本文主要是介绍X2Doris使用指南:界面化数据迁移工具 - 轻松实现整库迁移至Doris,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是X2Doris
X2Doris 是 SelectDB 团队开发的,专门用于将各种离线数据迁移到 Apache Doris 中的核心工具,该工具集 自动建 Doris 表 和 数据迁移 为一体,目前支持了 Apache Doris/Hive/Kudu/StarRocks 数据库往 Doris 或 SelectDB Cloud 迁移的工作,整个过程可视化的平台操作,非常简单易用。
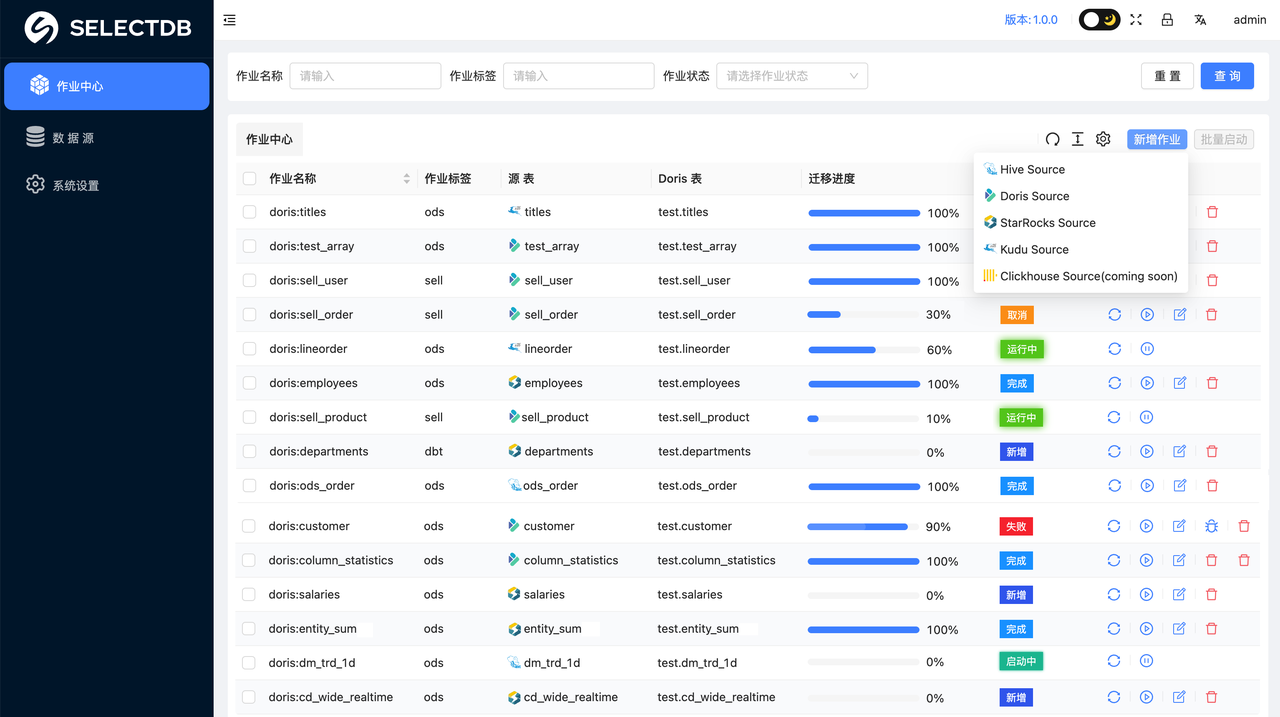
安装部署
参考官网文档:https://docs.selectdb.com/docs/ecosystem/x2doris/x2doris-deployment-guide
使用指南
参考官网文档:https://docs.selectdb.com/docs/ecosystem/x2doris/x2doris-use-guide
常见问题
推荐使用最新版本的X2Doris,目前仅支持jdk8
使用文档参考:https://docs.selectdb.com/docs/ecosystem/x2doris/x2doris-use-guide
1.0.4版本的X2Doris支持Doris、Hive、StarRocks、Kudu导入Doris/Selectdb/Cloud
目前Doris 2 Doris 不支持bitmap类型,1.2系列版本不支持DATETIMEV2、DATEV2,2.1.2版本及之后读DATETIMEV2、DATEV2也有问题,后续考虑支持
1、首先确认源端和目标端的fe 8030/9030 be 9060/8040是否通的,源端有读取权限,目标端都有建表,写入的权限
2、使用Hive 的时候要确认下基础环境
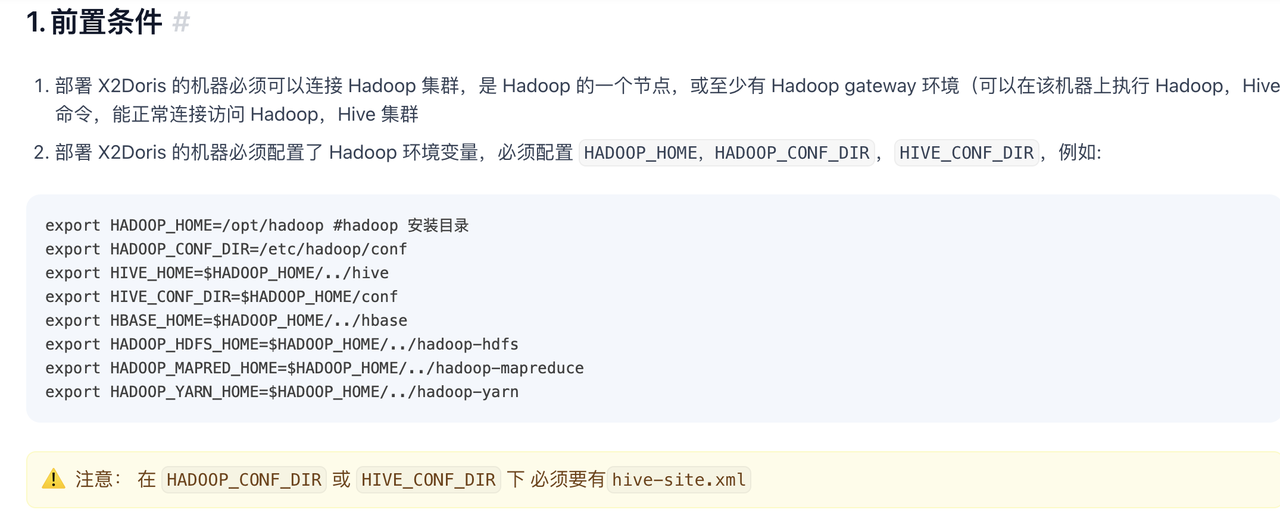
