本文主要是介绍从用法到源码再到应用场景:全方位了解CompletableFuture及其线程池,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 文章导图
- 什么是CompletableFuture
- CompletableFuture用法总结
- API总结
- 为什么使用CompletableFuture
- 场景总结
- CompletableFuture默认线程池解析:ForkJoinPool or ThreadPerTaskExecutor?
- ForkJoinPool 线程池
- ThreadPerTaskExecutor线程池
- CompletableFuture默认线程池源码分析
- 源码流程图
- 总结
- 注意点
- 设置 ForkJoinPool 并行级别
- 示例
- 补充
- 项目中使用CompletableFuture默认线程池的坑?
- 案例分析
- 如何解决?
- 线程池核心线程数和最大线程数设置指南
- 线程池参数介绍
- 线程数设置考虑因素
- CPU密集型任务的线程数设置
- IO密集型任务的线程数设置
- 实际应用中的线程数计算
- 生产环境中的线程数设置
- 线程池参数设置建议
- 注意事项
线程池系列文章可参考下表,目前已更新3篇,还剩1篇TODO…
| 线程池系列: | 文章 |
|---|---|
| Java基础线程池 | TODO… |
| CompletableFuture线程池 | 从用法到源码再到应用场景:全方位了解CompletableFuture及其线程池 |
| SpringBoot默认线程池(@Async和ThreadPoolTaskExecutor) | 探秘SpringBoot默认线程池:了解其运行原理与工作方式(@Async和ThreadPoolTaskExecutor) |
| SpringBoot默认线程池和内置Tomcat线程池 | 你是否傻傻分不清SpringBoot默认线程池和内置Tomcat线程池? |
文章导图
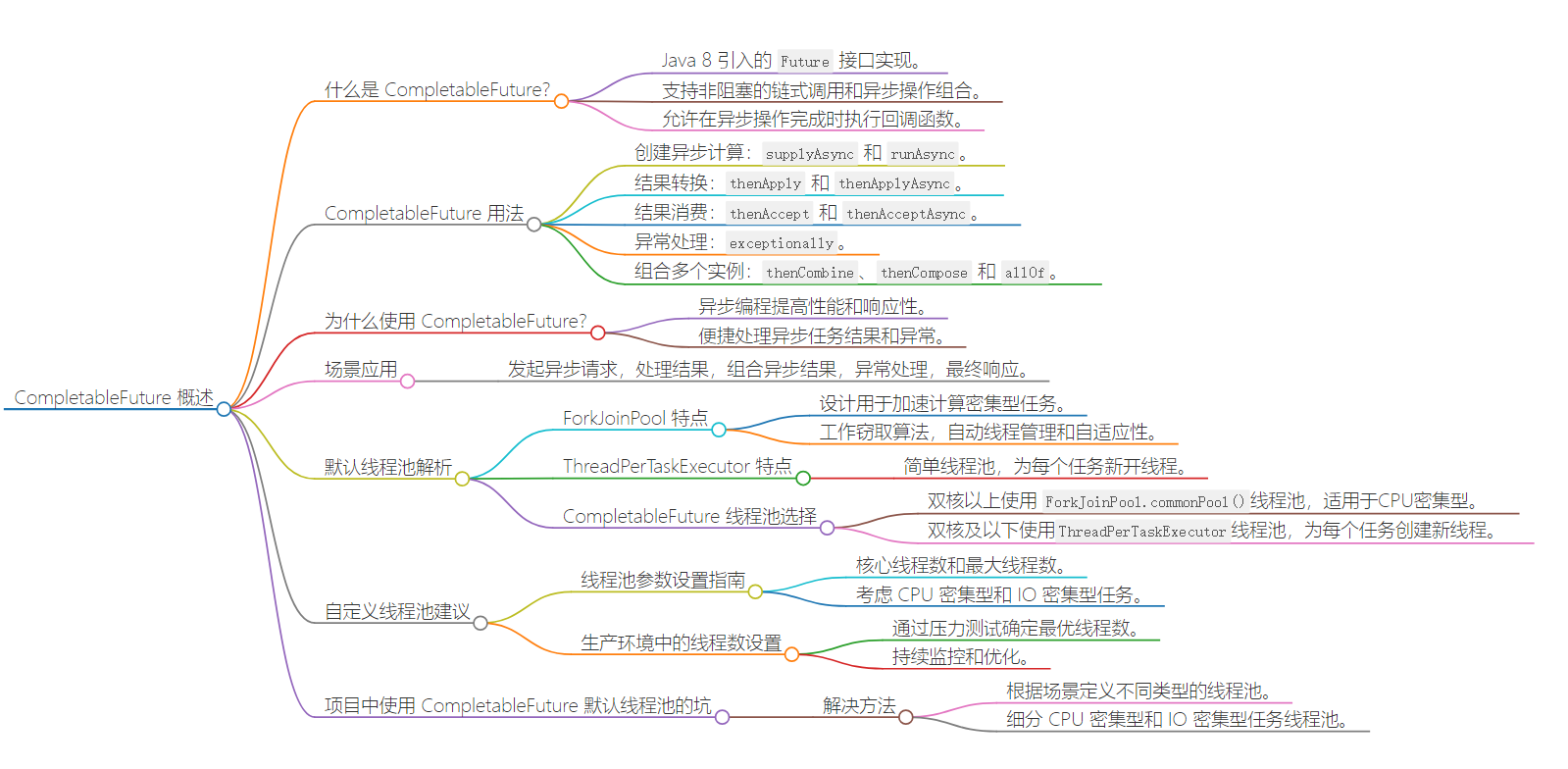
什么是CompletableFuture
JDK中的Future是什么可能大家都知道了,那CompletableFuture呢?从英文看单词CompletableFuture猜测应该也是和Future有关,具体如下:
CompletableFuture是Java 8引入的一个重要特性,它是Future接口的一个实现,但与传统的Future相比,提供了更强大、灵活的异步编程模型。CompletableFuture支持非阻塞的链式调用、组合多个异步操作以及更优雅地处理异步计算的结果或异常。- 它允许你在异步操作完成时执行回调函数,且这些操作可以并行或串行执行,极大地提高了程序的并发能力和响应速度。
