本文主要是介绍决策树与机器学习实战【代码为主】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 🛴🛴引言
- 🛴🛴决策树使用案例
- 🛴🛴`numpy`库生成模拟数据案例
- 🛴🛴决策树回归问题
- 🛴🛴决策树多分类问题
🛴🛴引言
决策树是一种经典的机器学习算法,在数据挖掘和预测分析中广泛应用。它是一种基于树结构进行决策的模型,可以用于分类和回归问题。
决策树的基本原理是通过对特征进行逐步划分,生成一棵树形结构,以实现对数据的分类或回归。从根节点开始,根据特征的不同取值,将数据划分到不同的子节点中。这个划分过程是基于一些衡量指标(例如信息增益、基尼系数等),目标是在每个节点上选择最佳的划分属性。
决策树的生成过程通常遵循下列步骤:
- 特征选择:从给定的特征集合中选择最佳的特征作为当前节点的划分属性。衡量指标常包括信息增益、基尼系数等。
- 树的构建:根据选择的划分属性,将数据集划分为多个子集,并生成相应的子节点。如果某个子集中的样本属于同一类别或达到终止条件,则将该节点标记为叶子节点。
- 递归过程:对于每个子节点,重复步骤1和步骤2,直到所有数据划分完毕或达到停止条件。
- 剪枝:为了避免过拟合,可以对生成的决策树进行剪枝。剪枝可以通过预剪枝和后剪枝两个方法实现,其中预剪枝是在生成树的过程中决定是否分裂节点,后剪枝是在生成树之后进行节点合并。
决策树的优点包括易于理解和解释、能够处理离散和连续特征、具有较好的可解释性等。此外,决策树还可以处理缺失值和异常值。

然而,决策树也有一些限制,包括容易过拟合、对特征空间划分较为敏感等。为了解决过拟合问题,可以通过剪枝、调整参数等方法进行优化。
在使用决策树时,需要注意以下几点:
- 特征选择:选择合适的特征作为划分属性对决策树的性能至关重要。
- 停止条件:设置递归停止的条件,防止过度拟合。常见的停止条件包括叶子节点中样本数量的最小值、树的最大深度、信息增益或基尼系数的阈值等。
- 数据预处理:决策树对数据的尺度不敏感,通常不需要进行归一化或标准化处理。
- 模型评估:决策树的常见评估指标包括准确率、精确率、召回率、F1分数等。
总之,决策树是一种直观且易于理解的机器学习模型,适用于一般的分类和回归问题。理解决策树的基本原理和构建过程,有助于更好地应用和解释该算法,为实际问题提供有效的预测和决策。

🛴🛴决策树使用案例
以下是一个使用真实数据集的示例代码,数据类型是csv,文件名称是data.csv:
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn import metrics
from matplotlib import pyplot as plt
from sklearn import tree# 读取数据集
data = pd.read_csv('data.csv')# 分割特征和目标变量
