本文主要是介绍SSMP整合案例第二步 数据层dao开发及实现特殊查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
数据层开发
数据层实现Dao层

在配置文件里引入MyBatisPlus和Druid的坐标
MyBatisPlus 的坐标在添加起步依赖的时候不能手动添加
只能在maven项目的pom文件中添加坐标后重新构建
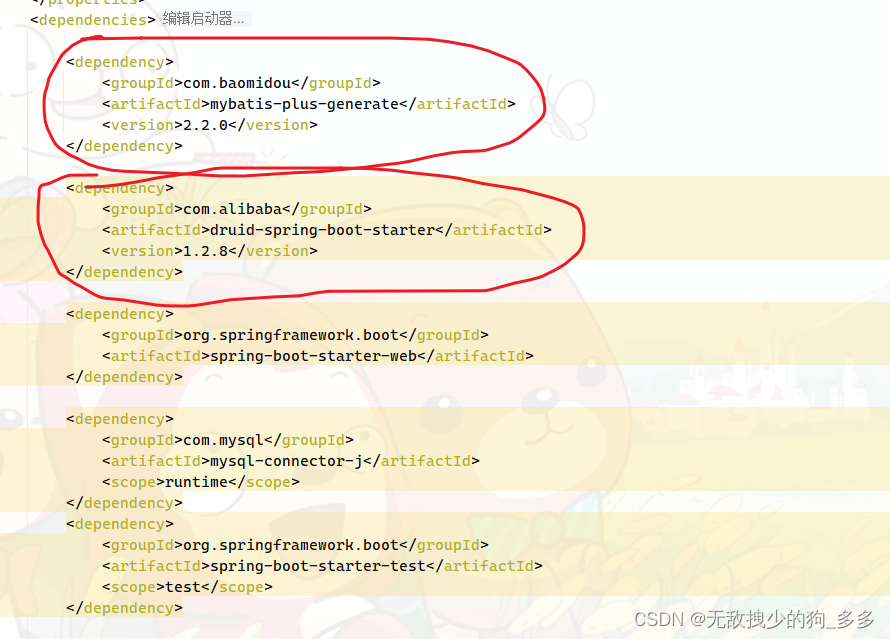
导入Mybatis的坐标
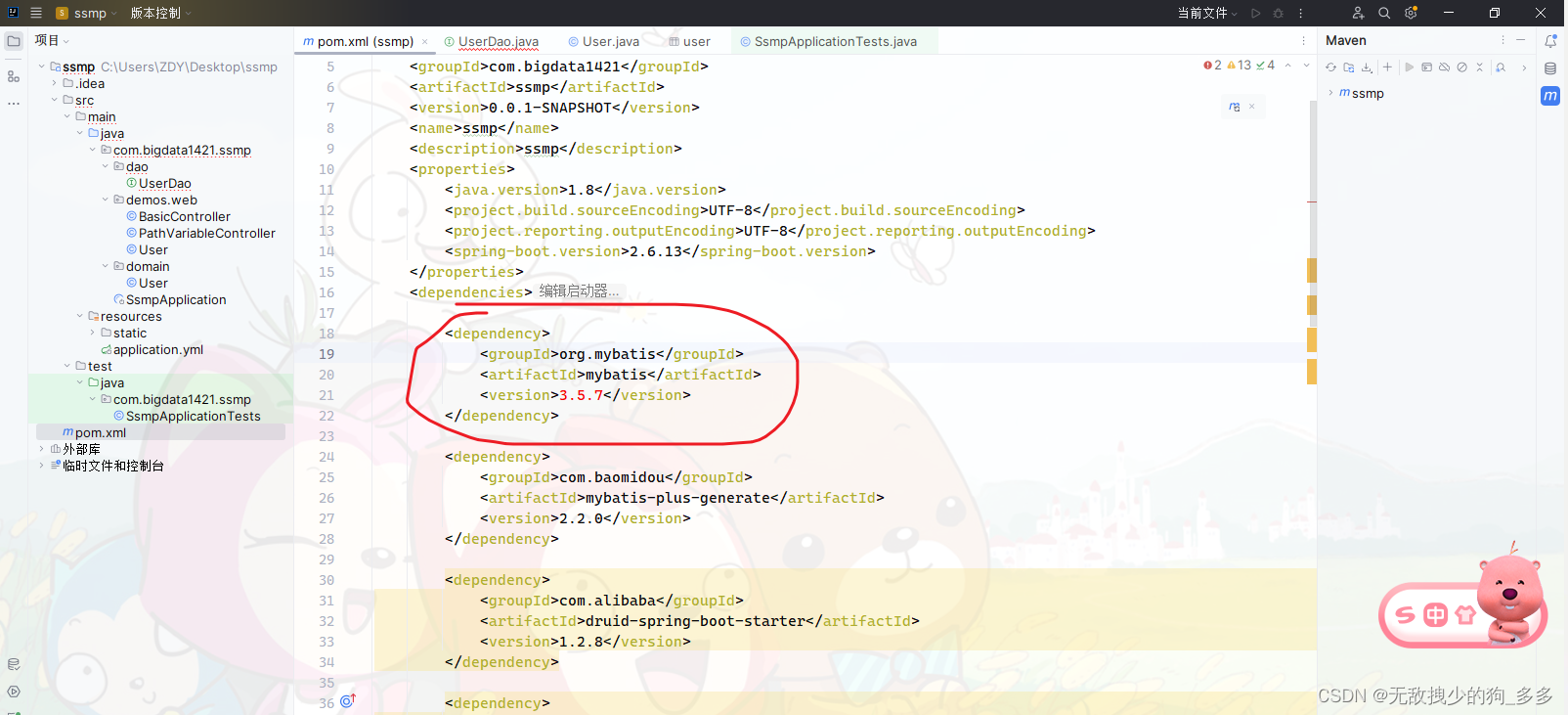
写配置文件 注意配置文件是yml
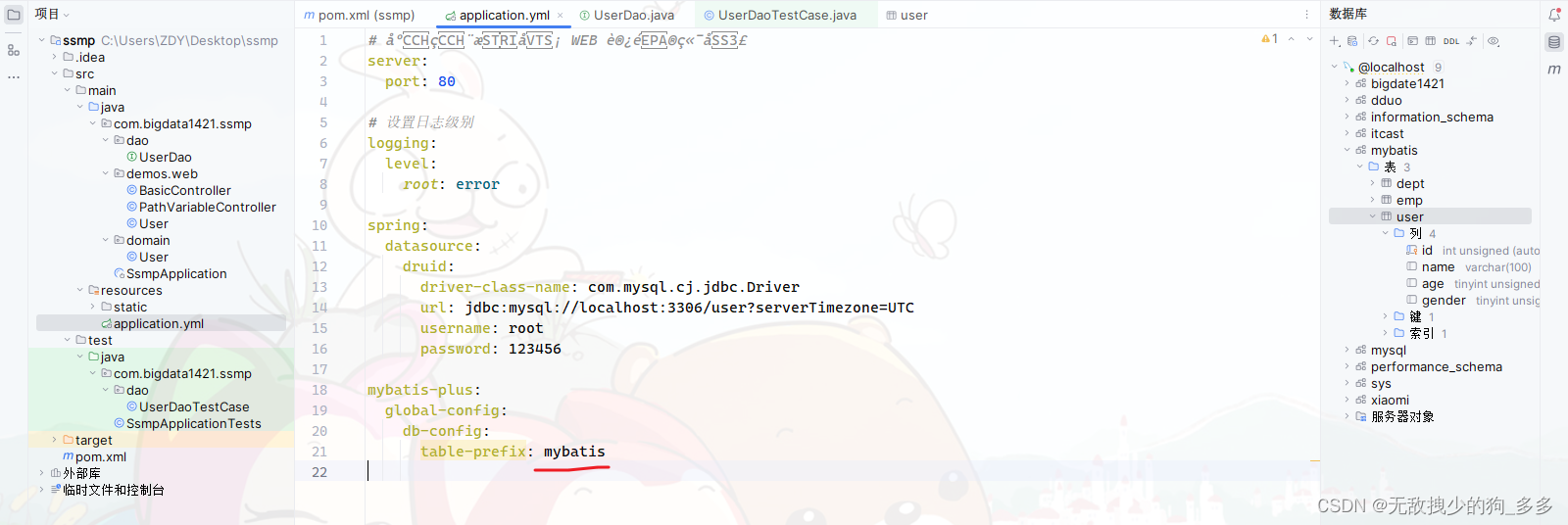
server:port: 80#下面这些内容是为了让MyBatis映射
#指定Mybatis的Mapper文件# 专门用来配置的对象datasource
spring:datasource:druid:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/mybatis?serverTimezone=UTCusername: rootpassword: 123456# 配置mybatis-plus