CompletableFuture用法总结
使用CompletableFuture需要掌握其核心方法,以下是一些常用方法的总结:
// 创建一个完成的CompletableFuture
CompletableFuture<String> completableFuture = CompletableFuture.completedFuture("Hello");// 运行异步计算
CompletableFuture<Void> runAsyncFuture = CompletableFuture.runAsync(() -> {// 异步执行的代码
});// 异步执行,并返回结果
CompletableFuture<String> supplyAsyncFuture = CompletableFuture.supplyAsync(() -> {return "Result";
});// 转换和计算结果
CompletableFuture<String> transformFuture = supplyAsyncFuture.thenApply(result -> {return result.toUpperCase();
});// 组合两个独立的CompletableFuture
CompletableFuture<String> combinedFuture = transformFuture.thenCombine(CompletableFuture.completedFuture(" World"),(s1, s2) -> s1 + s2
);// 当CompletableFuture完成时执行某操作
supplyAsyncFuture.thenAccept(result -> {System.out.println("Result: " + result);
});// 异常处理
CompletableFuture<String> exceptionFuture = supplyAsyncFuture.exceptionally(ex -> {return "Error occurred: " + ex.getMessage();
});
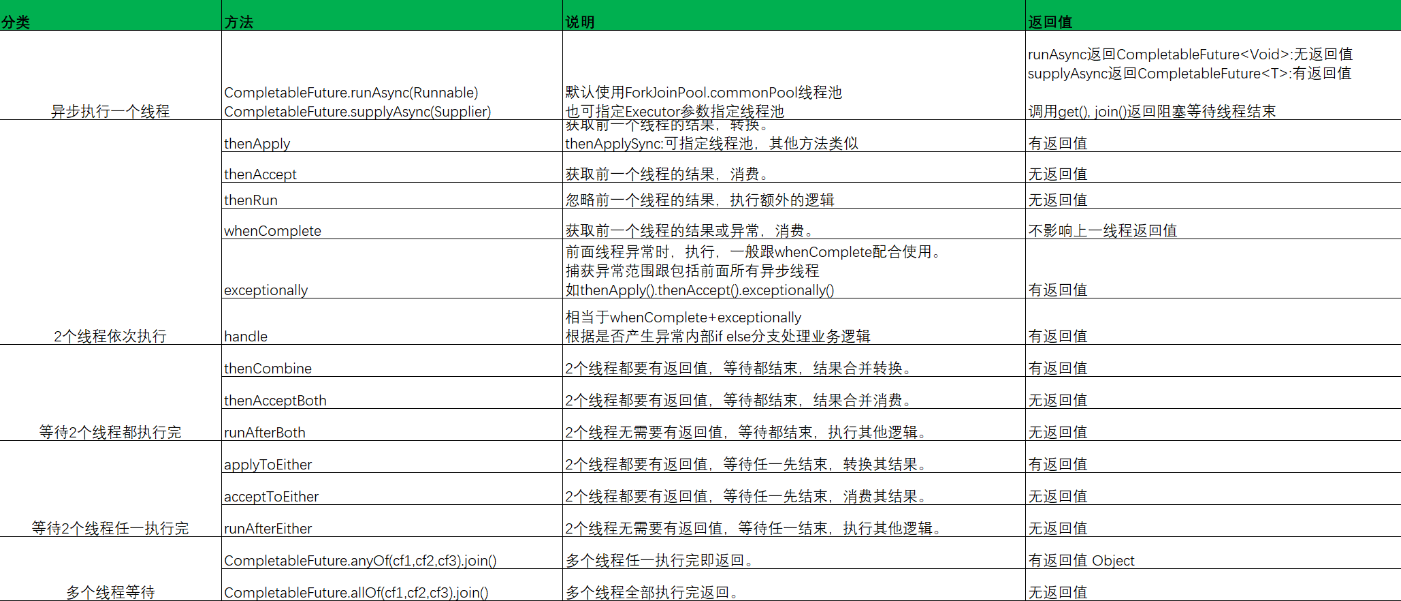
API总结
CompletableFuture提供了多种方法来创建、操作和组合CompletableFuture实例:
- 创建异步计算:
supplyAsync和runAsync是两个创建异步计算任务的静态方法,它们分别对应有返回值和无返回值的异步任务。 - 结果转换:
thenApply和thenApplyAsync方法允许对异步计算的结果进行转换。 - 结果消费:
thenAccept和thenAcceptAsync允许你对结果进行消费,如打印结果。 - 异常处理:
exceptionally方法提供了异常处理的能力,允许你为CompletableFuture的执行定义一个回调,用于处理异常情况。 - 多个CompletableFuture的组合:
thenCombine、thenCompose和allOf等方法允许将多个CompletableFuture组合起来,创建更为复杂的异步流程。
更为详细的可以查看下表:
为什么使用CompletableFuture
异步编程模式可以帮助提高应用的响应性和吞吐量,特别是在处理长时间运行的任务时。使用CompletableFuture的几个关键优势包括:
异步编程:
- 提高程序性能:异步操作不会阻塞主线程,允许同时执行多个任务。
- 增加程序响应性:将耗时操作放入异步任务,保持主线程响应性。
异步结果处理:
- 便捷处理异步任务结果:通过
thenApply(),thenAccept(),thenCombine()等方法处理任务结果,实现流式编程。 - 处理异常情况:
exceptionally(),handle()等方法处理异步任务执行中产生的异常。
场景总结
从上面的用法总结,我们也可以发现使用CompletableFuture通常用于解决以下类似场景的问题:
- 发起异步请求:当用户请求一个产品详情页时,后端服务可以同时发起对三个数据源的异步请求,这可以通过创建三个
CompletableFuture实例来实现,每个实例负责一个数据源的请求。 - 处理异步结果:一旦这些异步请求发出,它们就可以独立地执行,主线程可以继续处理其他任务,当某个
CompletableFuture完成时,它会包含一个结果(或者是执行过程中的异常)。 - 组合异步结果:使用
CompletableFuture的组合方法(如thenCombine、thenAcceptBoth或allOf),可以等待所有异步操作完成,并将它们的结果组合在一起,比如,可以等待产品基本信息、价格和库存以及用户评价都返回后,再将这些数据整合到一个响应对象中,返回给前端。 - 异常处理:如果在获取某个数据源时发生异常,
CompletableFuture允许以异步的方式处理这些异常,比如通过exceptionally方法提供一个默认的备选结果或执行一些清理操作。 - 最终响应:一旦所有数据源的数据都成功获取并组合在一起,或者某个数据源发生异常并得到了妥善处理,服务就可以将最终的产品详情页响应发送给前端用户。
CompletableFuture默认线程池解析:ForkJoinPool or ThreadPerTaskExecutor?