验证方法,在安装x2doris 的机器上执行hive的命令,看是否能连上hive,然后执行show databases;看下
获取 Hive 元数据方式,目前支持三种:JDBC,阿里云 DLF,Metastore,直接在conf里面的hive修改即可
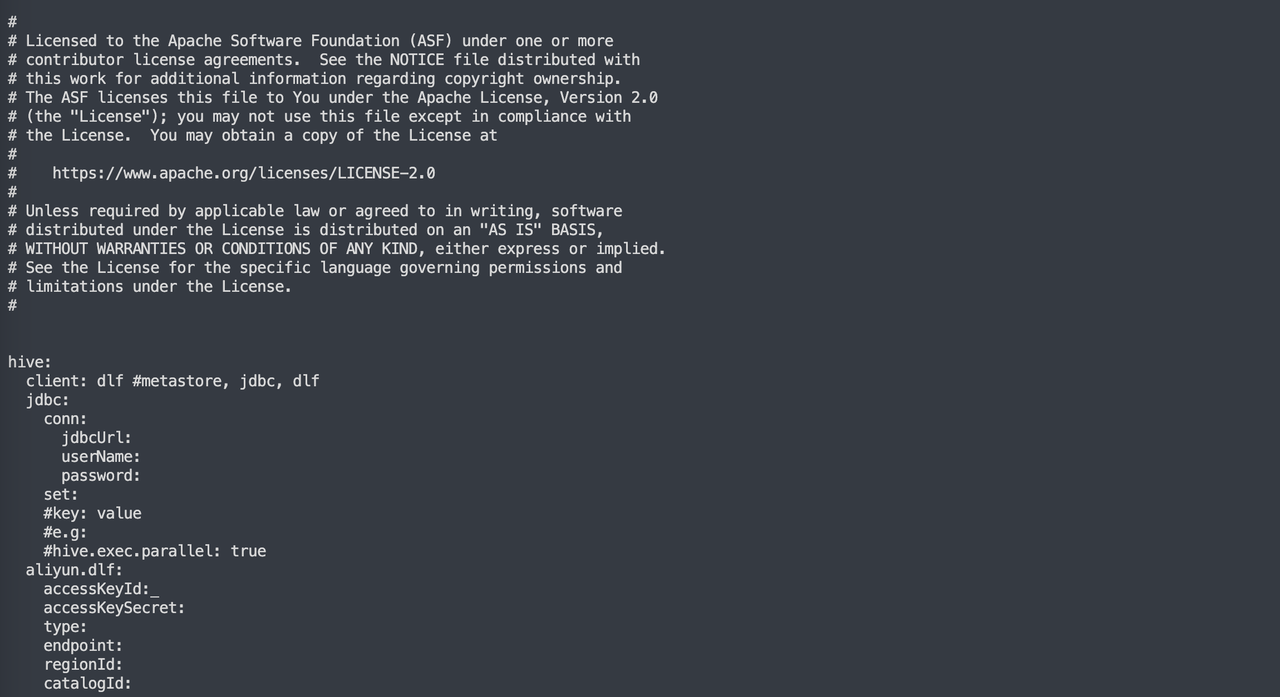
3、Hive的jdbc的连接形式在lib下面放连接的jar包
hive_jdbc.jar
hive_service.jar
报错截图
[图片]
4、hive2doris的时候建表能够成功,但是启动任务的时候,报错找不到库
确保spark的conf目录下有hive-site.xml
然后提交任务的时候加上 spark.sql.catalogImplementation=hive
报错截图

5、 get_next failed: out of sequence response: expected 4 but got 620757195
这是某个字段的值很大造成的,这个在205的版本后修了,新加了一个变量 max_msg_size_of_result_receiver 来控制返回结果的行数
6、前端报错提示:The number of parameters exceeded the maximum of 1000
在conf的application.yml里面 undertow: buffer-size: 1024的下面加一个这个max-parameters: 2000 重启下
7、ERROR BackendClient: Connect Doris BE{host='...**', port=9060} failed. **
使用telnet 确认 be的9060端口是否能够连通
8、Doris server Doris BE{host='...', port=9060} internal failed, status code [NOT_FOUND] error message is null
not found 这个就是读取的时候发现读取的tablet在这个be上面找不到副本了,副本迁移导致的问题。迁移过程不要有导入任务
