本文主要是介绍论文《Adversarial Reading Networks For Machine Comprehension》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
综述:文中描述当前阅读理解任务中受限于监督学习设置,以及可用的数据集。这篇论文主要提出关于阅读理解任务中的对抗学习以及self-play.它用一个名为reader network来找到关于text和query的答案,还用一个名为narrator network的网络来混淆text的内容,来降低reader network网络成功的可能性。然后取得了较好的效果。
文章的贡献:
1,提出了一个新的基于对抗学习的机器阅读理解的范例。
2,这种方式克服了要求监督信息的要求,以及在query-answer中提供稳健的噪音。
3,可视化了模型在query推理过程中的注意力转变。
模型的主题流程如下:
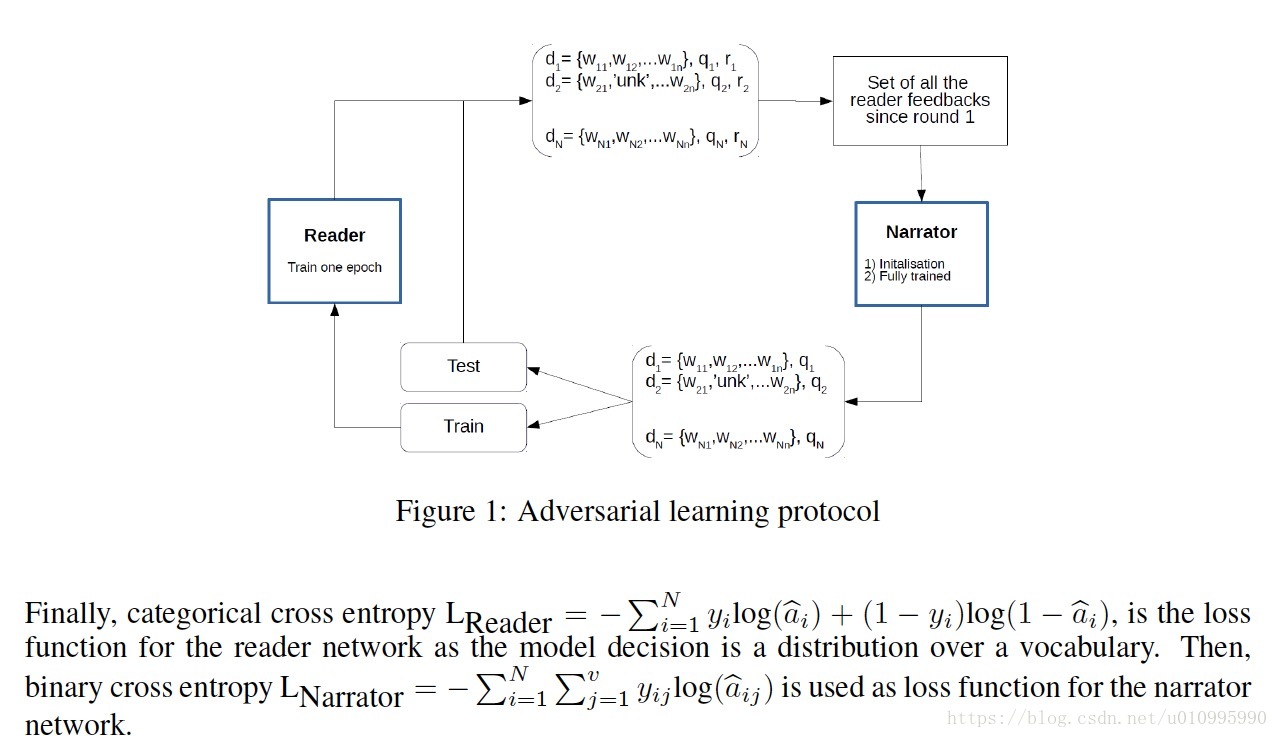
1,在每轮训练开始前,narrator 会混淆数据中的一些story中的单词(用UNK替代),固定这个混淆比例。ratio=corrupted_data/clear_data。记住训练集和测试集中都包含有混淆数据。
2,然后narrator从reader network获得一个反馈值,这个值得具体计算方式为,如果reader network在没混淆的d上回答正确,而在混淆的dobf上回答错误,那么r=1,否则为0。如图
这篇关于论文《Adversarial Reading Networks For Machine Comprehension》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