ForkJoinPool 线程池
因为后面的内容有涉及
ForkJoinPool 和ThreadPerTaskExecutor,在解析CompletableFuture默认线程池之前先简单介绍一下这两个线程池
ForkJoinPool线程池是Java并发编程中的一个重要组件,专为高效处理具有分治特性的任务而设计。以下是对其多方面的简单总结:
- 设计目的:旨在通过分治策略(Divide and Conquer)来加速计算密集型任务的执行,将大任务拆分为多个小任务并行处理,最终合并结果。
- 工作窃取(Work-Stealing)算法:ForkJoinPool的核心机制,允许空闲线程从其他线程的任务队列中“窃取”任务执行,确保线程资源充分利用,减少空闲时间,提高整体效率。
- 任务划分与合并:任务通过实现
ForkJoinTask接口(或其子类如RecursiveAction和RecursiveTask)来定义,可以被“分叉”(fork)成子任务并行执行,完成后“合并”(join)结果。 - 线程管理:自动管理和调整线程数量,通常默认使用可用处理器数量减一作为核心线程数,以保持良好的CPU利用率同时避免过多的上下文切换开销。
- 自适应性:根据系统负载动态调整工作线程的数量,适应不同规模和性质的任务,尤其适合高度并行且可分解的任务。
- 常见用途:适用于快速排序、归并排序、矩阵运算、大规模数据处理、复杂算法并行化等场景,以及在Java 8中并行流(parallel streams)和CompletableFuture的后台执行中。
- 注意事项:不适合I/O密集型或易阻塞的操作,因为工作窃取机制依赖于线程的快速执行和任务的高效流转;对于这类任务,应考虑使用专用线程池或结合
ManagedBlocker。 - 资源限制与监控:使用时需注意资源限制,尤其是在共享
ForkJoinPool.commonPool()时,避免因不当使用导致整个应用性能下降。监控工具和日志可以帮助诊断性能瓶颈。
ThreadPerTaskExecutor线程池
ThreadPerTaskExecutor线程池非常简单,它就是CompletableFuture的一个静态内部类,在ThreadPerTaskExecutor 中 execute,他会为每个任务新开一个线程,所以相当于就没有线程池!
static final class ThreadPerTaskExecutor implements Executor {public void execute(Runnable r) { new Thread(r).start(); }}CompletableFuture默认线程池源码分析
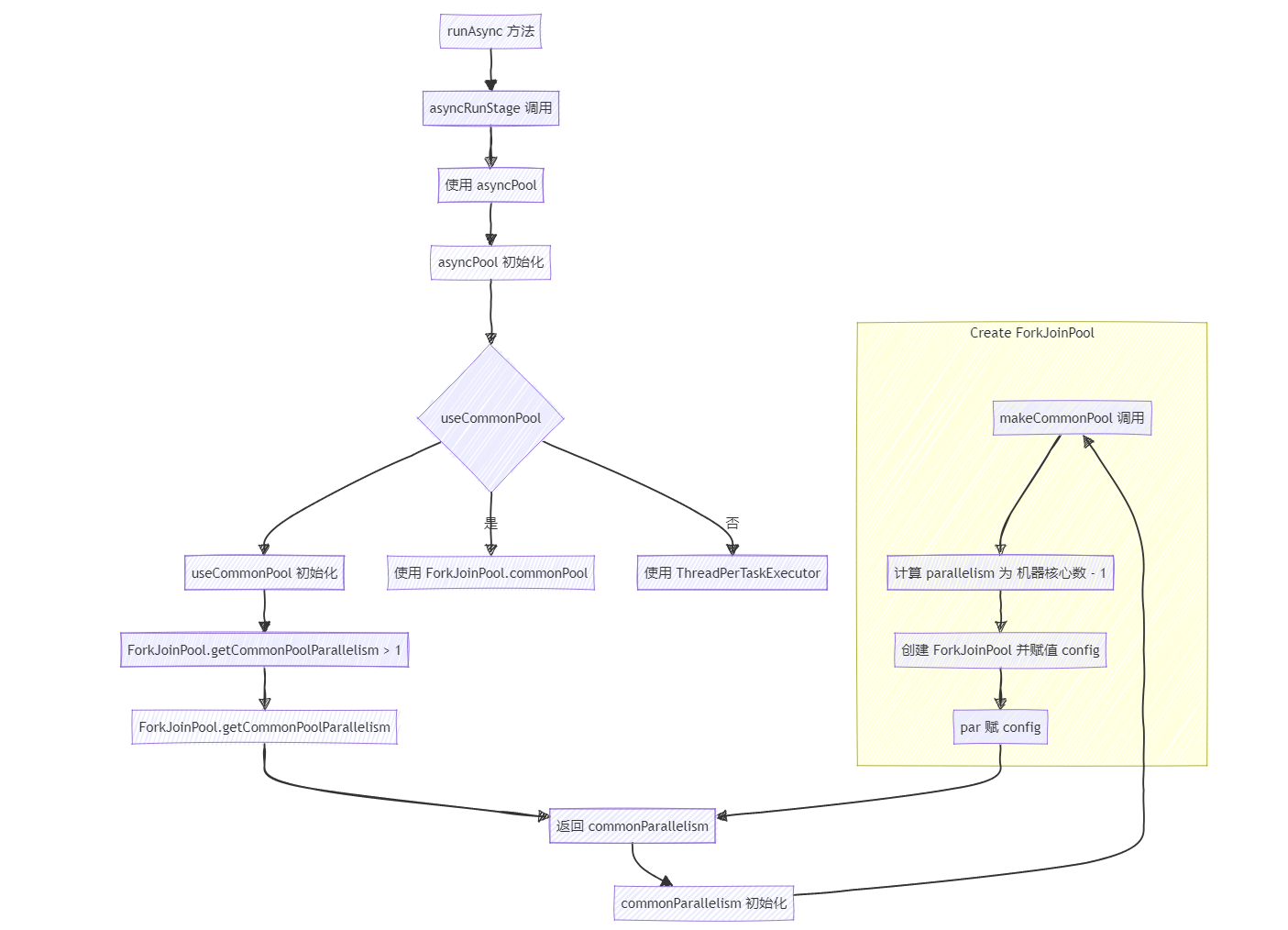
源码流程图
整体流程图大致如下:
CompletableFuture<Void> completableFuture = CompletableFuture.runAsync(() -> {System.out.println("Running in thread: " + Thread.currentThread().getName());
});
1、从runAsync方法点进去分析源码,可以看见使用的是asyncPool。