X = data.drop('target', axis=1)
y = data['target']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并拟合决策树模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)# 使用模型进行预测
y_pred = model.predict(X_test)# 计算模型准确率
accuracy = metrics.accuracy_score(y_test, y_pred)
print('模型准确率:', accuracy)# 可视化决策树
fig = plt.figure(figsize=(10, 10))
_ = tree.plot_tree(model, feature_names=X.columns, class_names=['0', '1'], filled=True)
plt.show()
导入必要的库:
pandas用于数据分析和处理。DecisionTreeClassifier用于构建决策树模型。train_test_split用于将数据集划分为训练集和测试集。metrics提供了一些评估模型性能的方法。tree用于可视化决策树。
读取数据集:
- 使用
read_csv()函数读取名为data.csv的数据文件。
分割特征和目标变量:
- 使用
drop()函数从数据中移除目标变量,得到特征数据集X。- 将目标变量保存在
y中。
划分训练集和测试集:
- 使用
train_test_split()函数将数据集划分为训练集和测试集,其中测试集占比为0.2。
创建并拟合决策树模型:
- 创建
DecisionTreeClassifier类的实例作为模型。- 使用
fit()方法拟合模型,传入训练集的特征数据和目标变量。
使用模型进行预测:
- 调用已训练的模型的
predict()方法,传入测试集的特征数据,得到预测结果y_pred。
计算模型准确率:
- 使用
accuracy_score()函数计算模型在测试集上的准确率,传入真实的目标变量y_test和预测值y_pred。
可视化决策树:
- 创建一个图形对象
fig。- 使用
tree.plot_tree()方法绘制决策树,参数包括模型、特征名称和类别名称。- 使用
plt.show()方法显示绘制好的图形。
请确保在运行代码之前,将数据集文件
data.csv放在与代码文件相同的目录下。这段代码展示了如何使用决策树模型对真实数据集进行分类预测,并可视化决策树结构。希望这可以帮助您更好地理解决策树模型的应用。如有任何疑问,请随时提问。
🛴🛴numpy库生成模拟数据案例
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
