albert专题

翻译 Albert Julian Mayer 关于虚拟纹理的论文(3. 概述)
第3章:概述 本章介绍了整篇论文中使用的术语,并简要介绍了“虚拟纹理”及其挑战。 3.1 术语 目前,在纹理缓存领域存在术语不匹配的情况。一些论文将术语 “虚拟纹理” 应用于所有 “使用部分驻留在内存中的纹理的系统”,特别是类似 Clipmapping 的系统 [TSH09]、 [EC06]、 [Wei04]、 [SLT+07]。而其他论文和资源将这个术语应用于一种更新的、截然不同的大纹理支

翻译 Albert Julian Mayer 关于虚拟纹理的论文(1. 介绍)
译者前言 在搜寻关于虚拟纹理相关资料的时候,我发现了这篇论文: 这似乎是 维也纳科技大学计算机科学系 的学生 Albert Julian Mayer 的研究生学位论文。 这篇论文也出现在了 2014 GDC Adaptive Virtual Texture Rendering in Far Cry 4 的参考文献之中。 我希望通过翻译这篇论文来学习虚拟纹理的基础概念等知识。 摘要 在实时

albert每两层共享参数
1、albert的原始实现(brightmart实现) def transformer_model(input_tensor,attention_mask=None,hidden_size=768,num_hidden_layers=12,num_attention_heads=12,intermediate_size=3072,intermediate_act_fn=gelu,hidden_d

60分钟带你了解ALBERT
ALBERT原文:《ALITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS》 中文预训练ALBERT模型来了:小模型登顶GLUE,Base版模型小10倍速度快1倍。 Google一出手就是不一样,不再是BERT+的模式,而是做了个大改动。ALBERT模型是BERT的改进版,与最近其他State of the art
第9章: ALBERT Pre-training模型及Fine-tuning源码完整实现、案例及调试
1,Corpus数据分析 2,Pre-training参数设置分析 3,BasicTokenizer源码实现 4,WordpieceTokenizer源码实现 5,ALBERT的Tokenization完整实现源码 6,加入特殊Tokens CLS和SEP 7,采用N-gram的Masking机制源码完整实现及测试 8,Padding操作源码 9,Sentence-Pair数据预处

第8章: 轻量级ALBERT模型剖析及BERT变种中常见模型优化方式详解
1,从数学原理和工程实践的角度阐述BERT中应该设置Hidden Layer的维度高于(甚至是高几个数量级)Word Embeddings的维度背后的原因 2,从数学的角度剖析Neural Networks参数共享的内幕机制及物理意义 3,从数学的角度剖析Neural Networks进行Factorization的机制及物理意义 4,使用Inter-sentence coherence
基于albert的汽车评论情感分析【含代码】
汽车评论情感分析 汽车评论情感数据集代码加载库与参数设置数据集的读取超参数设置与数据集的构建模型的训练与验证 汽车评论情感数据集 链接:https://pan.baidu.com/s/1K5TWrXbXBRXkCUpMbZq2XA 提取码:9mt9 代码 加载库与参数设置 首先先把一些基础的库进行加载 import randomimport torchfrom to

ALBERT: 自监督语言表示的轻量级BERT
文章目录 引言词向量因式分解(Factorized embedding parameterization)跨层参数共享(Cross-layer parameter sharing)内部句子一致性损失(Inter-sentence coherence loss) 【Reference】 ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING

ALBERT:A LITE BERT FOR SELF-SUPERVISED LEAARNINGOF LANGUAGE REPRESENTATIONS
ABSTRACT Increasing model size when pretraining natural language representations often results in improved performance on downstream tasks. 预训练自然语言表示的时候,增加模型的大小经常导致下游任务的表现提升。 However,at some point fur
ALBERT 论文+代码笔记
Paper:1909.11942.pdf Code:google-research/albert: ALBERT: A Lite BERT for Self-supervised Learning of Language Representations 核心思想:基于 Bert 的改进版本:分解 Embedding 参数、层间参数共享、SOP 替代 NSP。 What 动机和核心问题 大模型有好
BERT和ALBERT的区别;BERT和RoBERTa的区别;与bert相关的模型总结
一.BERT和ALBERT的区别: BERT和ALBERT都是基于Transformer的预训练模型,它们的几个主要区别如下: 模型大小:BERT模型比较大,参数多,计算资源消耗较大;而ALBERT通过技术改进,显著减少了模型的大小,降低了计算资源消耗。 参数共享:ALBERT引入了跨层参数共享机制,即在整个模型的所有层中,隐藏层的参数是共享的,也就是说每一层都使用相同的参数。相比之下,B