public static CompletableFuture<Void> runAsync(Runnable runnable) {return asyncRunStage(asyncPool, runnable);
}2、点进asyncPool,useCommonPool是否为true决定了使用 ForkJoinPool线程池还是新建一个线程池ThreadPerTaskExecutor。
private static final Executor asyncPool = useCommonPool ?ForkJoinPool.commonPool() : new ThreadPerTaskExecutor();
3、点进useCommonPool,这里判定的是ForkJoinPool common线程池中并行度级别是否大于1。
private static final boolean useCommonPool =(ForkJoinPool.getCommonPoolParallelism() > 1);4、点进 getCommonPoolParallelism() 方法,返回的是commonParallelism这个字段,再往下找。
public static int getCommonPoolParallelism() {return commonParallelism;}发现只有一个地方对这个属性进行赋值,
//类顶SMASK常量的值
static final int SMASK = 0xffff;
final int config;
static final ForkJoinPool common;//该方法返回了一个commonParallelism的值
public static int getCommonPoolParallelism() {return commonParallelism;}//而commonParallelism的值是在一个静态代码块里被初始化的,也就是类加载的时候初始化
static {//初始化common,这个common即ForkJoinPool自身common = java.security.AccessController.doPrivileged(new java.security.PrivilegedAction<ForkJoinPool>() {public ForkJoinPool run() { return makeCommonPool(); }});//根据par的值来初始化commonParallelism的值int par = common.config & SMASK; // report 1 even if threads disabledcommonParallelism = par > 0 ? par : 1;}
总结一下上面三部分代码,结合在一起看,这部分代码主要是初始化了commonParallelism的值,也就是getCommonPoolParallelism()方法的返回值,这个返回值也决定了是否使用默认线程池,接下来看看具体commonParallelism是如何赋值的:
5、commonParallelism-->par-->common-->makeCommonPool()
