本文主要是介绍DEM、DSM和DTM之间的区别及5米高程数据获取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在日常的学习工作中我们经常会遇到DEM、DSM和DTM等术语,它们的含义类似,甚至相互替换。那么它们之间有什么区别?这里我们对这些术语进行介绍。
-
DEM(数字高程模型,Digital Elevation Model):
-
定义:DEM是一个通用术语,用于描述地球表面的高程数据。它通常包括DSM和DTM。
-
内容:DEM可以包括地表上的所有物体,如建筑物、树木等(即DSM),也可以表示地表的裸露地形(即DTM)。
-
用途:DEM用于各种地理和工程应用,如地形分析、洪水模拟、土壤侵蚀研究等。
-
-
DSM(数字表面模型,Digital Surface Model):
-
定义:DSM表示地表及其上所有物体的高程数据。这包括自然特征(如树木、植被)和人为特征(如建筑物、桥梁)。
-
内容:DSM显示了从地面到地表物体的最高点的高度。
-
用途:DSM用于城市规划、通信线路分析(如无线电塔位置)、视线分析等。
-
-
DTM(数字地形模型,Digital Terrain Model):
-
定义:DTM表示裸露的地表地形数据,不包括任何地表物体。这通常需要从DEM或DSM中去除这些特征来获得。
-
内容:DTM显示了地面的实际形状,包括山丘、山谷、坡度等。
-
用途:DTM用于工程项目,如道路建设、土方量计算、洪水建模等。
-
关键区别总结
-
DEM是一个通用的高程数据术语,可以指DSM或DTM。
-
DSM包括地表及其上所有物体的高程数据。
-
DTM仅包括裸露的地表地形数据,不包括地表物体。
图示说明
假设有一片地面上有树木和建筑物:
-
DSM将显示地面到树顶和建筑物顶的高度。
-
DTM将仅显示没有树木和建筑物的地面的高度。
通过区分这些模型,用户可以选择最适合其特定应用需求的地形数据。
5米DEM高程数据的概念及获取
