本文主要是介绍数据结构_链式二叉树(Chained binary tree)基础,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✨✨所属专栏:数据结构✨✨
✨✨作者主页:嶔某✨✨

二叉树的遍历
前序、中序以及后序遍历
学习二叉树结构,最简单的方式就是遍历。所谓二叉树遍历(Traversal)是按照某种特定的规则,依次对二叉树中的结点进行相应的操作,并且每个结点只操作一次。访问结点所做的操作依赖于具体的应用问题。 遍历是二叉树上最重要的运算之一,也是二叉树上进行其它运算的基础。
按照规则,二叉树的遍历有:前序/中序/后序的递归结构遍历:
1. 前序遍历(Preorder Traversal 亦称先序遍历)——访问根结点的操作发生在遍历其左右子树之前。
2. 中序遍历(Inorder Traversal)——访问根结点的操作发生在遍历其左右子树之中(间)。
3. 后序遍历(Postorder Traversal)——访问根结点的操作发生在遍历其左右子树之后。
由于被访问的结点必是某子树的根,所以N(Node)、L(Left subtree)和R(Right subtree)又可解释为根、根的左子树和根的右子树。NLR、LNR和LRN分别又称为先根遍历、中根遍历和后根遍历。
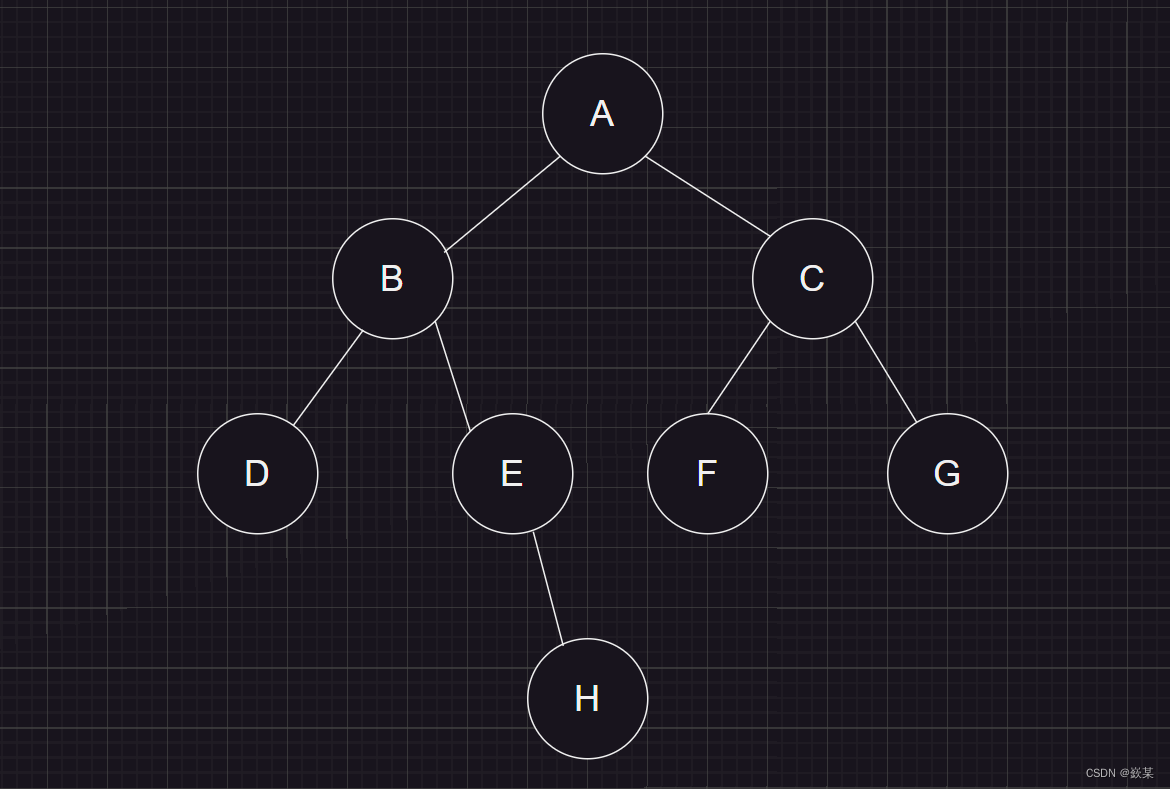
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root)
{if (root == NULL){ printf("# ");return;}printf("%c ",root->_data);BinaryTreePrevOrder(root->_left);BinaryTreePrevOrder(root->_right);
}
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root)
{if (root == NULL){printf("# ");return;}BinaryTreePrevOrder(root->_left);printf("%c ", root->_data);BinaryTreePrevOrder(root->_right);
}
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root)
{if (root == NULL){printf("# ");return;}BinaryTreePrevOrder(root->_left);BinaryTreePrevOrder(root->_right);printf("%c ", root->_data);
}层序遍历
层序遍历:除了前序遍历、中序遍历、后序遍历外,还可以对二叉树进行层序遍历。设二叉树的根结点所在层数为1,层序遍历就是从所在二叉树的根结点出发,首先访问第一层的树根结点,然后从左到右访问第2层上的结点,接着是第三层的结点,以此类推,自上而下,自左至右逐层访问树的结点的过程就是层序遍历。
这里与前、中、后序遍历不同的是:层序遍历用的迭代而非递归。创建一个队列,将整个树的根节点入队,之后再将根节点的左右节点入队。让上一层节点带动下一层,父节点将子女节点带入队,之后将父节点拿出队列,这样就实现了层序遍历。
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root)
{assert(root);Queue q;QueueInit(&q);QueuePush(&q,root);while (QueueSize(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);printf("%c ", front->_data);if (front->_left)QueuePush(&q,front->_left);if(front->_right)QueuePush(&q,front->_right);}
}其他函数
通过前序遍历数组创建二叉树
判断下标为i的字符是否为'#',如果不为'#'那就新malloc一个节点将数据放进去,新节点的左右节点分别再递归赋值。
BTNode* BinaryTreeCreate(BTDataType* a,int* pi)