6.4 ALBERT全面理解
文章目录 1简介2相关工作2.1扩大自然语言的表征学习2.2跨层参数共享2.3句子排序目标 3 ALBERT基本原理3.1模型架构选择分解式嵌入参数化跨层参数共享句子顺序预测3.2模型设置 4实验结果4.1实验装置4.2评价基准4.2.1内在准备评估4.2.2下游评价 4.3 BERT和ALBERT的总体比较4.4因式分解嵌入参数化4.7如果我们训练同样的时间呢? 5讨论参考 在预
BERT变体(1):ALBERT、RoBERTa、ELECTRA、SpanBERT
Author:龙箬 Computer Application Technology Change the World with Data and Artificial Intelligence ! CSDN@weixin_43975035 *天下之大,虽离家万里,何处不可往!何事不可为! 1. ALBERT \qquad ALBERT的英文全称为A Lite version of BE
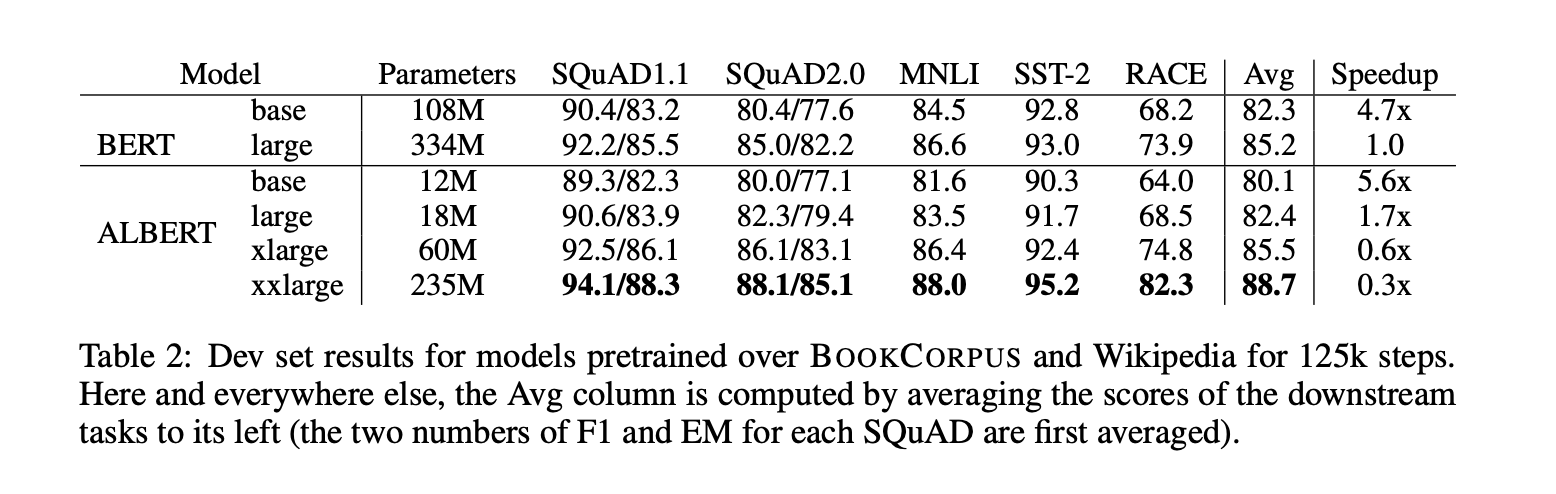
ALBERT-更小更少但并不快
BERT模型的压缩大致可以分为:1. 参数剪枝;2. 知识蒸馏;3. 参数共享;4. 低秩分解。 其中,对于剪枝,比较简单,但是容易误操作降低精读; 对于知识蒸馏,之前我写个一系列的文章,重点可以看一下这里: 对于参数共享和低秩分解,就和今天分享的ALBERT息息相关; 它减少了BERT的参数,但是需要注意的一个细节点是,同等规格下,ALBERT速度确实变快,但是并不明显(和大量自媒体文章