本文主要是介绍Pytorch深度学习实践笔记8(b站刘二大人),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
🎬个人简介:一个全栈工程师的升级之路!
📋个人专栏:pytorch深度学习
🎀CSDN主页 发狂的小花
🌄人生秘诀:学习的本质就是极致重复!
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
目录
1 Pytorch 数据加载
2 Dataset和DataLoader
3 程序
1 Pytorch 数据加载
- epoch、Batch-size 、iteration

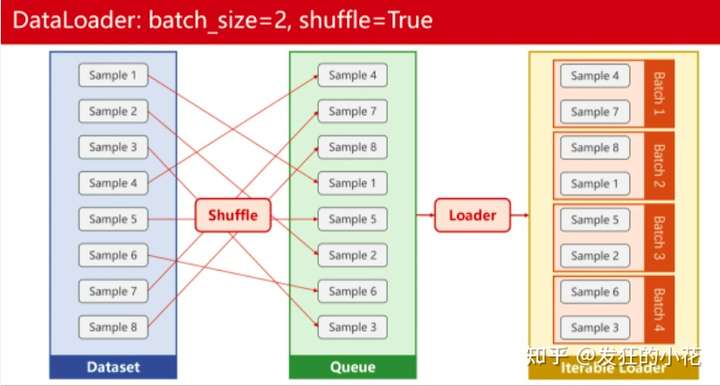
例如下图:
8个样本、shuffle是打乱样本的顺序,Batch-szie为2,iteration 就是 8 / 2 为4,epoch是训练集进行几个轮次的迭代。
2 Dataset和DataLoader

Dataset 是一个抽象类,使用时必须进行重写,from 在torch.utils.data Dataset
(1)重写时,需要根据数据来进行构造__init__(self,filepath)
(2)__getitem__(self,index)用来让数据可以进行索引操作
(3)__len__(self)用来获取数据集的大小
DataLoader 用来加载数据为mini-Batch ,支持Batch-size 的设置,shuffle支持数据的打乱顺序。
- 参数说明:
from torch.utils.data import DataLoadertest_load = DataLoader(dataset=test_data, batch_size=4 , shuffle= True, num_workers=0,drop_last=False)
batch_size=4表示每次取四个数据
shuffle= True表示开启数据集随机重排,即每次取完数据之后,打乱剩余数据的顺序,然后再进行下一次取
num_workers=0表示在主进程中加载数据而不使用任何额外的子进程,如果大于0,表示开启多个进程,进程越多,处理数据的速度越快,但是会使电脑性能下降,占用更多的内存
drop_last=False表示不丢弃最后一个批次,假设我数据集有10个数据,我的batch_size=3,即每次取三个数据,那么我最后一次只有一个数据能取,如果设置为true,则不丢弃这个包含1个数据的子集数据,反之则丢弃
- 数据转换为dataset形式,进行DataLoader的使用
x_data = torch.tensor([[1.0],[2.0],[3.0],[4.0],[5.0],[6.0],[7.0],[8.0],[9.0]])
y_data = torch.tensor([[2.0],[4.0],[6.0],[8.0],[10.0],[12.0],[14.0],[16.0],[18.0]])dataset = Data.TensorDataset(x_data,y_data)loader = Data.DataLoader( dataset=dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=0
)
pytorch中的DataLoader_pytorch dataloader-CSDN博客
3 程序
数据分为训练集和测试集:Adam 训练
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
from sklearn.model_selection import train_test_splitimport matplotlib.pyplot as plt# 读取原始数据,并划分训练集和测试集
raw_data = np.loadtxt('./dataset/diabetes.csv.gz', delimiter=',', dtype=np.float32)
X = raw_data[:, :-1]
Y = raw_data[:, [-1]]
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,Y,test_size=0.1)
Xtest = torch.from_numpy(Xtest)
Ytest = torch.from_numpy(Ytest)# 将训练数据集进行批量处理
# prepare datasetclass DiabetesDataset(Dataset):def __init__(self, data,label):self.len = data.shape[0] # shape(多少行,多少列)self.x_data = torch.from_numpy(data)self.y_data = torch.from_numpy(label)def __getitem__(self, index):return self.x_data[index], self.y_data[index]def __len__(self):return self.lentrain_dataset = DiabetesDataset(Xtrain,Ytrain)
train_loader = DataLoader(dataset=train_dataset, batch_size=16, shuffle=True, num_workers=0) #num_workers 多线程# design model using classclass Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.linear1 = torch.nn.Linear(8, 6)self.linear2 = torch.nn.Linear(6, 4)self.linear3 = torch.nn.Linear(4, 2)self.linear4 = torch.nn.Linear(2, 1)self.sigmoid = torch.nn.Sigmoid()def forward(self, x):x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x))x = self.sigmoid(self.linear4(x))return xmodel = Model()# construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)epoch_list = []
loss_list = []# training cycle forward, backward, update
def train(epoch):for i, data in enumerate(train_loader, 0):inputs, labels = datay_pred = model(inputs)loss = criterion(y_pred, labels)optimizer.zero_grad()loss.backward()optimizer.step()return loss.item()def test():with torch.no_grad():y_pred = model(Xtest)y_pred_label = torch.where(y_pred>=0.5,torch.tensor([1.0]),torch.tensor([0.0]))acc = torch.eq(y_pred_label, Ytest).sum().item() / Ytest.size(0)print("test acc:", acc)if __name__ == '__main__':for epoch in range(10000):loss_val = train(epoch)print("epoch: ",epoch," loss: ",loss_val)epoch_list.append(epoch)loss_list.append(loss_val)test()plt.plot(epoch_list,loss_list)plt.title("Adam")plt.xlabel("Epoch")plt.ylabel("Loss")plt.savefig("./data/pytorch7_1.png")


简单的程序
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader# prepare datasetclass DiabetesDataset(Dataset):def __init__(self, filepath):xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)self.len = xy.shape[0] # shape(多少行,多少列)self.x_data = torch.from_numpy(xy[:, :-1])self.y_data = torch.from_numpy(xy[:, [-1]])def __getitem__(self, index):return self.x_data[index], self.y_data[index]def __len__(self):return self.lendataset = DiabetesDataset('./dataset/diabetes.csv.gz')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0) #num_workers 多线程# design model using classclass Model(torch.nn.Module):def __init__(self):super(Model, self).__init__()self.linear1 = torch.nn.Linear(8, 6)self.linear2 = torch.nn.Linear(6, 4)self.linear3 = torch.nn.Linear(4, 1)self.sigmoid = torch.nn.Sigmoid()def forward(self, x):x = self.sigmoid(self.linear1(x))x = self.sigmoid(self.linear2(x))x = self.sigmoid(self.linear3(x))return xmodel = Model()# construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)# training cycle forward, backward, update
if __name__ == '__main__':for epoch in range(100):for i, data in enumerate(train_loader, 0): # train_loader 是先shuffle后mini_batchinputs, labels = datay_pred = model(inputs)loss = criterion(y_pred, labels)print(epoch, i, loss.item())optimizer.zero_grad()loss.backward()optimizer.step()🌈我的分享也就到此结束啦🌈
如果我的分享也能对你有帮助,那就太好了!
若有不足,还请大家多多指正,我们一起学习交流!
📢未来的富豪们:点赞👍→收藏⭐→关注🔍,如果能评论下就太惊喜了!
感谢大家的观看和支持!最后,☺祝愿大家每天有钱赚!!!欢迎关注、关注!
这篇关于Pytorch深度学习实践笔记8(b站刘二大人)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






