本文主要是介绍快速理解聚集索引和非聚集索引,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据库的索引,听起来挺神秘的,仔细想想。这些索引,其实就是平时咱们查东西时候常用的两种手段。无非就是为了提高我们找东西的效率而已。那么我们平时又是怎么查东西呢?
聚集索引:
聚集索引,来源于生活尝试。这中索引可以说是按照数据的物理存储进行划分的。对于一堆记录来说,使用聚集索引就是对这堆记录 进行 堆划分。即主要描述的是物理上的存储。
举个例子:
比如图书馆新进了一批书。那么这些书需要放到图书馆内。书如何放呢?一般都有一个规则,杂志类的放到101房间,文学类的放到102房间,理工类的放到103房间等等。这些存储的规则决定了每本书应该放到哪里。而这个例子中聚集索引为书的类别。
正式因为这种存储规则,才导致 聚集索引的唯一性。
误区:
有的人认为,聚集索引的字段是唯一的。这是因为sql server 中添加主键的时候,自动给主键所在的字段生成一个聚集索引。所以人们会认为聚集索引所加的字段是唯一的。
思考一下上面这个问题。杂志类的书放到101房间。那么如果杂志类的书太多,一个101房间存放不下。那么可能101,201两个房间来存放杂志类的书籍。如果这样分析的话,那么一个杂志类对应多个房间。放到表存储的话,那么这个类别字段 就不是唯一的了。
非聚集索引:
非聚集索引,也可以从生活中找到映射。非聚集索引强调的是逻辑分类。可以说是定义了一套存储规则,而需要有一块控件来维护这个规则,这个被称之为索引表。
继续使用上述提到的例子:
同学如果想去图书馆找一本书,而不知道这本书在哪里?那么这个同学首先应该找的就是 检索室吧。对于要查找一本书来说,在检索室查是一个非常快捷的的途径了吧。但是,在检索室中你查到了该书在XX室XX书架的信息。你的查询结束了吗?没有吧。你仅仅找到了目的书的位置信息,你还要去该位置去取书。
对于这种方式来说,你需要两个步骤:
1、查询该记录所在的位置。
2、通过该位置去取要找的记录。
区别:
聚集索引:可以帮助把很大的范围,迅速减小范围。但是查找该记录,就要从这个小范围中Scan了。
非聚集索引:把一个很大的范围,转换成一个小的地图。你需要在这个小地图中找你要寻找的信息的位置。然后通过这个位置,再去找你所需要的记录。
索引与主键的区别
主键:主键是唯一的,用于快速定位一条记录。
聚集索引:聚集索引也是唯一的。(因为聚集索引的划分依据是物理存储)。而聚集索引的主要是为了快速的缩小查找范围,即记录数目未定。
主键和索引没有关系。他们的用途相近。如果聚集索引加上唯一性约束之后,他们的作用就一样了。
使用场景
基于上述的两种规则,那么在什么时候适合聚集索引,什么时候适合非聚集索引?
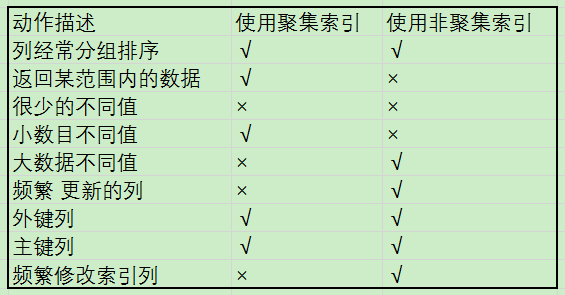
原文:https://blog.csdn.net/zc474235918/article/details/50580639
这篇关于快速理解聚集索引和非聚集索引的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