mybatis-plus:global-config:db—config:table-prefix: tbl_接下来是做数据层接口
package com.bigdata1421.ssmp.dao;import com.bigdata1421.ssmp.domain.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;// Mybatis的数据层注解
@Mapper
public interface UserDao {@Select("select * from tbl_user where id= #{id}")User getById(Integer id);}测试运行
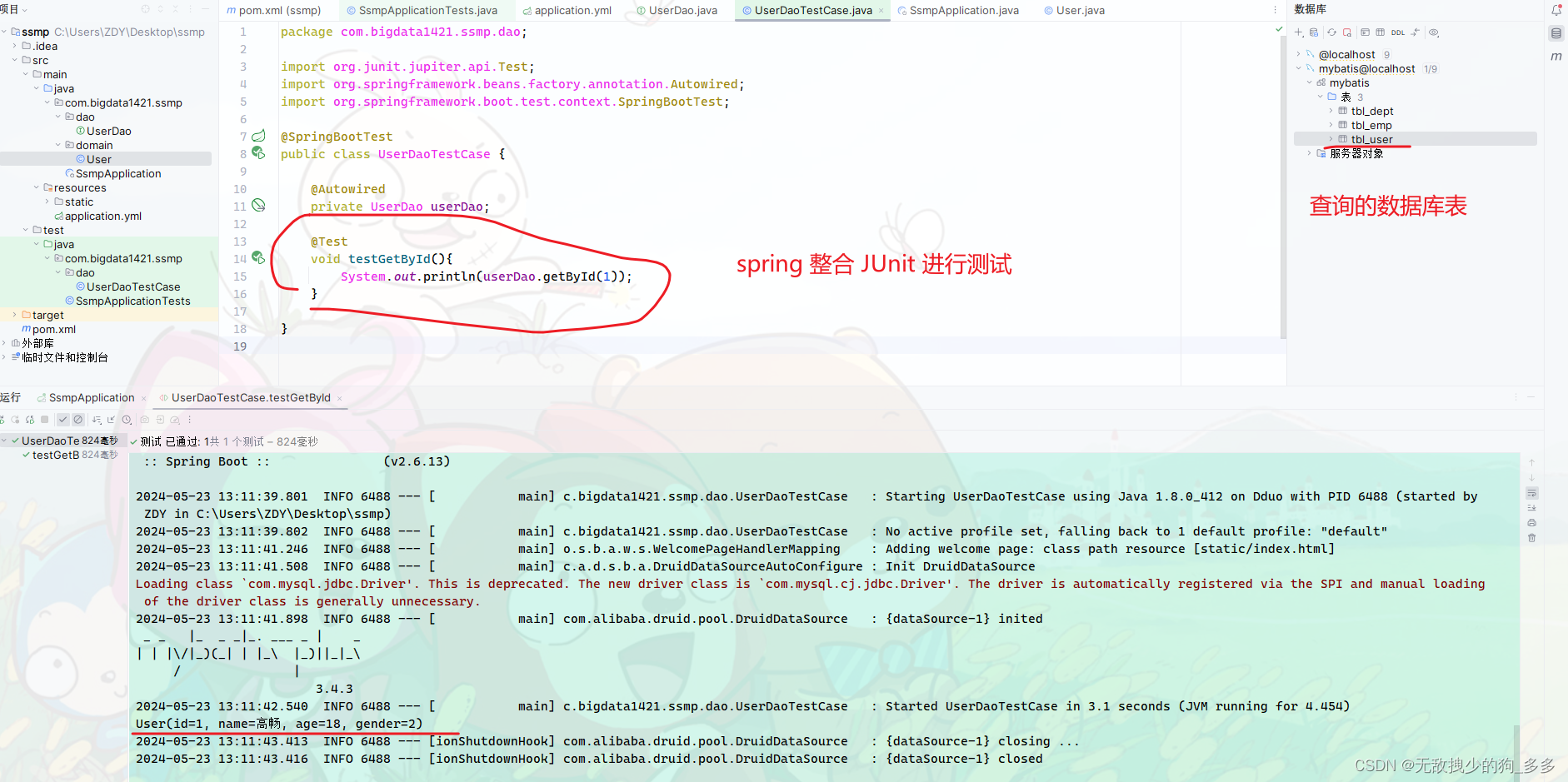
Mybatis plus快速开发方案
指定模块操作
数据层接口可以直接简写
package com.bigdata1421.ssmp.dao;import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.bigdata1421.ssmp.domain.User;