9、The status of open scanner result from Doris BE{host=‘127.1.1.1’, port=9060} is ‘INVALID_ARGUMENT’, error message is:[(127.1.1.1)[INVALID_ARGUMENT]Unknown primitive type(17)]
Doris 不支持 thrift 读取 bitmap类型,暂时无解
10、如果导入少数据,yarn模式下可以设置下面的saprk参数(根据自己的情况来)
可以设置spark.executor.heartbeatInterval=300s
spark.network.timeout=320s
spark.driver.memory=4g
spark.executor.memory=6g
11、查询hive报错 Invalid method name: ‘get_table_req’
spark与hive的版本不兼容造成的,可能是由于hive的版本较低,启动任务的时候可指定下面两个参数(以2.1.1为例)
spark.sql.hive.metastore.version=2.1.1
spark.sql.hive.metastore.jars=/path/hive/lib/* (指定路径)
或者把这两个配置写到 spark/conf/spark-defaults.conf 文件里
12、X2Doris提交任务后,Spark报错数据库不存在: NoSuchDatabaseException: Database ‘dw_srclog’ not found
hive里conf的下hive-site.xml文件 拷贝到spark的conf
也可能是其他版本集成版本的hive版本没有匹配,比如星环的,华为云的等等
这篇关于X2Doris使用指南:界面化数据迁移工具 - 轻松实现整库迁移至Doris的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