from sklearn import metrics
from sklearn import tree# 生成特征数据
X = np.random.rand(100, 3) # 生成100个样本,每个样本有3个特征# 生成目标变量
y = np.random.choice([0, 1], size=100) # 生成100个目标变量,取值为0或1# 创建数据框
data = pd.DataFrame(X, columns=['feature1', 'feature2', 'feature3'])
data['target'] = y# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建并拟合决策树模型
model = DecisionTreeClassifier()
model.fit(X_train, y_train)# 使用模型进行预测
y_pred = model.predict(X_test)# 计算模型准确率
accuracy = metrics.accuracy_score(y_test, y_pred)
print('模型准确率:', accuracy)# 可视化决策树
fig = plt.figure(figsize=(10, 10))
_ = tree.plot_tree(model, feature_names=data.columns[:-1], class_names=['0', '1'], filled=True)
plt.show()
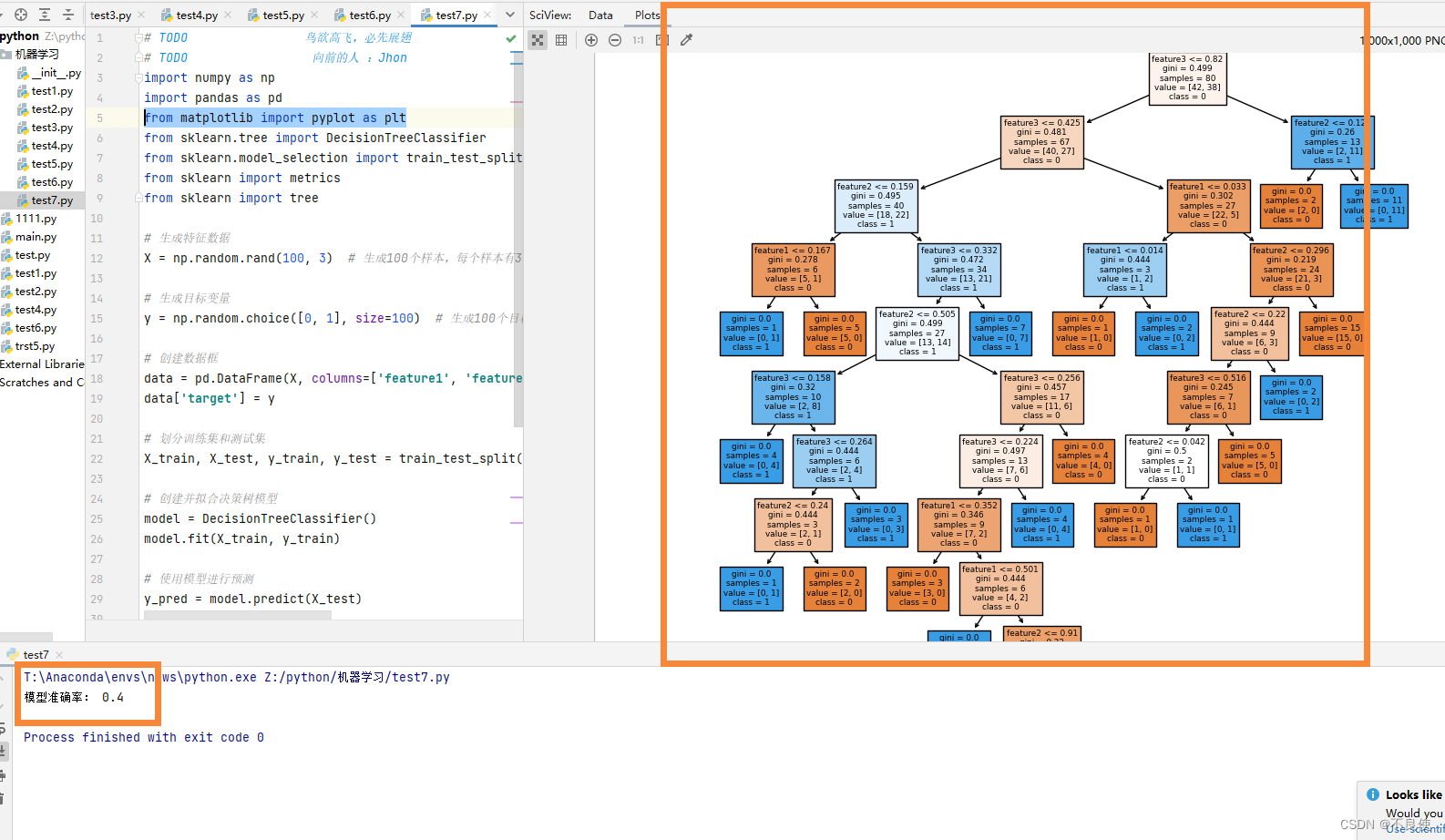


这段代码生成了具有3个特征和一个目标变量的模拟数据,并使用决策树模型进行学习和预测。你可以调整生成数据的方式,修改特征数量、样本数量,以及目标变量的取值等。
导入必要的库:
numpy用于生成随机数组作为特征数据。pandas用于创建和处理数据框。DecisionTreeClassifier用于创建决策树模型。train_test_split用于将数据集划分为训练集和测试集。metrics提供了一些评估模型性能的方法。tree用于可视化决策树。
生成特征数据:
- 使用
numpy.random.rand()函数生成一个形状为(100, 3)的随机数组,表示100个样本,每个样本有3个特征。
生成目标变量:
- 使用
numpy.random.choice()函数生成一个长度为100的随机数组,随机选择值为0或1作为目标变量。
创建数据框:
- 使用
pandas.DataFrame()函数将特征数据X和目标变量y组合成一个数据框,特征列的名称为feature1、feature2、feature3,目标变量列的名称为target。
划分训练集和测试集:
- 使用
train_test_split()函数将数据集划分为训练集和测试集,其中测试集占比为0.2。
