本文主要是介绍编译器 编译过程 compiling 动态链接库 Linking 接口ABI LTO PGO inline bazel增量编译,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
编译器 编译过程 compiling 动态链接库 Linking 接口ABI LTO PGO
Theory
-
Shared Library Symbol Conflicts (on Linux)
- 从左往右查找:Note that the linker only looks further down the line when looking for symbols used by but not defined in the current lib.
-
Linux 下 C++so 热更新
-
ABI (Application Binary Interface)
- 应用程序的二进制接口,对于一个二进制的动态库或者静态库而言,可以详细描述在其中的函数的调用方式,定义在其中的数据类型的大小,数据结构的内存布局方式等信息
- ABI 信息 对不同操作系统、不同编译链版本、不同二进制库对应源码版本 有或大或小的差异,从而造成预编译二进制库的兼容性问题,导致 compile error 或 执行时coredump
-
编译器有能力让不同 target 的 cpp 文件的不同编译选项,有区分地生效。但无法控制其它cpp文件对头文件的使用,因此头文件为主体的开源项目,经常不得不很小心地去处理各种使用情况。
Linking
linking with libraries: -lXXX
- statically-linked library: libXXX.a(lib)
- dynamically-linked library : libXXX.so(dll)
- -I /foo/bar : 头文件路径 compile line
- -L 库文件路径: link line
Separate Compilation: -c, 只产生object file, 不link, 后面联合link-editor
LTO (Link Time Optimization)
- 本质想解决的问题:编译 a.cpp 的时候看不到 b.cpp,编译器做不了优化
- 解决方法:翻译 a.cpp 代码成中间语言 (LLVM IR Bitcode),放到 a.o 里;链接阶段把它们都放在一起,一个大文件来做优化
- 运行方式:linker调用编译器提供的plugin
- 开启方式:
-flto
GTC2022 - Automated Performance Improvement Using CUDA Link Time Optimization [S41595]
- CUDA 5.0:separate compilation
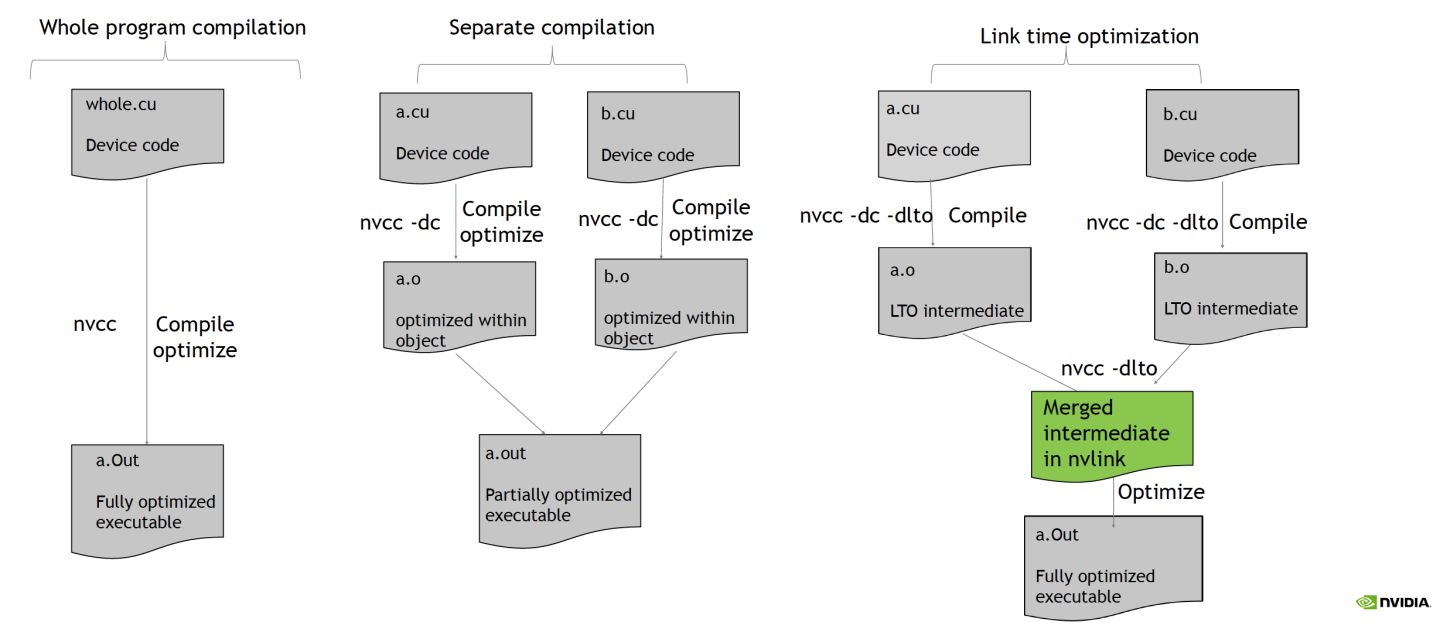

-
LTO
- how to use 如上图
- Partial LTO,需要 execuable 支持 LTO
-
JIT LTO (just in time LTO)
- linking is performed at runtime
- Generation of LTO IR is either offline with nvcc, or at runtime with nvrtc
-
Use JIT LTO
- 用法见下图
- The CUDA math libraries (cuFFT, cuSPARSE, etc) are starting to use JIT LTO; see GTC Fall 2021 talk “JIT LTO Adoption in cuSPARSE/cuFFT: Use Case Overview”
- indirect user callback 转化为 JIT LTO callback
- another use case: configure the used kernels —> minimal library size
// Use nvrtc to generate the LTOIR (“input” is CUDA C++ string):
nvrtcProgram prog;
nvrtcCreateProgram(&prog, input, name, 0, nullptr, nullptr);
const char *options[2] = {"-dlto", "-dc"};
const nvrtcResult result = nvrtcCompileProgram(prog, 2, options);
size_t irSize;
nvrtcGetNVVMSize(prog, &irSize);
char *ltoIR = (char*)malloc(irSize);
nvrtcGetNVVM(prog, ltoIR); // returns LTO IR// LTO inputs are then passed to cuLink* driver APIs, so linking is performed at runtime
CUlinkState state;
CUjit_option jitOptions[] = {CUjit_option::CU_JIT_LTO};
void *jitOptionValues[] = {(void*) 1};
cuLinkCreate(1, jitOptions, jitOptionValues, &state);
cuLinkAddData(state, CUjitInputType::CU_JIT_INPUT_NVVM,
ltoIR, irSize, name, 0, NULL, NULL);
cuLinkAddData( /* another input */);
size_t size;
void *linkedCubin;
cuLinkComplete(state, linkedCubin, &size);
cuModuleLoadData(&mod, linkedCubin);// Math libraries hide the cuLink details in their CreatePlan APIs.