import org.apache.ibatis.annotations.Mapper;
import org.apache.ibatis.annotations.Select;// Mybatis的数据层注解
@Mapper
public interface UserDao extends BaseMapper<User>{//Mybatis-plus//mp快速开发方案// @Select("select * from tbl_user where id= #{id}")
// User getById(Integer id);}测试类直接调用Mybatis-plus统一父类的方法即可
即可进行增删改查的操作
这就是开发者越来越强的原因
测试一下
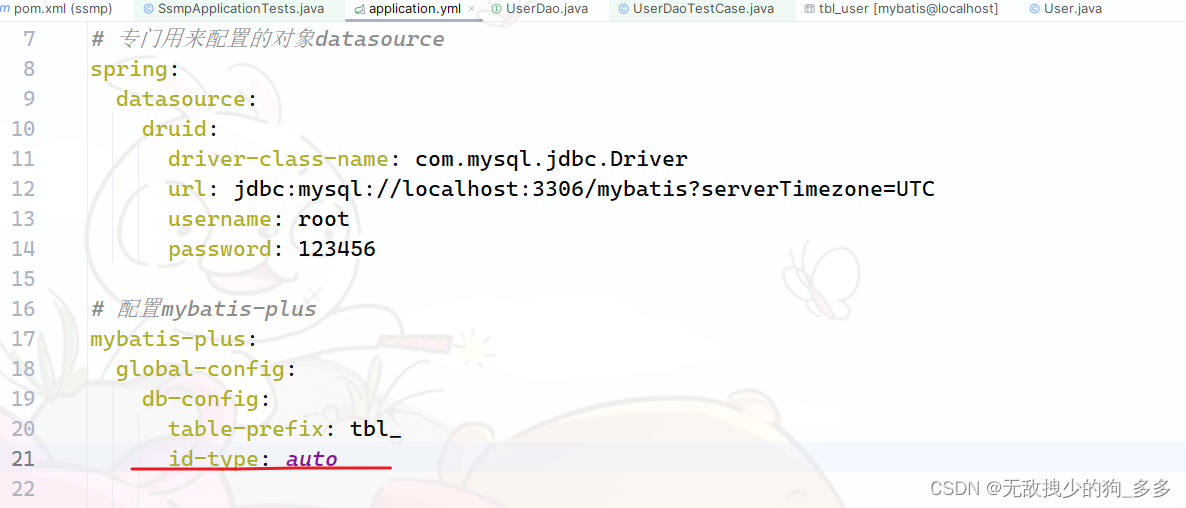
Mybatis-plus添加数据的id用的是雪花算法
我们需要在配置文件中设置
测试
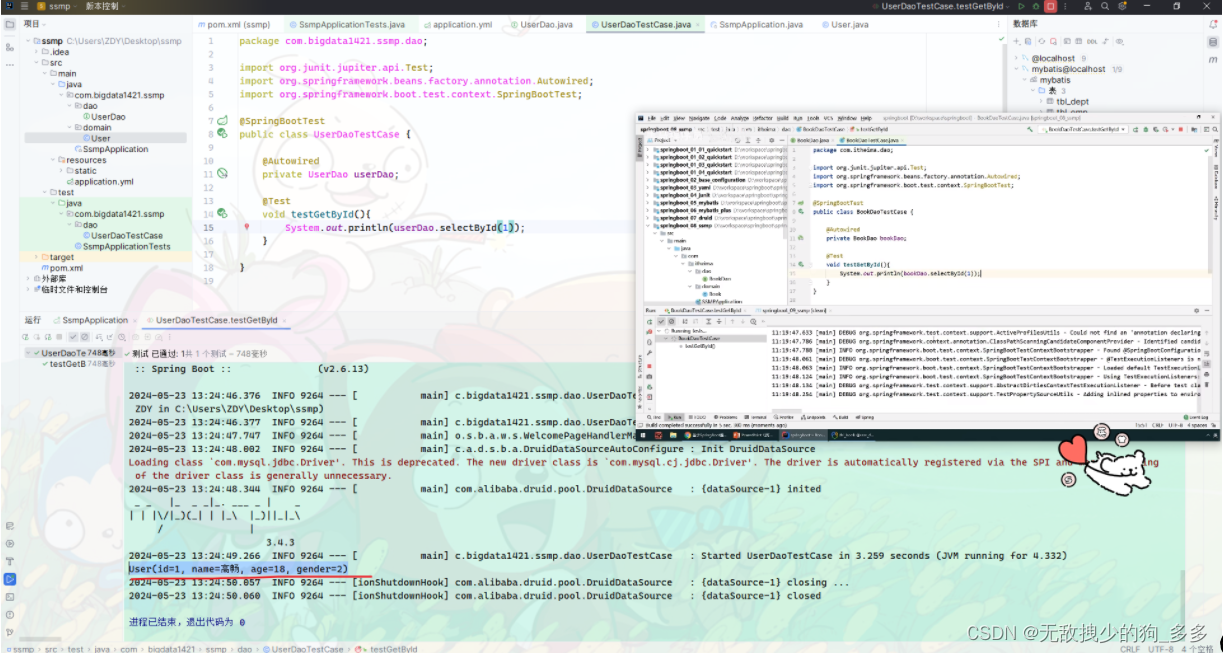