{if (a[*pi] == '#'){(*pi)++;return NULL;}BTNode* new = (BTNode*)malloc(sizeof(BTNode));if (new == NULL){perror("malloc is fail");return NULL;}new->_data = a[(*pi)++];new->_left = BinaryTreeCreate(a, pi);new->_right = BinaryTreeCreate(a, pi);return new;
}销毁二叉树
如果当前节点为空那么就释放,如果当前节点不为空,那么就先递归释放左右子树,左右子树释放后再将根节点释放并置空。
// 二叉树销毁
void BinaryTreeDestory(BTNode** root)
{if (*root == NULL){free(*root);return;}BinaryTreeDestory(&(*root)->_left);BinaryTreeDestory(&(*root)->_right);free(*root);*root = NULL;
}二叉树节点个数
如果当前节点为空返回0,如果当前节点不为空返回其左右子树的节点个数+1。
// 二叉树节点个数
int BinaryTreeSize(BTNode* root)
{if (root == NULL)return 0;return BinaryTreeSize(root->_left)+ BinaryTreeSize(root->_right) + 1;
}二叉树叶子节点个数
如果节点的左右节点都为空返回1,否则返回左右子树的叶子节点个数。
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL)return 0;if (root->_left == NULL && root->_right == NULL)return 1;return BinaryTreeLeafSize(root->_left)+ BinaryTreeLeafSize(root->_right);
}二叉树第k层节点个数
第k层节点的个数,可以看作第一层的左右节点的第k-1层节点个数,因此当k == 1时此层就是要计算再内的节点。
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL)return 0;if (k == 1)return 1;return BinaryTreeLevelKSize(root->_left, k - 1)+ BinaryTreeLevelKSize(root->_right, k - 1);
}二叉树查找值为x的节点
采取前序遍历,如果根节点的值等于x,返回root,否则先判断左子树有无符合节点,若有返回对应的节点,反之返回另一个子树的对应节点,若左右字数都没有对应节点,最终将返回空
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{if (root == NULL)return NULL;if (root->_data == x)return root;BTNode* ret1 = BinaryTreeFind(root->_left, x);if (ret1 != NULL)return ret1;return BinaryTreeFind(root->_right, x);
}判断二叉树是否为完全二叉树
建立一个队列,和层序遍历一样,当遇到空节点时,跳出循环,开始判断。如果再空节点的后面还有非空节点,那么这棵树就不是完全二叉树。反之此树空节点之后的所有的节点都为空,那么此树为完全二叉树。

// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root)
{assert(root);Queue q;QueueInit(&q);QueuePush(&q, root);while (QueueSize(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front == NULL)break;QueuePush(&q, front->_left);QueuePush(&q, front->_right);}while (QueueSize(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front){Destory(&q);return false;}}return true;
}本期博客到这里就结束了,如果有什么错误,欢迎指出,如果对你有帮助,请点个赞,谢谢!
这篇关于数据结构_链式二叉树(Chained binary tree)基础的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





