本文主要是介绍设计新境界:大数据赋能UI的创新美学,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
设计新境界:大数据赋能UI的创新美学
引言
随着大数据技术的蓬勃发展,它已成为推动UI设计创新的重要力量。大数据不仅为界面设计提供了丰富的数据资源,还赋予了设计师以全新的视角和工具来探索美学的新境界。本文将探讨大数据如何赋能UI设计,引领创新美学的发展。
大数据赋能UI设计
1. 数据洞察力
大数据技术能够分析和处理海量的用户数据,提供深入的用户洞察,帮助设计师更好地理解用户需求和行为。
2. 个性化设计
利用大数据,UI设计可以更加个性化。设计师可以根据用户的特定行为和偏好,为用户定制独特的界面体验。
3. 动态交互
大数据支持实时数据分析,使UI设计能够实现动态交互,界面可以根据用户的实时行为和反馈进行自适应调整。
4. 持续优化
通过持续收集和分析用户数据,UI设计可以实现持续优化,不断提升用户体验。
大数据与UI创新美学的融合
1. 视觉元素的创新
大数据可以帮助设计师发现用户对色彩、布局和图形等视觉元素的偏好,从而创造出新颖而吸引人的界面设计。
2. 功能性与美学的平衡
在大数据的支持下,UI设计可以在满足功能性的同时,追求美学的极致,实现功能性与美学的完美平衡。
3. 情感化设计
通过分析用户的情感反应,大数据可以帮助设计师创造出能够引起用户情感共鸣的界面,提升用户的情感体验。
4. 环境适应性
大数据使UI设计能够适应不同的使用环境和情境,创造出与用户所处的环境和谐共生的设计。
大数据赋能UI设计的应用案例
案例一:个性化新闻阅读应用
通过分析用户的阅读习惯和兴趣点,新闻阅读应用能够为用户推荐个性化的新闻内容,并调整界面布局以适应用户的阅读习惯。
案例二:智能健康监测设备
智能健康监测设备通过收集用户的生理数据,为用户提供定制化的健康建议,并以美观的方式展示健康数据。
案例三:在线学习平台
在线学习平台利用学习行为数据,为学生提供个性化的学习路径,并设计出既美观又易于理解的学习界面。
案例四:智能家居控制界面