package com.bigdata1421.ssmp.dao;import com.bigdata1421.ssmp.domain.User;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;@SpringBootTest
public class UserDaoTestCase {@Autowiredprivate UserDao userDao;//根据ID查询@Testvoid testGetById(){System.out.println(userDao.selectById(1));}//增@Testvoid testSave(){User user=new User();user.setId(10);user.setName("李懿航");user.setAge(20);user.setGender(1);userDao.insert(user);}//改@Testvoid testUpdate(){User user=new User();user.setId(10);user.setName("李懿航");user.setAge(20);user.setGender(1);userDao.updateById(user);}//删@Testvoid testDelete(){userDao.deleteById(10);}//查询所有数据@Testvoid testGetAll(){System.out.println( userDao.selectList(null););}//分页查询@Testvoid testGetPage(){}//按条件查询@Testvoid testGetBy(){}}开发方案

小结
开启MP运行日志
在yml配置文件里配置mybatis的信息

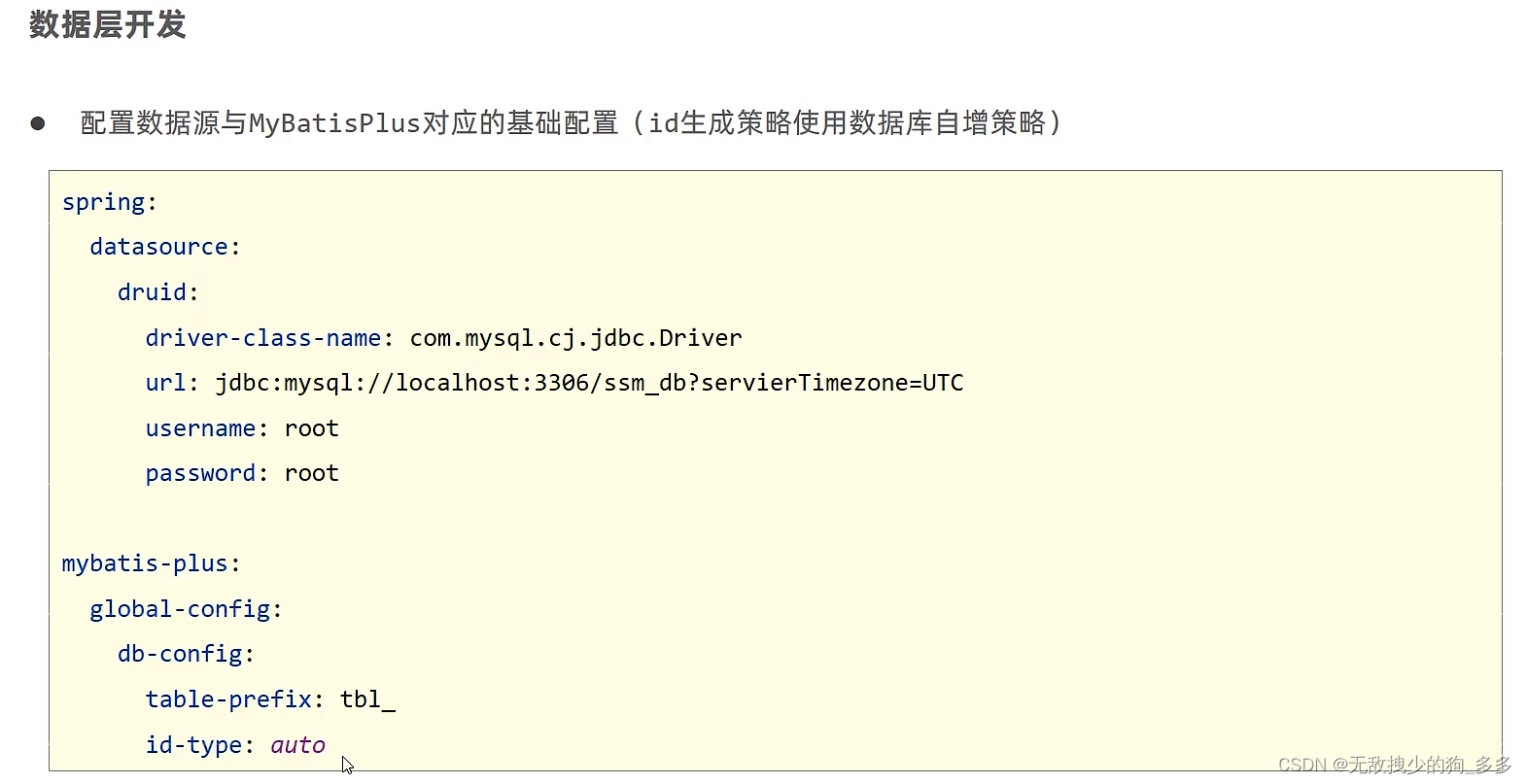
# 配置mybatis-plus
mybatis-plus:global-config:db—config:table-prefix: tbl_id-type: autoconfiguration:log-impl: org.apache.ibatis.logging.stdout.StdOutImpl在控制台输出打印日志


后面功能上线运行后可不能开启日志
这些操作只能是我们在调试的打开日志
便于我们查看信息
分页查询
分页查询怎么去做呢