5米DEM是一种特定分辨率的数字高程模型,其中每个单元代表了地表上5米x5米的区域。它基于地表的高程数据,将地表划分为不同单元,每个单元记录了该区域内的平均高程。这种连续的表示方式可用于各种地理信息应用,从土地规划到环境模拟。
DEM构建方法:5米*5米规划格网法
5米DEM的构建方法通常涉及采用5米*5米的规划格网法。这意味着地表被划分为5米x5米的单元,每个单元内的高程数据被测量和记录,然后整合到一个数字数据集中。这种方法可确保DEM的均匀性和高程数据的连续性,使其适用于各种应用领域。
样例数据对比
不同精度地形数据的细节效果对比
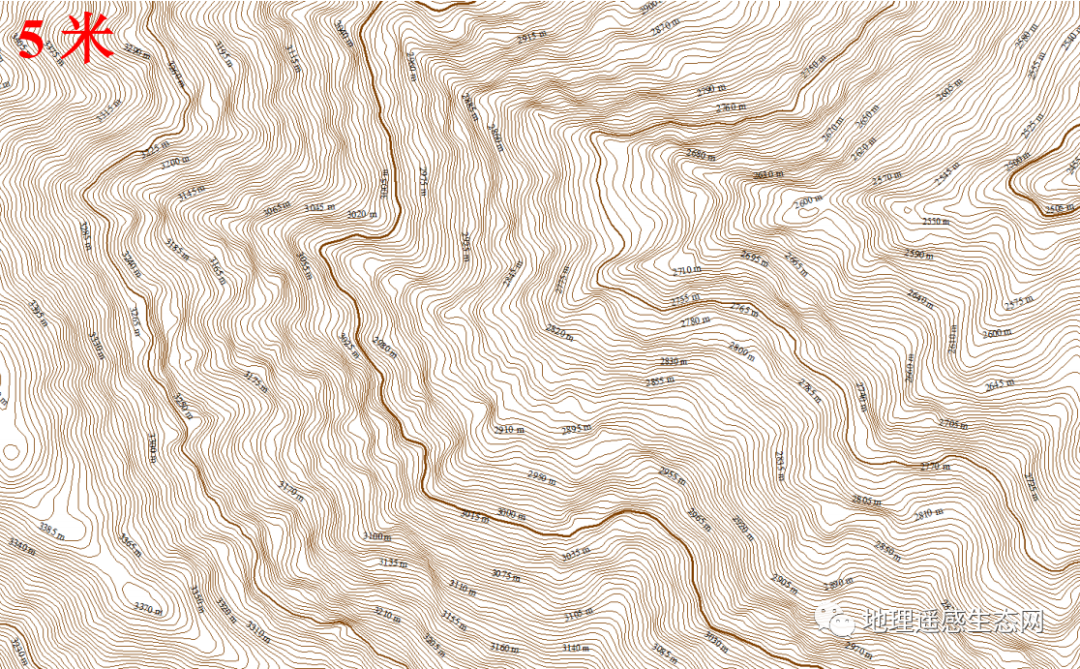
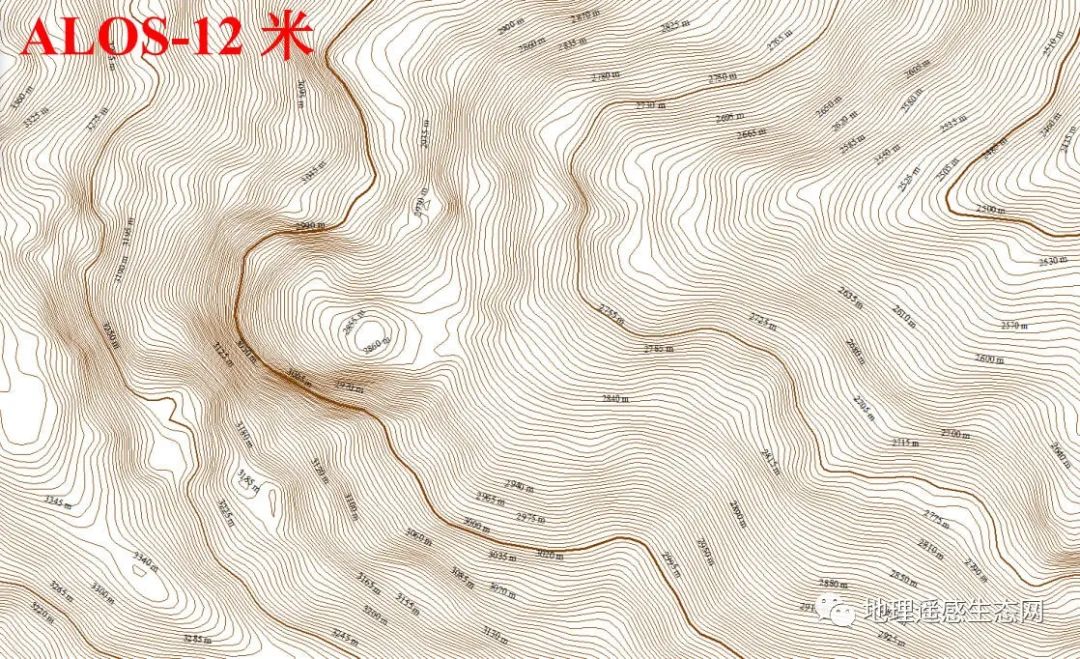
下图1为5米格网的DEM,图2为ALOS 12.5米分辨率的DEM,图3为ASTER GDEM V3 30米分辨率的DEM,图4为SRTM3 90米分辨率的DEM。

下图为 5 米 DEM 生成的等高线效果:
对比12.5mDEM生成的等高线:
对比30米DEM生成的等高线:
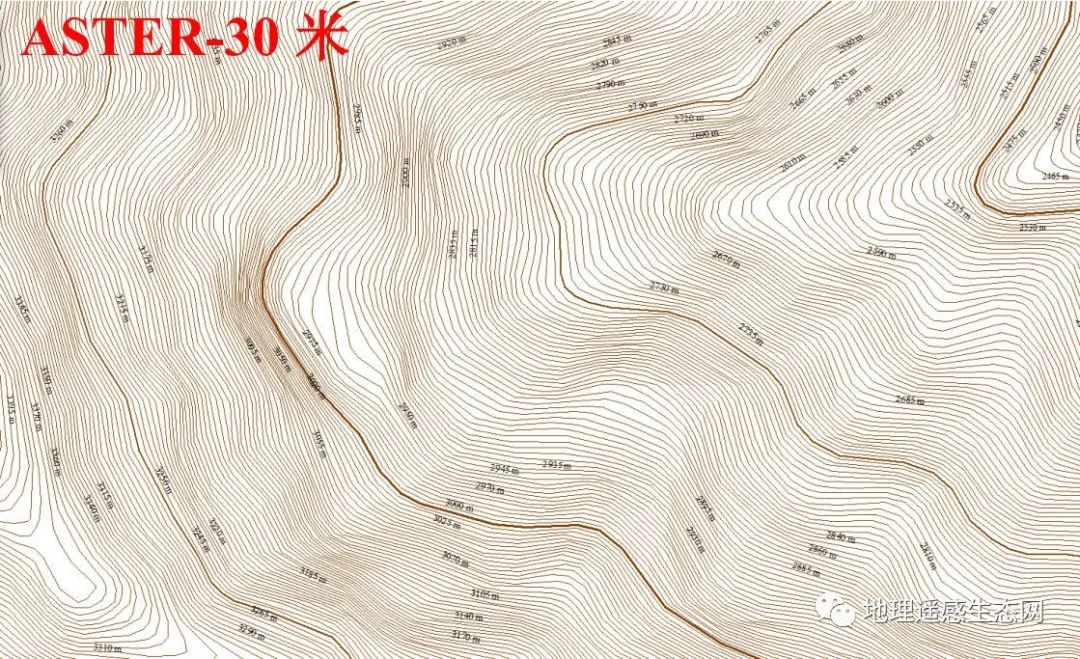
通过等高线对比,可以发现5米DEM数据生成的等高线细节远比12.5米和30米丰富,能够达到优于1:10000图的精度效果。
下图为某地城市区域地形晕渲效果。左为DSM效果,右为DEM效果。在DSM中,可以清晰的看出城市建筑,而在DEM中,仅能看到河流、地表等信息。


《5米高程数据获取》共享方法如下:
(1)人员,限定为关注小编的用户。
(2)各类项目(包括各类科研项目)申请本数据扔享受免费政策,但需向本号捐赠一定数量的硬盘才能获取。
(3)捐赠硬盘可免留言获取数据。
这篇关于DEM、DSM和DTM之间的区别及5米高程数据获取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