创建并拟合决策树模型:
- 创建
DecisionTreeClassifier类的实例作为模型。- 使用
fit()方法拟合模型,传入训练集的特征数据X_train和目标变量y_train。
使用模型进行预测:
- 调用已训练的模型的
predict()方法,传入测试集的特征数据X_test,得到预测结果y_pred。
计算模型准确率:
- 使用
accuracy_score()函数计算模型在测试集上的准确率,传入真实目标变量y_test和预测值y_pred。
可视化决策树:
- 创建一个图形对象
fig。- 使用
tree.plot_tree()方法绘制决策树,参数包括模型、特征名称和类别名称。- 使用
plt.show()方法显示绘制好的图形。
这段代码演示了如何使用决策树模型对生成的模拟数据进行分类预测,并可视化生成的决策树结构
🛴🛴决策树回归问题
import numpy as np
import matplotlib.pyplot as plt
from sklearn.tree import DecisionTreeRegressor
from matplotlib import pyplot as plt# 生成特征数据
X = np.random.rand(100, 1) # 生成100个样本,每个样本有1个特征# 生成目标变量
y = np.sin(2 * np.pi * X) + np.random.normal(0, 0.1, size=(100, 1)) # 生成目标变量,使用正弦函数,并添加噪声# 创建并拟合决策树回归模型
model = DecisionTreeRegressor()
model.fit(X, y)# 预测新数据
new_data = np.linspace(0, 1, 100).reshape(-1, 1)
prediction = model.predict(new_data)# 可视化结果
plt.scatter(X, y, label='Actual')
plt.plot(new_data, prediction, color='red', label='Prediction')
plt.xlabel('X')
plt.ylabel('y')
plt.legend()
plt.show()
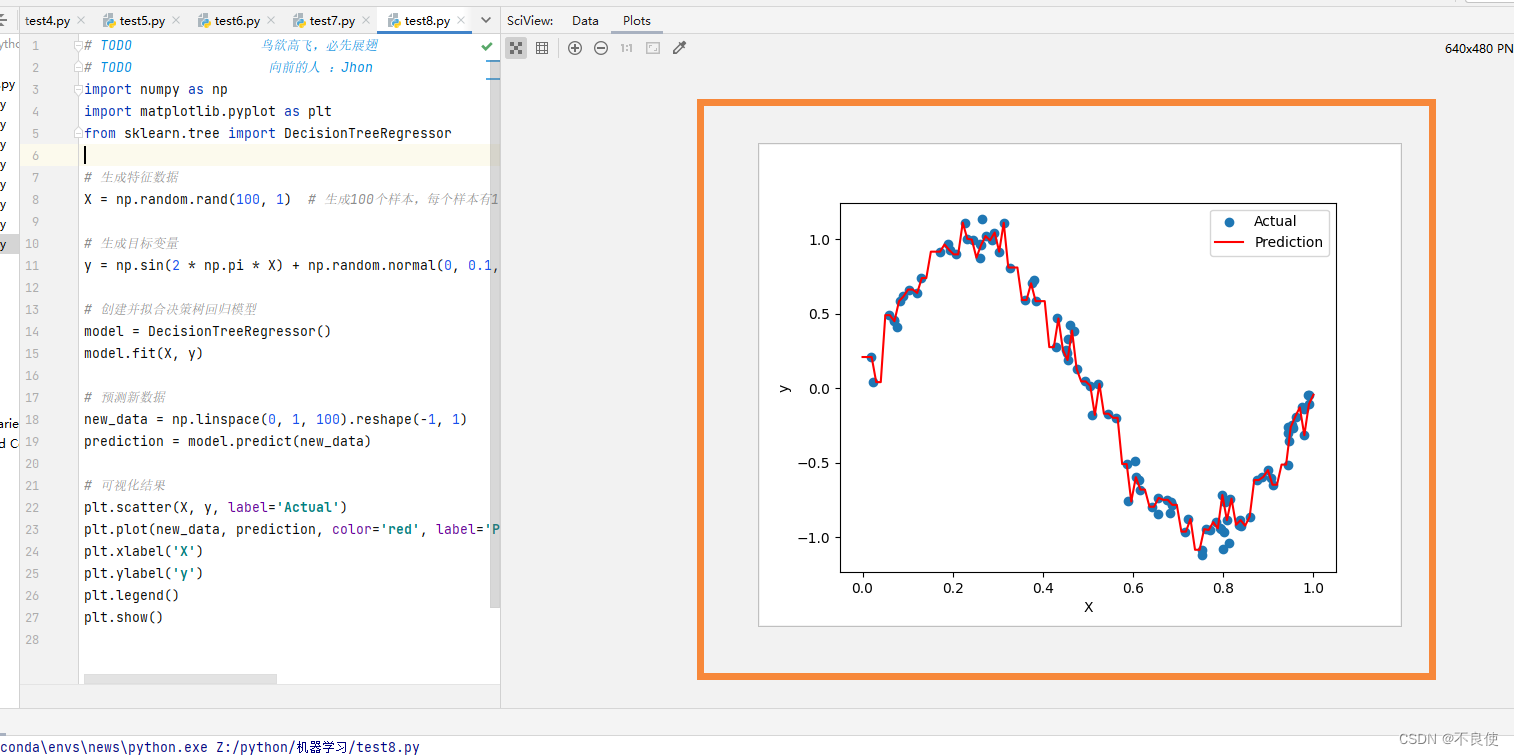

-
导入必要的库:
numpy用于生成随机数和数学计算。matplotlib.pyplot用于绘制图形。DecisionTreeRegressor用于创建决策树回归模型。
-
生成特征数据:
- 使用
numpy.random.rand()生成一个形状为(100, 1)的随机数组,表示100个样本,每个样本有1个特征。
- 使用
-
生成目标变量:
- 使用正弦函数
np.sin()生成目标变量y,并添加服从正态分布的噪声np.random.normal()。