我们的分页操作就是在原始的查询操作上挂上limit关键字

往SQL语句后面添加默认内容
所以我们要创建一个拦截器
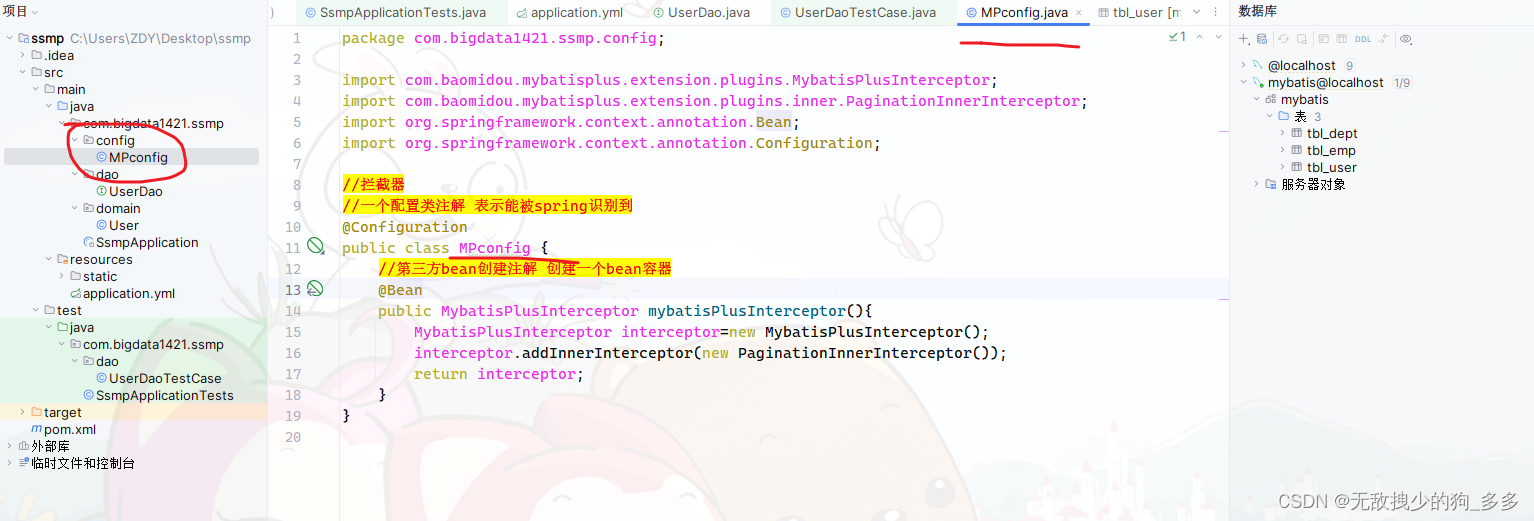
package com.bigdata1421.ssmp.config;import com.baomidou.mybatisplus.extension.plugins.MybatisPlusInterceptor;
import com.baomidou.mybatisplus.extension.plugins.inner.PaginationInnerInterceptor;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;//拦截器
//一个配置类注解 表示能被spring识别到
@Configuration
public class MPconfig {//第三方bean创建注解 创建一个bean容器@Beanpublic MybatisPlusInterceptor mybatisPlusInterceptor(){MybatisPlusInterceptor