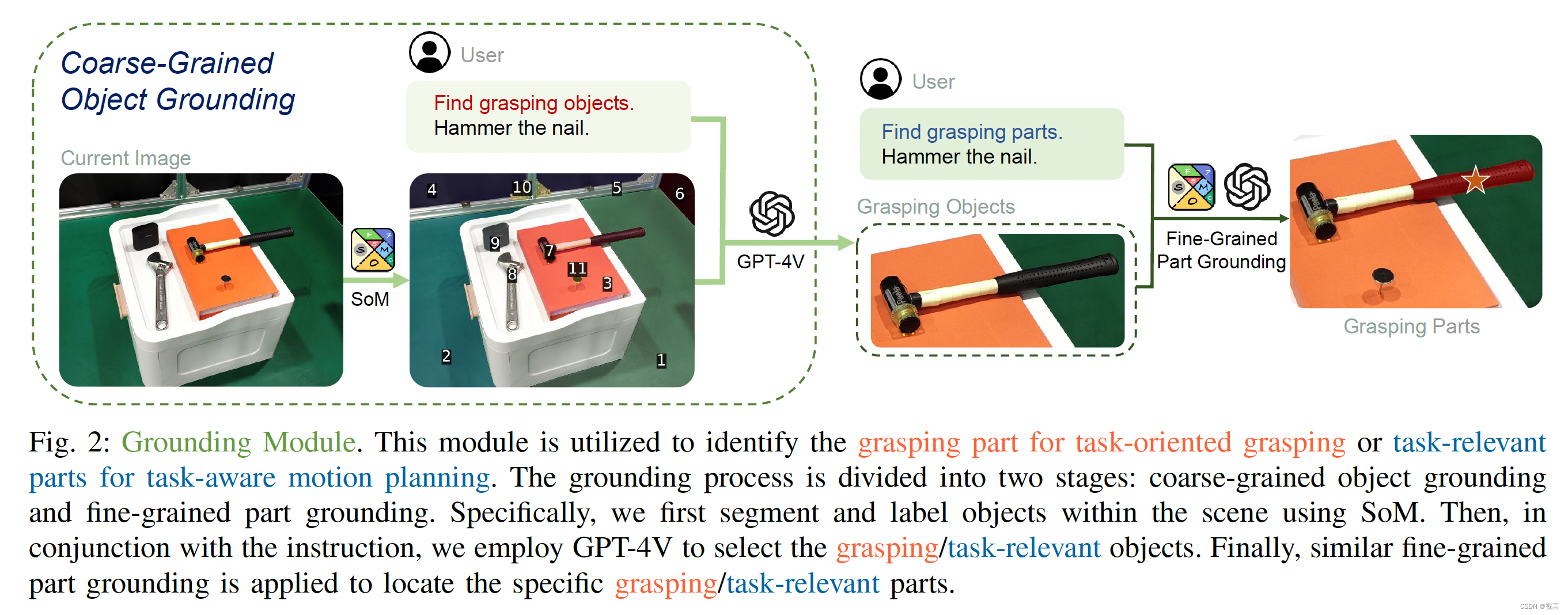
Grasping part grounding:人类根据预期用途掌握物体的特定部分。举个例子,当我们拿着刀准备切割时,我们会抓住刀柄而不是刀刃;同样,当我们拿起眼镜时,我们会抓住镜框而不是镜片。这个过程本质上代表了人类对常识知识的应用。为了模拟这种能力,我们利用视觉语言模型(VLMs),如GPT-4V,它结合了大量的常识知识,来识别物体的适当部分。
我们采用了一个两阶段的过程来将语言指令建立在对象的特定部分上:粗粒度的对象定位和细粒度的部件定位。整个接地过程如图2所示。在这两个阶段,我们采用了一种最新的视觉提示机制,即标记集(SoM)。SoM利用分割模型将图像划分为不同的区域,并为每个区域分配一个数字标记,从而显著提高VLMs的视觉基础能力。在粗粒度目标定位阶段,SoM在对象级别上用于检测和标记场景中的所有对象。在此之后,VLM的任务是在用户的指导下精确定位目标物体以抓取(例如,锤子)。然后从图像中裁剪选定的对象,在此基础上应用细粒度部件定位来确定要抓住的对象的特定部分(例如,锤子的手柄)。这种从粗到细的设计赋予方法细粒度的物理理解能力,使其能够在复杂的场景中进行泛化。最后,我们对候选抓取姿态进行过滤,将所有的抓取点投影到图像上,只保留那些在抓取部件掩码内的抓取点。从中选择GraspNet评分置信度最高的姿势作为最终抓取姿势 P 0 P_0 P0 执行。
Task-Aware Motion Planning
在成功执行任务导向抓取之后,现在我们的目标是获得一系列抓取后的姿势。我们将此步骤分为三个模块:与任务相关的部件定位,操作约束生成和目标姿态规划。整个过程如图4所示。