- LTO WITH REFERENCE INFORMATION
- Starting in CUDA 11.7, nvcc will track host references to device code, which LTO can use to remove unused code.
- JIT LTO needs user to tell it this information, so new cuLinkCreate options:
- CU_JIT_REFERENCED_KERNEL_NAMES
- CU_JIT_REFERENCED_VARIABLE_NAMES
- CU_JIT_OPTIMIZE_UNUSED_DEVICE_VARIABLES
- The *NAMES strings use implicit wildcards, so “foo” will match a mangled name like “Z3fooi”.
__device__ int array1[1024];
__device__ int array2[256];
__global__ void kernel1 (void) {
… array1[i]…
}
__global__ void kernel2 (void) {
… array2[i]…
}
….
kernel2<<<1,1>>>(); // host code launches kernel2
- 收益来源
- Much of the speedup comes from cross-file inlining, which then helps keep the data in registers.
- Seeing the whole callgraph also helps to remove any dead code.
- References:
- https://developer.nvidia.com/blog/improving-gpu-app-performance-with-cuda-11-2-device-lto/ – offline LTO
- https://developer.nvidia.com/blog/discovering-new-features-in-cuda-11-4/ – JIT LTO
- https://docs.nvidia.com/cuda/cuda-compiler-driver-nvcc/index.html#optimization-of-separate-compilation – nvcc
- https://docs.nvidia.com/cuda/nvrtc/index.html – nvrtc
- https://docs.nvidia.com/cuda/nvrtc/index.html – cuLink APIs
- https://docs.nvidia.com/cuda/nvrtc/index.html – compatibility guarantees
- Application paper
PGO (Profile Guided Optimization)
PGO(Profile Guided Optimization)是一种代码优化技术,它根据程序运行时的行为来优化代码。以下是关于PGO的详细介绍:
工作原理:PGO的基本思想是在程序运行时对代码进行测量,并使用这些测量数据来优化代码。例如,如果某个函数在运行时经常被调用,则可以使用PGO优化来使这个函数的执行速度更快。PGO通过缩小代码大小、减少分支错误预测和重新组织代码布局来减少指令缓存问题,从而提高应用程序性能。
工作阶段:PGO优化通常包含三个阶段或步骤。首先,编译器从源代码和编译器的特殊代码创建并链接插桩程序。然后,运行检测的可执行文件,每次执行检测代码时,检测程序都会生成一个动态信息文件,该文件用于最终编译。最后,在第二次编译时,动态信息文件将合并到摘要文件中。使用此文件中的配置文件信息摘要,编译器尝试优化程序中旅行最频繁的路径的执行。
应用场景:PGO特别适合于大型复杂项目,因为当项目代码量大且复杂时,手动寻找性能问题变得困难,而PGO可以快速定位问题点。此外,对于性能敏感应用,如实时性要求高的游戏引擎、数据库系统或科学计算应用,PGO的优化效果可能更为显著。同时,PGO还可以集成到自动化测试和构建流程中,每次迭代后自动分析性能变化,确保优化方向正确。
工具支持:PGO优化可以通过使用编译器工具链来实现,例如GCC和Clang。这些工具可以通过命令行或者集成开发环境(IDE)进行使用。同时,有一些专门的工具如PGOAnalyzer,它提供了跨平台支持、易用性、深度洞察和开源社区等优势,可以帮助开发者更好地利用PGO优化技术。
C++
- 常用编译宏
- inline
- inline 的坏处:代码变多了,变量变多了,可能寄存器不够分配了,只能偷内存,性能变差,尤其是发生在 loop 中
- 编译器基本无视普通的 inline 关键字,根据自己的决策来做,内部有 cost model 评判 inline 是否有收益
- 如果一个inline会在多个源文件中被用到,那么必须把它定义在头文件中,否则会找不到符号
- inline
#pragma once#define likely(x) __builtin_expect(!!(x), 1)
#define unlikely(x) __builtin_expect(!!(x)<这篇关于编译器 编译过程 compiling 动态链接库 Linking 接口ABI LTO PGO inline bazel增量编译的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