commonParallelism的值又是通过par的值来确定的,par的值是common来确定的,而common则是在makeCommonPool()这个方法中初始化的。
6、我们继续跟进makeCommonPool()方法
private static ForkJoinPool makeCommonPool() {int parallelism = -1;if (parallelism < 0 && // default 1 less than #cores//获取机器的cpu核心数 将机器的核心数-1 赋值给parallelism 这一段是是否使用线程池的关键//同时 parallelism也是ForkJoinPool的核心线程数(parallelism = Runtime.getRuntime().availableProcessors() - 1) <= 0)parallelism = 1;if (parallelism > MAX_CAP)parallelism = MAX_CAP;return new ForkJoinPool(parallelism, factory, handler, LIFO_QUEUE,"ForkJoinPool.commonPool-worker-");}//上面的那个构造方法,可以看到把parallelism赋值给了config变量
private ForkJoinPool(int parallelism,ForkJoinWorkerThreadFactory factory,UncaughtExceptionHandler handler,int mode,String workerNamePrefix) {this.workerNamePrefix = workerNamePrefix;this.factory = factory;this.ueh = handler;this.config = (parallelism & SMASK) | mode;long np = (long)(-parallelism); // offset ctl countsthis.ctl = ((np << AC_SHIFT) & AC_MASK) | ((np << TC_SHIFT) & TC_MASK);}总结一下上面两段代码:
- 获取机器核心数-1的值,赋值给parallelism变量,再通过构造方法把parallelism的值赋值给config变量。
- 然后初始化ForkJoinPool的时候。再将config的值赋值给par变量。如果par大于0则将par的值赋给commonParallelism:
- 如果commonParallelism的值大于1的话,useCommonPool的值就为true,就使用默认的线程池
ForkJoinPool - 否则使用
ThreadPerTaskExecutor线程池,此线程池为每个任务创建一个新线程,也就相当于没有线程池。
- 如果commonParallelism的值大于1的话,useCommonPool的值就为true,就使用默认的线程池
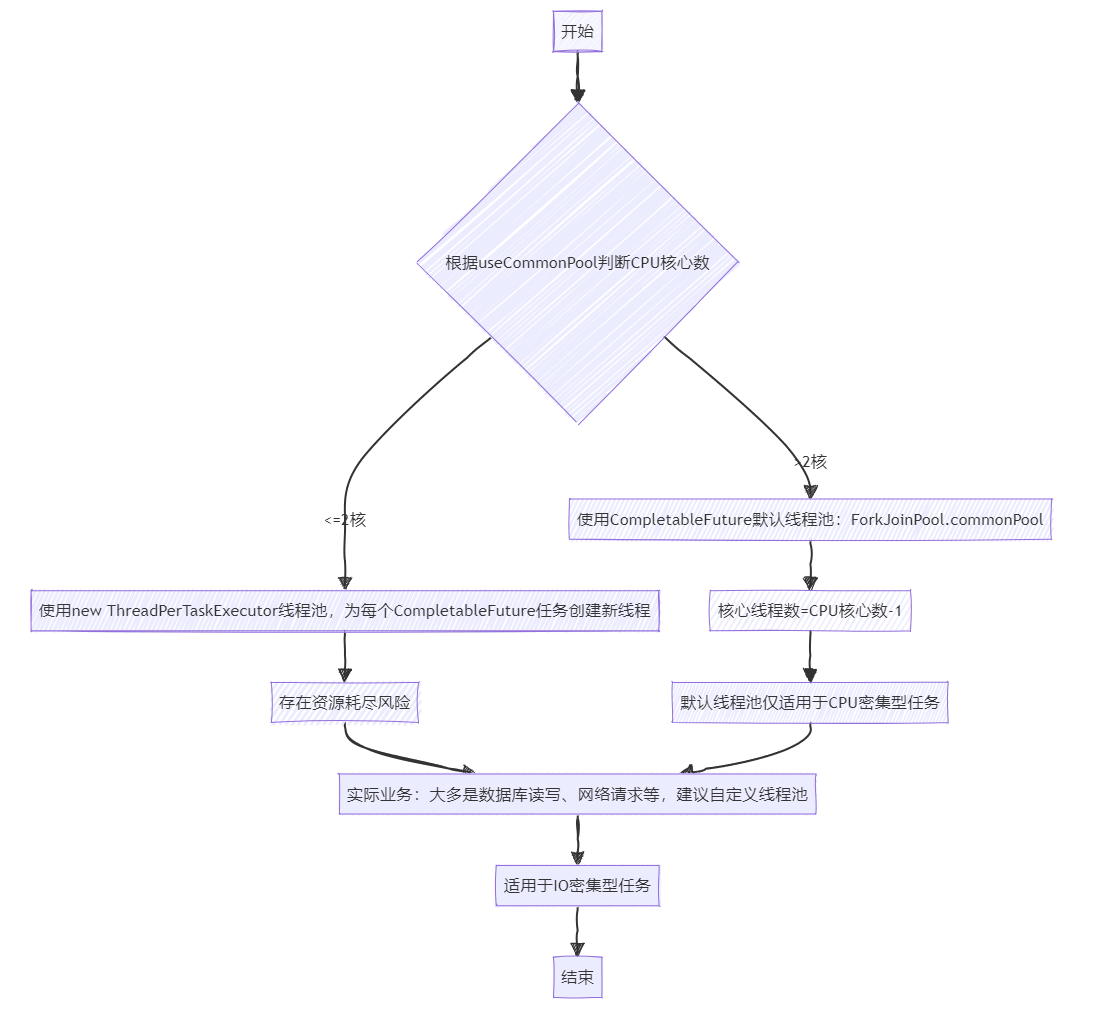
总结
关于CompletableFuture的默认线程池使用情况,其依据及建议可总结如下:
- CompletableFuture是否利用默认线程池,其主要考量因素与计算机的CPU核心数息息相关。仅当CPU核心数减一大于1时,CompletableFuture才会启用默认线程池,也就是
ForkJoinPool.commonPool;反之,使用new ThreadPerTaskExecutor线程池,为每个CompletableFuture任务创建新线程执行。 - 换言之,CompletableFuture的默认线程池只会在具备双核以上配置的计算机上启用。在双核及以下的计算机环境下,每个任务都会独立创建新的线程,相当于并未使用线程池,同时存在资源耗尽的潜在风险。
- 因此,强烈建议在使用CompletableFuture时,务必自行定义线程池。即便启用了默认线程池,池内的核心线程数仍为计算机核心数减一。例如,我们服务器为4核,则最多仅能支持3个核心线程,对于CPU密集型任务而言尚可应对,但在实际业务开发过程中,我们更多地涉及到IO密集型任务,对于此类任务,默认线程池的资源配置显然不足以满足需求,可能导致大量的IO任务处于等待状态,从而大幅降低系统吞吐率,即默认线程池更适合于CPU密集型任务。
注意点
在使用 CompletableFuture 执行异步任务时,有时我们需要根据应用的负载或硬件资源来调整其线程池配置。你可以通过设置JVM参数来实现这一点。具体来说,你可以配置 ForkJoinPool 的并行级别、线程数等参数。
设置 ForkJoinPool 并行级别
ForkJoinPool 是 CompletableFuture 的默认执行器。我们可以通过设置以 java.util.concurrent.ForkJoinPool 开头的 JVM 系统属性来调整其行为。
以下是一些常用的 JVM 参数:
- java.util.concurrent.ForkJoinPool.common.parallelism:设置 ForkJoinPool 的并行级别(即最大并行线程数)。
- java.util.concurrent.ForkJoinPool.common.threadFactory:设置自定义的线程工厂。
- java.util.concurrent.ForkJoinPool.common.exceptionHandler:设置未捕获异常的处理器。
示例
假设我们希望将 ForkJoinPool 的并行级别设置为 4,可以在启动 JVM 时添加以下参数:
java -Djava.util.concurrent.ForkJoinPool.common.parallelism=4 -jar YourApplication.jar
这样,ForkJoinPool 的最大并行线程数将限制为4。
补充
所以对上面的流程加以补充一下就是
-
无JVM参数前提下:
-
若服务器的核心数小于等于2,commonParallelism 则为1,即useCommonPool 为false,new 一个线程池
ThreadPerTaskExecutor。 -
若服务器的核心数大于2,commonParallelism 则为 核心数 - 1,即useCommonPool 为true,使用
ForkJoinPool线程池。
-
-
有JVM参数,以设置参数为准。大于1小于等于32767。和上面判断一致。
项目中使用CompletableFuture默认线程池的坑?