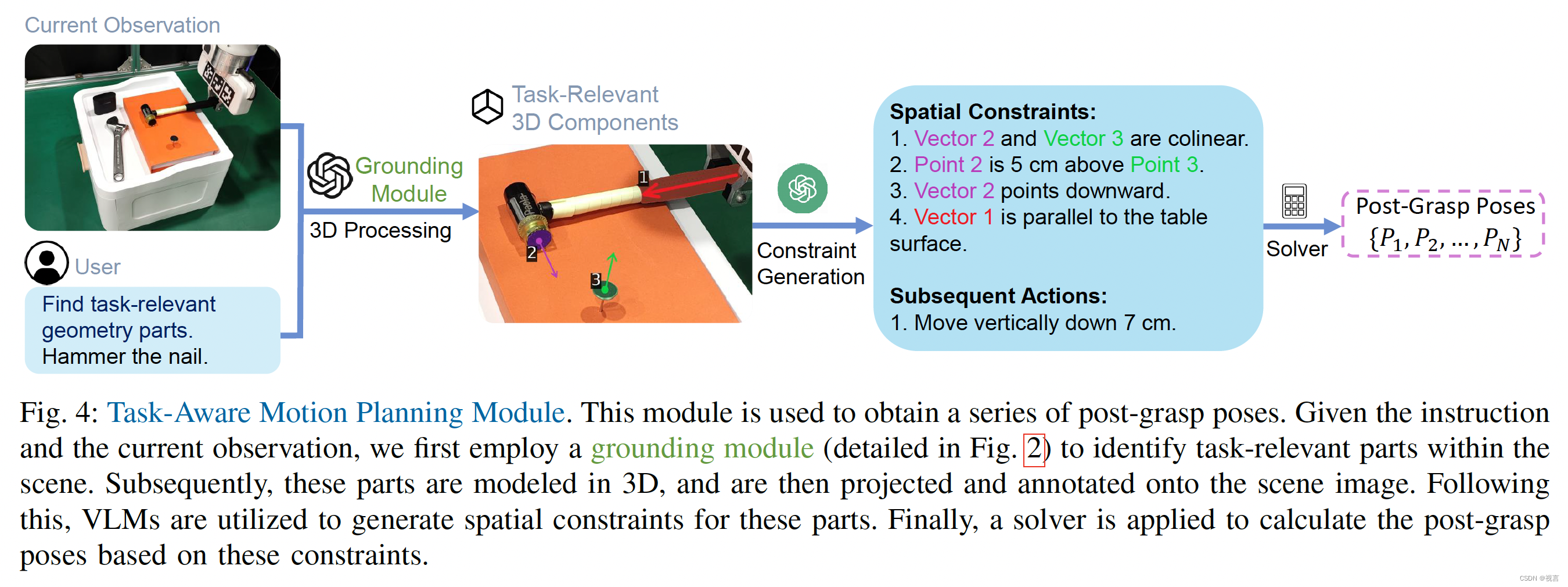
Task-Relevant Part Grounding:与之前的抓握部件定位模块类似,我们使用粗粒度的目标定位和细粒度的部件接地来定位任务相关部件。在这里,我们需要识别多个任务相关的部分(例如,锤子的击打面,手柄和钉子的表面)。此外,我们观察到机械臂上的数字标记可能会影响vlm的选择,因此我们过滤掉了机械臂上的掩模(详见附录)。
Manipulation Constraints Generation:在任务执行过程中,与任务相关的对象经常受到各种空间几何约束。例如,在给手机充电时,充电器的连接器必须与充电端口对齐;同样,当盖上瓶盖时,瓶盖必须位于瓶口的正上方。这些限制本质上需要常识知识,其中包括对物体物理特性的深刻理解。我们的目标是利用vlm为机器人操作的对象生成空间几何约束。我们首先将识别到的任务相关的部分建模为简单的几何元素。具体来说,我们表示细长的部分(例如:锤柄)作为向量,而其他部分被建模为表面。对于建模为矢量的部件,我们直接将其绘制在场景图像上;对于这些建模的表面,我们确定它们的中心点和法向量,然后将它们投影并标记在2d场景图像上。注释后的图像被用作vlm的输入,vlm被提示为这些几何元素生成空间约束。我们制作了一组空间约束的描述,例如两个向量之间的共线性,向量与表面之间的垂直度等等。我们指示vlm首先生成第一个目标姿势所需的约束,然后是达到该姿势后所需的后续动作。图4提供了该过程的说明性示例。该过程的实现细节在附录中提供。