- 使用正弦函数
4- 创建并拟合决策树回归模型:
- 创建
DecisionTreeRegressor类的实例作为回归模型。 - 使用
fit()方法拟合模型,传入特征数据X和目标变量y。
- 预测新数据:
- 生成一组新的特征数据
new_data,使用np.linspace()生成0到1之间的等差数列。 - 使用已训练的模型的
predict()方法对新数据进行回归预测,得到预测结果prediction。
- 生成一组新的特征数据
- 可视化结果:
- 使用
plt.scatter()绘制原始数据散点图。 - 使用
plt.plot()绘制预测结果曲线。 - 设置横轴和纵轴标签。
- 使用
plt.legend()显示图例。 - 使用
plt.show()显示图形。
- 使用
该代码演示了如何使用决策树回归模型来解决回归问题,并使用可视化方式展示预测结果。
🛴🛴决策树多分类问题
import numpy as np
from sklearn.tree import DecisionTreeClassifier
from matplotlib import pyplot as plt# 生成特征数据
X = np.random.rand(100, 2) # 生成100个样本,每个样本有2个特征# 生成目标变量
y = np.random.randint(0, 3, size=100) # 生成目标变量,取值为0、1、2# 创建并拟合决策树分类模型
model = DecisionTreeClassifier()
model.fit(X, y)# 预测新数据
new_data = np.random.rand(10, 2) # 生成10个新数据样本
prediction = model.predict(new_data)print('预测结果:', prediction)
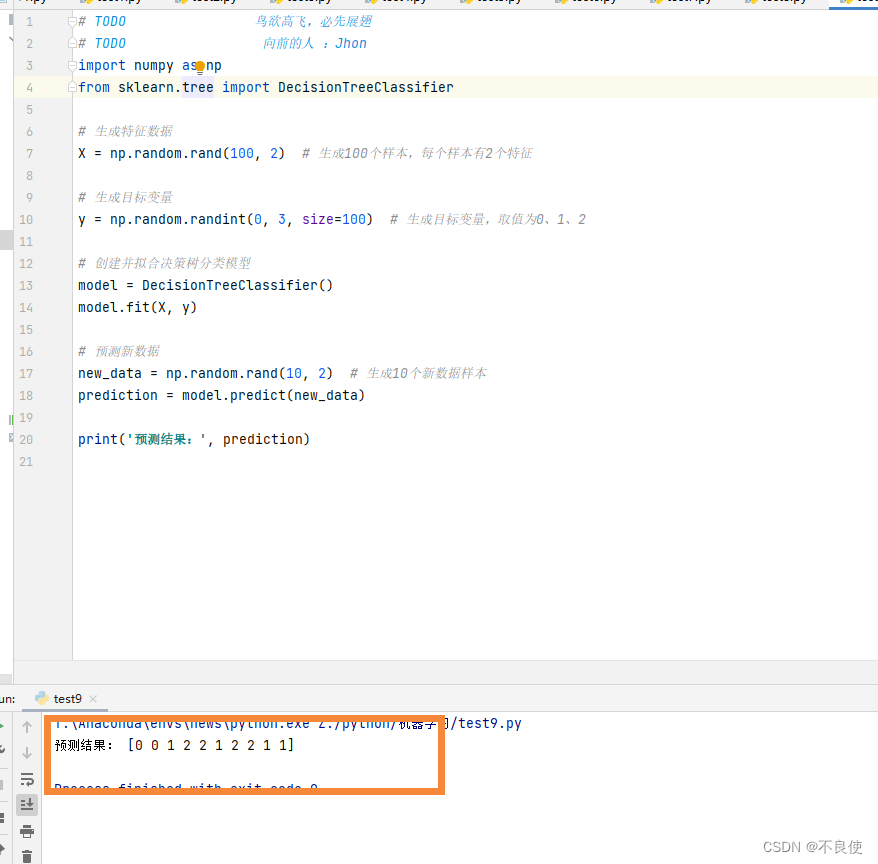
- 导入必要的库:
numpy用于生成随机数组。DecisionTreeClassifier用于创建决策树分类模型。
- 生成特征数据:
- 使用
numpy.random.rand()生成一个形状为(100, 2)的随机数组,表示有100个样本,每个样本有2个特征。
- 使用
- 生成目标变量:
- 使用
numpy.random.randint()生成一个长度为100的随机数组,取值范围为0到2,表示3个分类。
- 使用
- 创建并拟合决策树分类模型:
- 创建
DecisionTreeClassifier类的实例作为分类模型。 - 使用
fit()方法拟合模型,传入特征数据X和目标变量`
- 创建

这篇关于决策树与机器学习实战【代码为主】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