智能家居控制界面通过分析用户的家庭活动模式,自动调整家居设备的设置,并以直观美观的方式展示控制选项。
结语
大数据不仅改变了UI设计的方法和流程,更拓展了设计的美学边界。它赋予了设计师以全新的工具和视角,创造出既美观又实用的界面设计。随着大数据技术的不断进步,我们有理由相信,大数据将继续赋能UI设计,引领设计新境界的发展,为用户带来更加丰富和精彩的视觉体验。
本文深入探讨了大数据如何赋能UI设计,推动创新美学的发展,并提供了具体的应用案例。希望这篇文章能够启发读者对大数据在UI设计中应用的深入思考,并认识到其在推动设计创新中的重要作用。



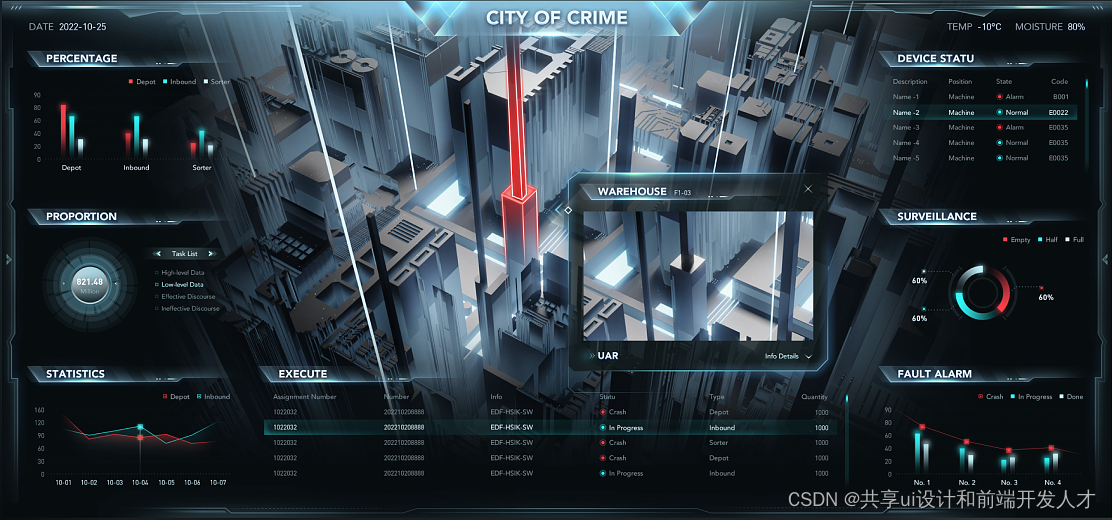





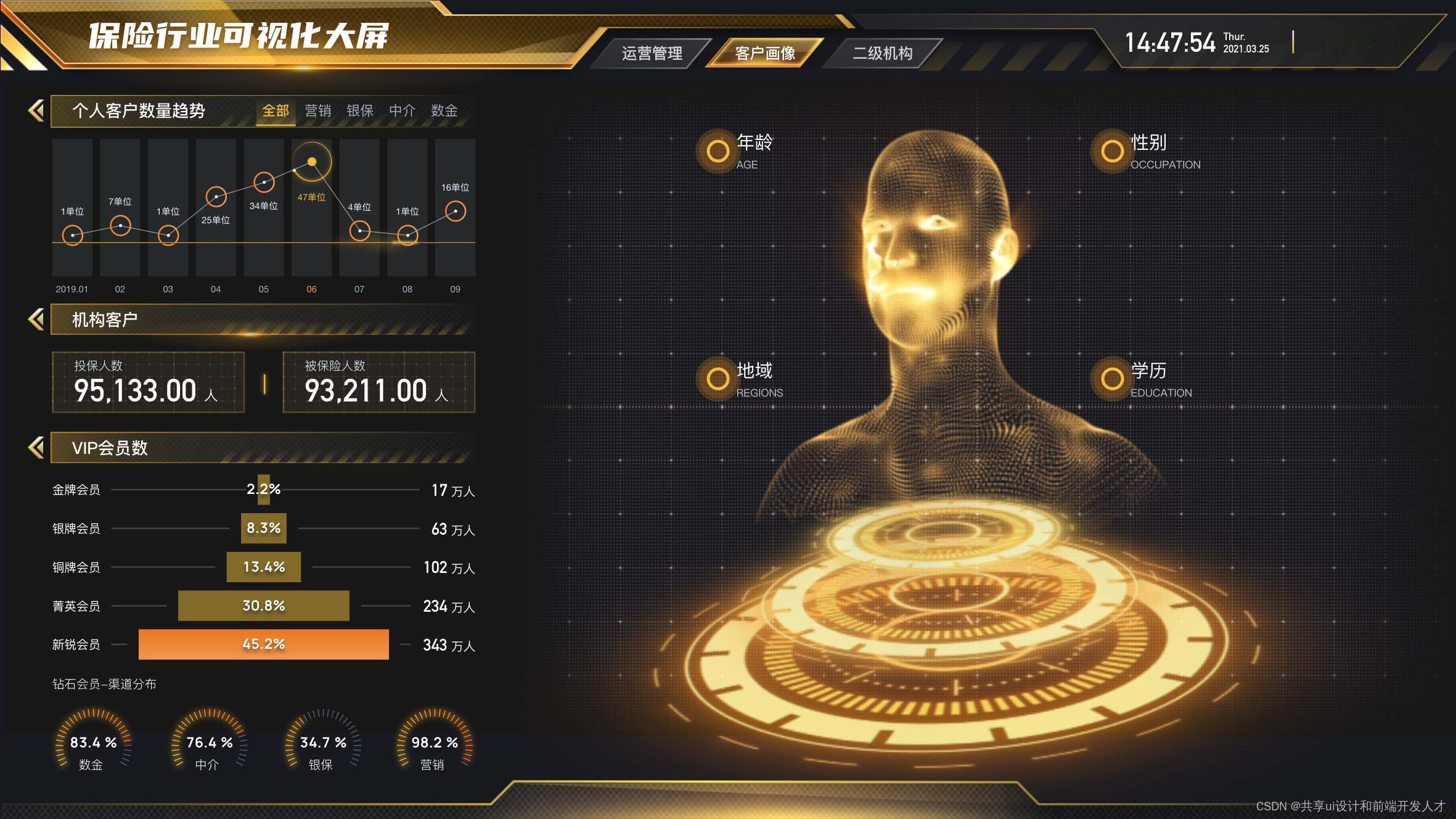
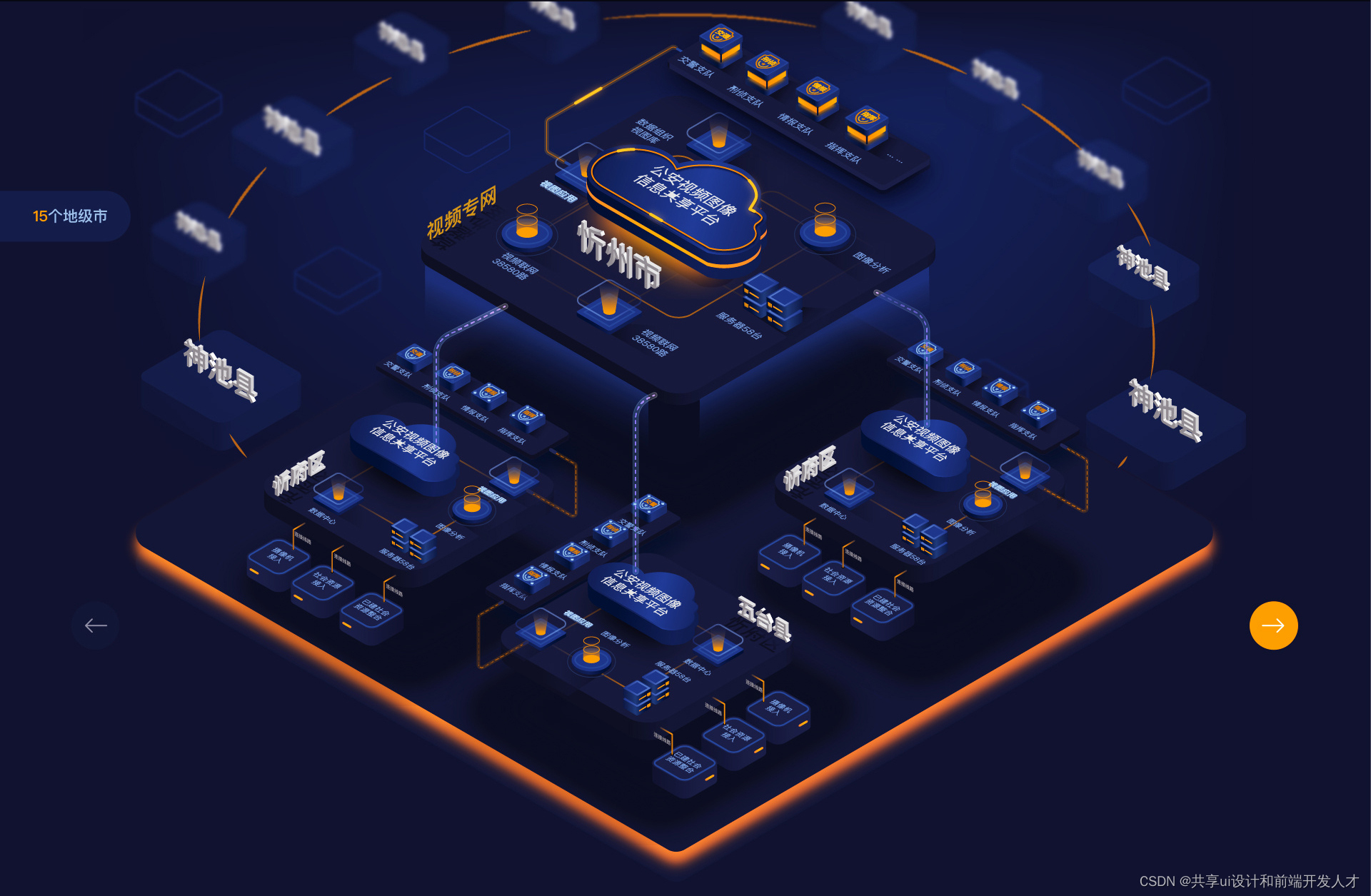
这篇关于设计新境界:大数据赋能UI的创新美学的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