Target Pose Planning:在得到操作约束条件后,推导出后抓取序列。这相当于计算一系列SE(3)矩阵,当应用于由机械臂操纵的物体部分时,这些部分满足空间几何约束。我们假设被操纵的物体部分和机器人末端执行器共同构成一个刚体。因此,这些计算的SE(3)变换可以直接应用于机器人末端执行器。我们将SE(3)矩阵的计算形式化为一个约束优化问题。具体来说,我们计算每个约束的损失,然后使用非线性约束求解器来找到最小化这些损失总和的SE(3)矩阵。以图4中的约束“向量2点向下”为例,损失可以定义为经过SE(3)变换后归一化的向量2与向量(0,0,−1)的负点积。在获得第一个目标姿态后,我们根据VLMs指定的动作求解后续姿态。具体来说,我们依次计算对应于每个后续动作的新姿态。例如,对于“垂直向下移动7厘米”的动作,只需从z轴上的当前姿态减去7厘米。这个过程产生了一套完整的 p o s t − g r a s p p o s e { P 1 , P 2 , . . . , P n } post− grasppose \{P_1, P_2,..., P_n\} post−grasppose{P1,P2,...,Pn}
实验
Fine-Grained Physical Understanding:copa能够利用嵌入在VLMs中的常识,在部件定位与限制生成阶段获得对目标物理属性更精细的理解。(Voxposer只将场景中的物体作为一个整体来感知。这种粗粒度级别的理解通常会导致需要精确操作的任务失败。例如,在将花插入花瓶任务中(如图5所示),CoPa抓住花的整个部分,而Voxposer抓住花瓣。在hammer钉子任务中(如图5中所示),CoPa将锤子定向到与钉子精确对齐,而voxposerv忽略了这种细粒度的物理约束,将锤子视为单个刚体。)