interceptor=new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor());return interceptor;}
}启动类所在包及其子包下的所有bean都会被识别加载
我们加了@Configuration注解 而且 放在启动类所在包及其子包下
所以能被扫描到
这样就能实现分页查询
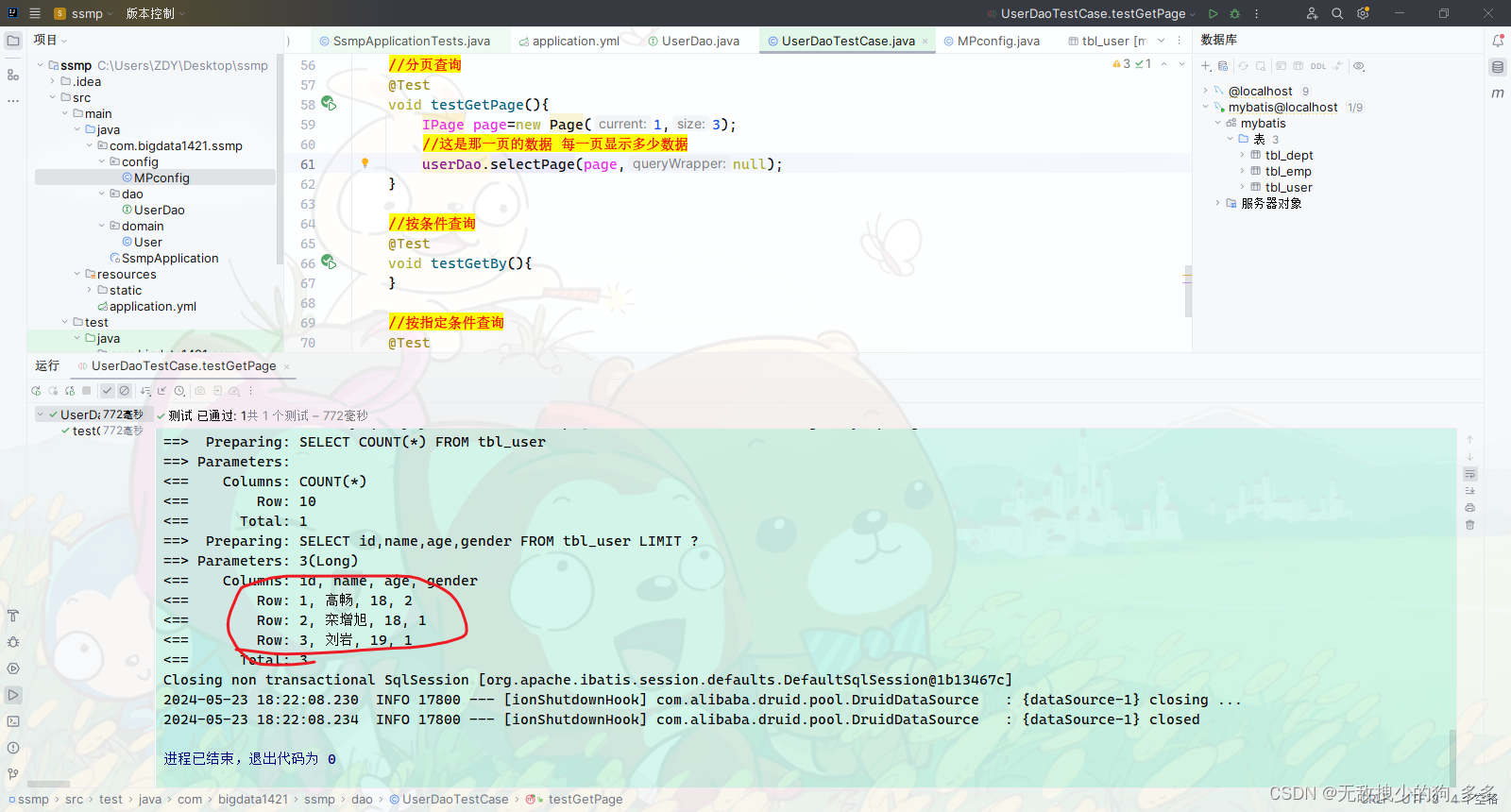
//分页查询
@Test
void testGetPage(){IPage page=new Page(1,3);//这是那一页的数据 每一页显示多少数据userDao.selectPage(page,null);
}
小结
完全就是一个固定格式
内部就是帮你去拼SQL

我们要在调试过程中去查看SQL语句
这样才能看见SQL语句动态变化

条件查询
//按条件查询
@Test
void testGetBy(){//容器QueryWrapper<User> qw=new QueryWrapper<>();//条件qw.like("name","高");//查询userDao.selectList(qw);