案例分析
1、假如我们有一个MQ消费者处理,然后采用CompletableFuture.runAsync处理消息,
@Component
public class MessageHandler {@RabbitListener(queues = "messageQueue")public void handleMessage(byte[] message){//新启动线程处理复杂业务消息CompletableFuture.runAsync(() -> {//复杂业务处理...});}
}
2、同时我们在另外一个地方也用到了CompletableFuture.runAsync处理CPU密集型任务
public void handleComplexCalculations(){CompletableFuture.runAsync(() -> {//新启动线程处理复杂的计算任务...});}
根据上面我们分析的源码,如果生产假设都是4核,它们两个实际走的都是是默认线程池ForkJoinPool.commonPool(),但是这个是静态全局共享的!!!
static final ForkJoinPool common;public static ForkJoinPool commonPool() {// assert common != null : "static init error";return common;}
所以可想而知,假设在生产环境的情况,很可能高并发或者消息堆积一下子就会把这个默认的ForkJoinPool.commonPool()线程池打满,此时我们另外一个地方计算复杂任务计算的地方就会卡死,因为获取不到线程啊,都被MQ消费那边占用了!
而这种情况很可能在开发和测试环境都复现不了,因为我们不做压测的话,并发也不高,普通点点肯定也没问题,这种问题生产才会复现!
如何解决?
那么如何解决上述问题呢?答案无疑是进行自定义!
- 理想的做法是根据具体场景来定义不同类型的线程池,也就是线程池隔离!例如CPU密集型、IO密集型等等。
- 即便在同属CPU密集型场景下,也可根据实际情况细分为不同类别,如上文所述的MQ场景可独设一个线程池,以避免在高并发场景下由于线程池过载而导致其他地方发生阻塞乃至瘫痪。
至于如何进行自定义,以下指南可供参考。
线程池核心线程数和最大线程数设置指南
线程池参数介绍
- 核心线程数:线程池中始终活跃的线程数量。
- 最大线程数:线程池能够容纳同时执行的最大线程数量。
线程数设置考虑因素
- CPU密集型任务:依赖CPU计算的任务,如循环计算等。
- IO密集型任务:任务执行过程中涉及等待外部操作,如数据库读写、网络请求、磁盘读写等。
CPU密集型任务的线程数设置
- 推荐设置:核心数 + 1。
- 原因:避免线程切换开销,同时允许一定程度的线程中断恢复。
IO密集型任务的线程数设置
- 推荐设置:2 * CPU核心数。
- 原因:IO操作期间,CPU可执行其他线程任务,提高资源利用率。
实际应用中的线程数计算
- 使用工具(如Java的Visual VM)来监测线程的等待时间和运行时间。
- 计算公式:(线程等待时间 / 线程总运行时间)+ 1 * CPU核心数。
生产环境中的线程数设置
- 理论值与实际值可能存在差异,需要通过压力测试来确定最优线程数。
- 压力测试:调整线程数,观察系统性能,找到最优解。
线程池参数设置建议
- 核心业务应用:核心线程数设置为压力测试后的数值,最大线程数可以适当增加。
- 非核心业务应用:核心线程数设置较低,最大线程数设置为压力测试结果
注意事项
- 线程数设置需根据实际业务需求和系统环境进行调整。
- 持续监控和优化是保证系统性能的关键。
这篇关于从用法到源码再到应用场景:全方位了解CompletableFuture及其线程池的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