Simple Prompt Engineering:在我们的CoPa实验中,我们只使用了三个例子来帮助vlm理解它们的角色。相比之下,Voxposer依赖于包含85个手工制作示例的高度复杂的提示。它的推理能力主要来自于提供的提示,因此限制了它对新场景的推广能力。当我们试图简化Voxposer的提示,将每个模块的示例数减少到三个时,系统的性能急剧下降,导致所有评估任务几乎完全失败。
Handling Rotation DoF:机器人操作不仅需要末端执行器移动到指定位置,还需要精确控制其旋转。例如,在倒水任务中,必须将水壶旋转到一定角度以使水通过壶嘴流出。CoPa通过考虑场景中关键物体部件的空间几何约束来计算末端执行器的6自由度,从而实现对旋转自由度的精确和连续控制。相反,Voxposer试图让llm根据提示中的简单示例直接指定末端执行器的旋转自由度,导致输出旋转值从一组有限的离散选项中选择。这种方法经常忽略对象之间的动态交互和约束。例如,在将勺子放入杯子中(如图5右所示),CoPa将勺子旋转到垂直方向,而voxposer将机器人的末端执行器朝向杯子,导致勺子和杯子之间的碰撞。

消融实验
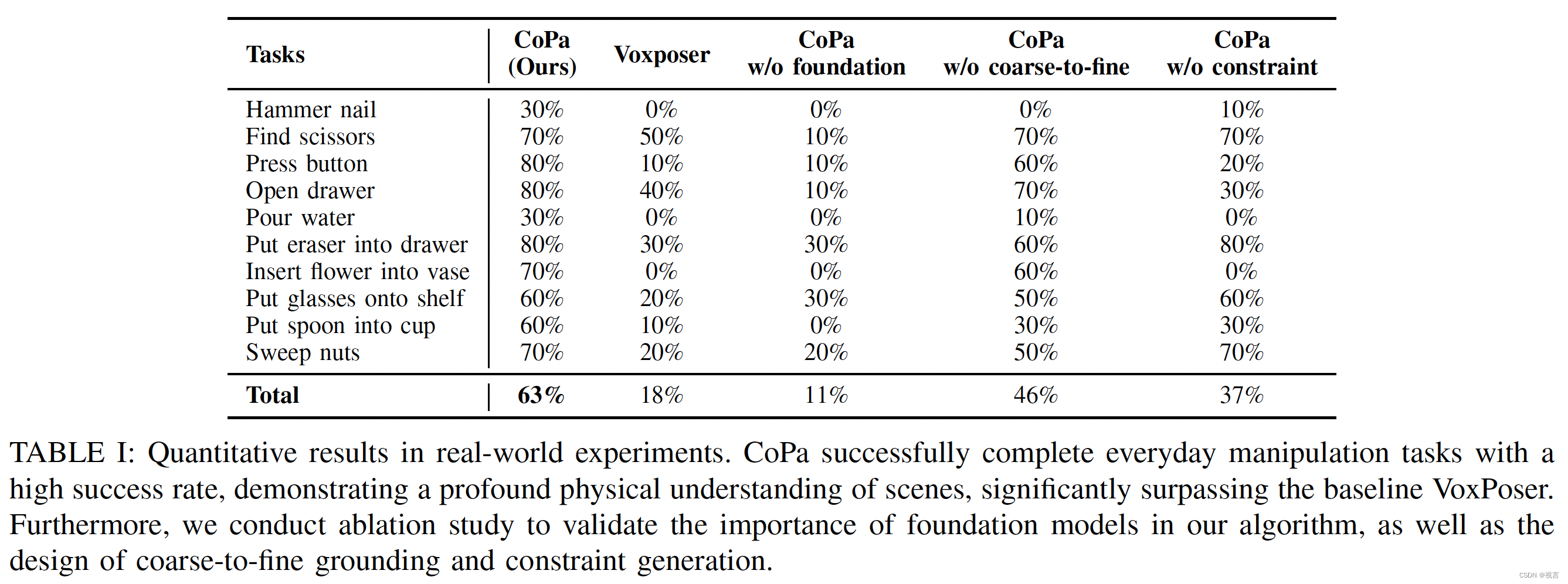
我们采用VILA作为高级规划方法,将高级指令分解为一系列低级控制任务。随后,使用CoPa依次执行这些低级控制任务。图6显示了一些环境的部署。实验表明,CoPa与高级规划方法相结合,可以有效地完成长期任务。

这篇关于大模型时代的具身智能系列专题(三)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