}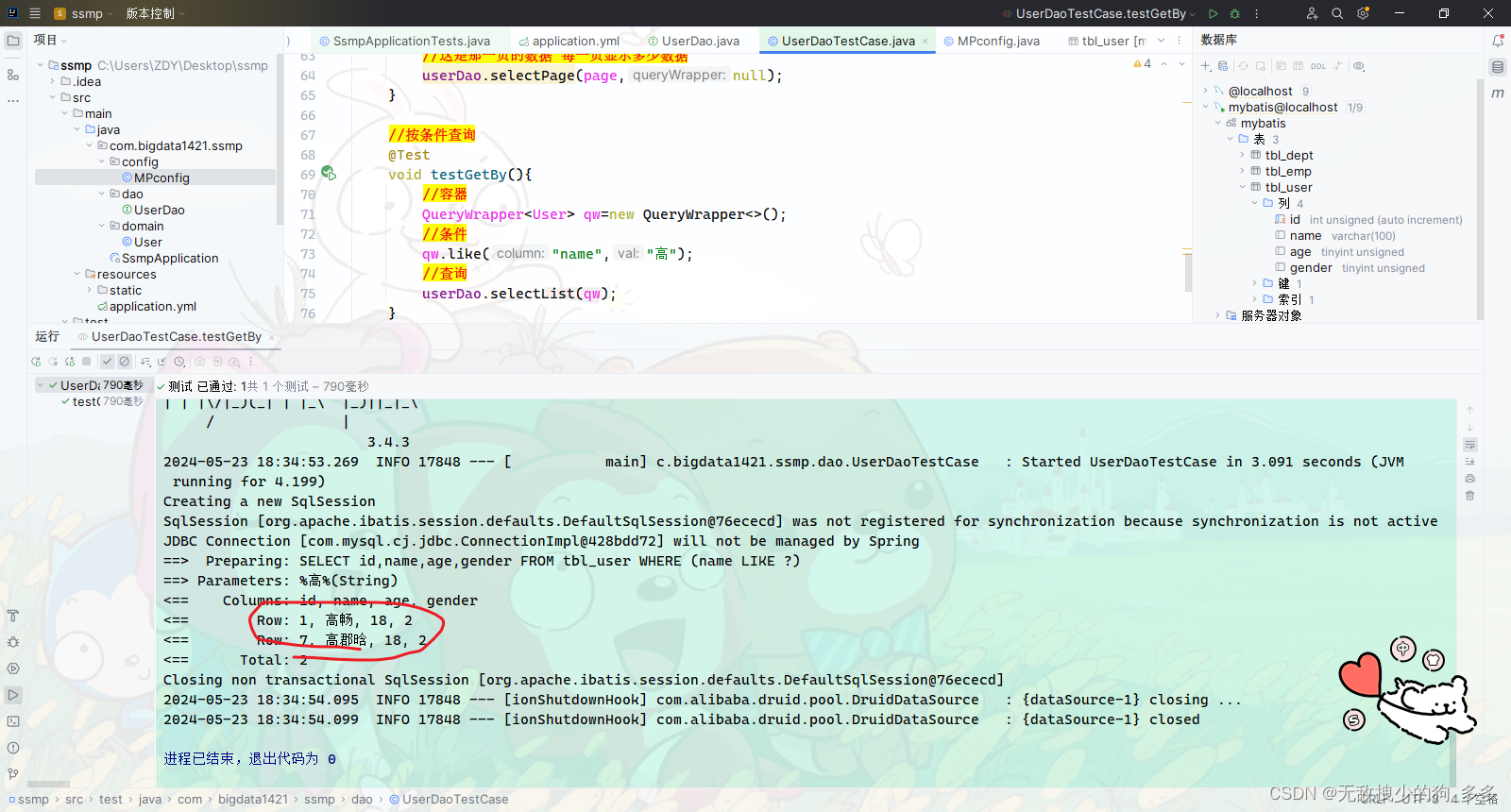
运行后我们主要看SQL语句和查询结果
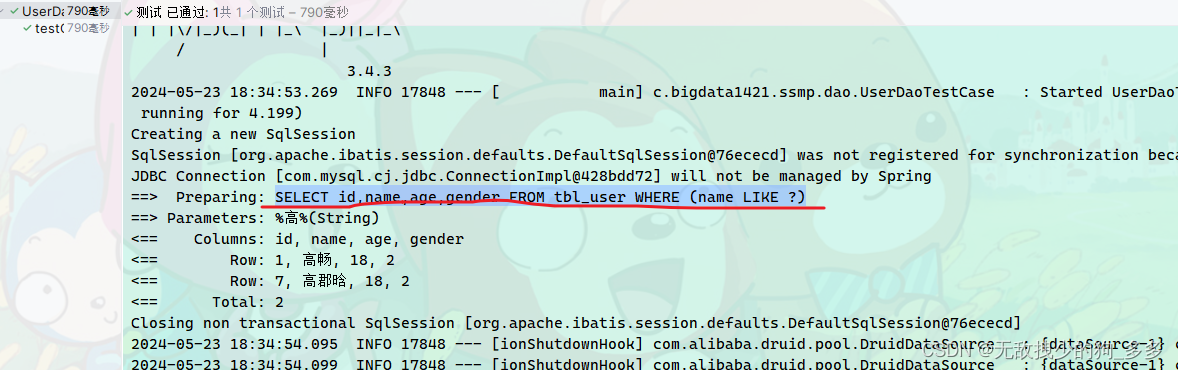
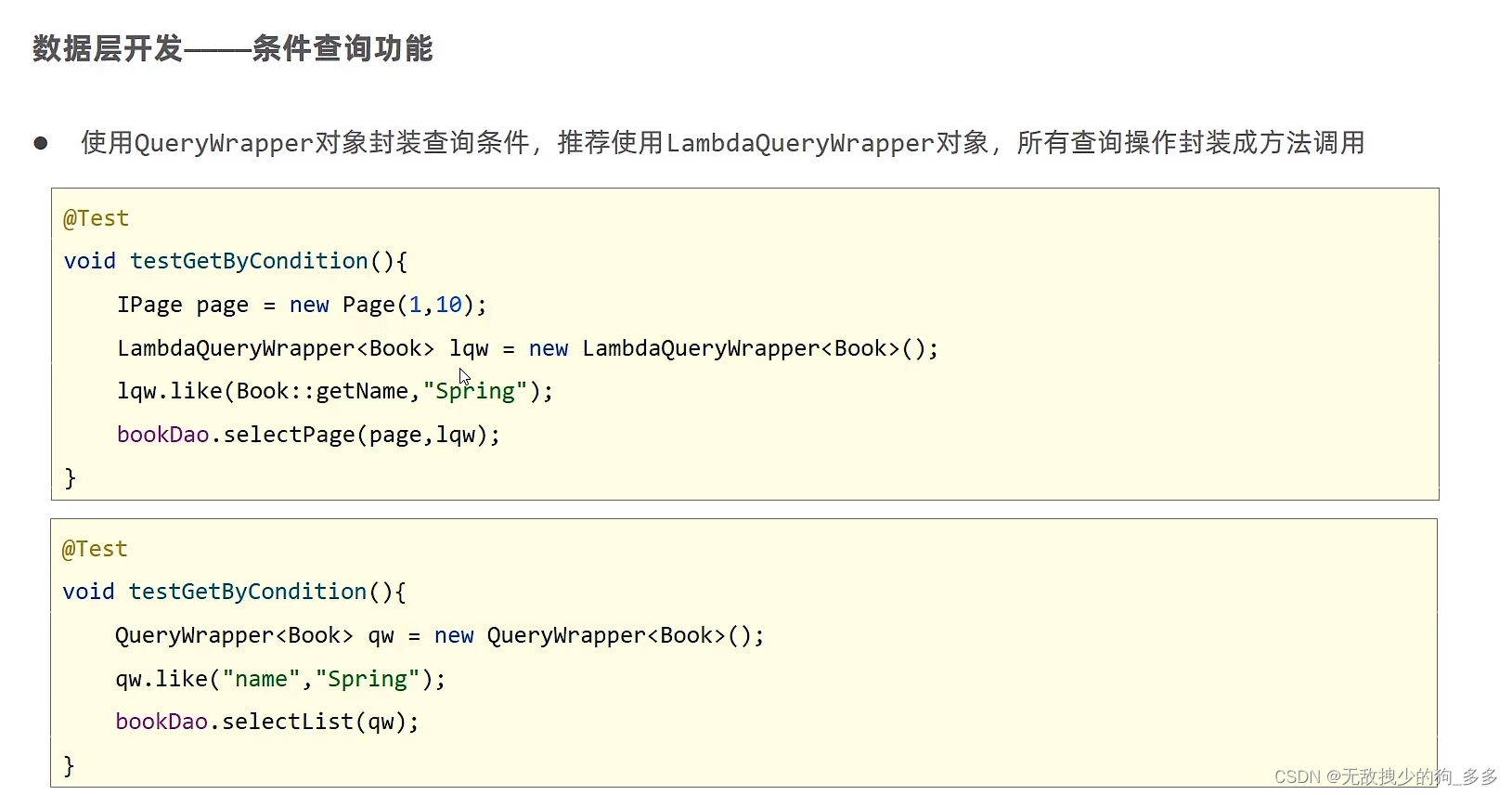
安全性高的写法
用方法引用去写
但是我们要提高Mybatis - plus 的版本
void testGetBy2(){// select * from tbl_ where name like %高%//容器QueryWrapper<User> qw2=new QueryWrapper<User>();//条件qw2.like(User::getName,"高");//查询userDao.selectList(qw2);
}以后

但是这种 如果传入的参数name是空
是会将 null 拼接到sql语句后进行查询的
这很显然不符合我们的规范
所以我们应该优化代码

小结


这篇关于SSMP整合案例第二步 数据层dao开发及实现特殊查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





