akka专题

Akka-路由模式Group/Pool
为了文章好理解,我们先统一一下概念,在Akka中,Actor是一个高度抽象的概念,Akka的路由器也是一个Actor,所以我们把路由器,叫做路由Actor,接收消息(消费消息)的Actor,在本文中我们叫做消息Actor Akka中有两种路由模式,分别是Group模式和Pool模式,如果我要将消息X通过路由Actor发送到多台机器,那么: Pool: 在多台机器上,每台机器上的消息Actor都是

使用Akka来优化Spark+ElasticSearch的准实时系统
假如有这样一个场景:系统每秒钟都会收到大量的事件,每个事件又包含很多参数,用户不仅需要准实时地还需要定期地判断每一种事件、事件的每一种参数值的组合是否超过了系统设定的阈值。面对这一场景,用户应该采用什么样的方案呢?最近,来自于 Premium Minds 的软件架构师 André Camilo 在博客上发表了一篇文章,介绍了他们是 如何使用Akka解决这一棘手问题的 。 在该文章中André C
akka.io的基本用法
akka.io的api已经非常非常简单了, 实在很难挑剔. 如果用它来做单进程的游戏服务器, 基本上分成三个步骤就可以完成了. 1. akka.io的环境初始化, 包括了tcp extension的初始化. 2. 绑定一个端口, 并将这个端口上的事件交给某个actor处理, 如连接到来事件. 3. 有连接到来时将其指派给某个业务actor处理, 接下来这个业务actor就负责自己身

基于akka与scala实现一个简单rpc框架
一、RPC简介 RPC,即 Remote Procedure Call(远程过程调用),说得通俗一点就是:调用远程计算机上的服务,就像调用本地服务一样。 RPC 可基于 HTTP 或 TCP 协议,Web Service 就是基于 HTTP 协议的 RPC,它具有良好的跨平台性,但其性能却不如基于 TCP 协议的 RPC。会两方面会直接影响 RPC 的性能,一是传输方式,二是序列化

Scala语法(六) Akka与线程通信
前言 在初期, Scala可以通过Akka来实现线程通信. 当然, 现在还支持使用Netty方式进行通信. 本章主要介绍使用Akka方式进行通信的写法. 正文 Master结点 import akka.actor.Actorimport akka.actor.ActorSystemimport com.typesafe.config.ConfigFactoryimport a
基于Akka的RPC通信
1. 并发编程 在 Java 中,多线程访问共享数据的时候会存在【线程安全】问题Scala 的多线程使用了新的通信机制 通过发送消息来通信,没有了共享数据,从而实现并发编程Scala 使用的是 Akka 框架,Akka 通过 Actor 模式实现高并发 Akka 是使用 Scala 语言编写的用法高并发的编程框架Akka 的高并发是由 Actor 与 Actor 之间的通信Akka 模型 消息传
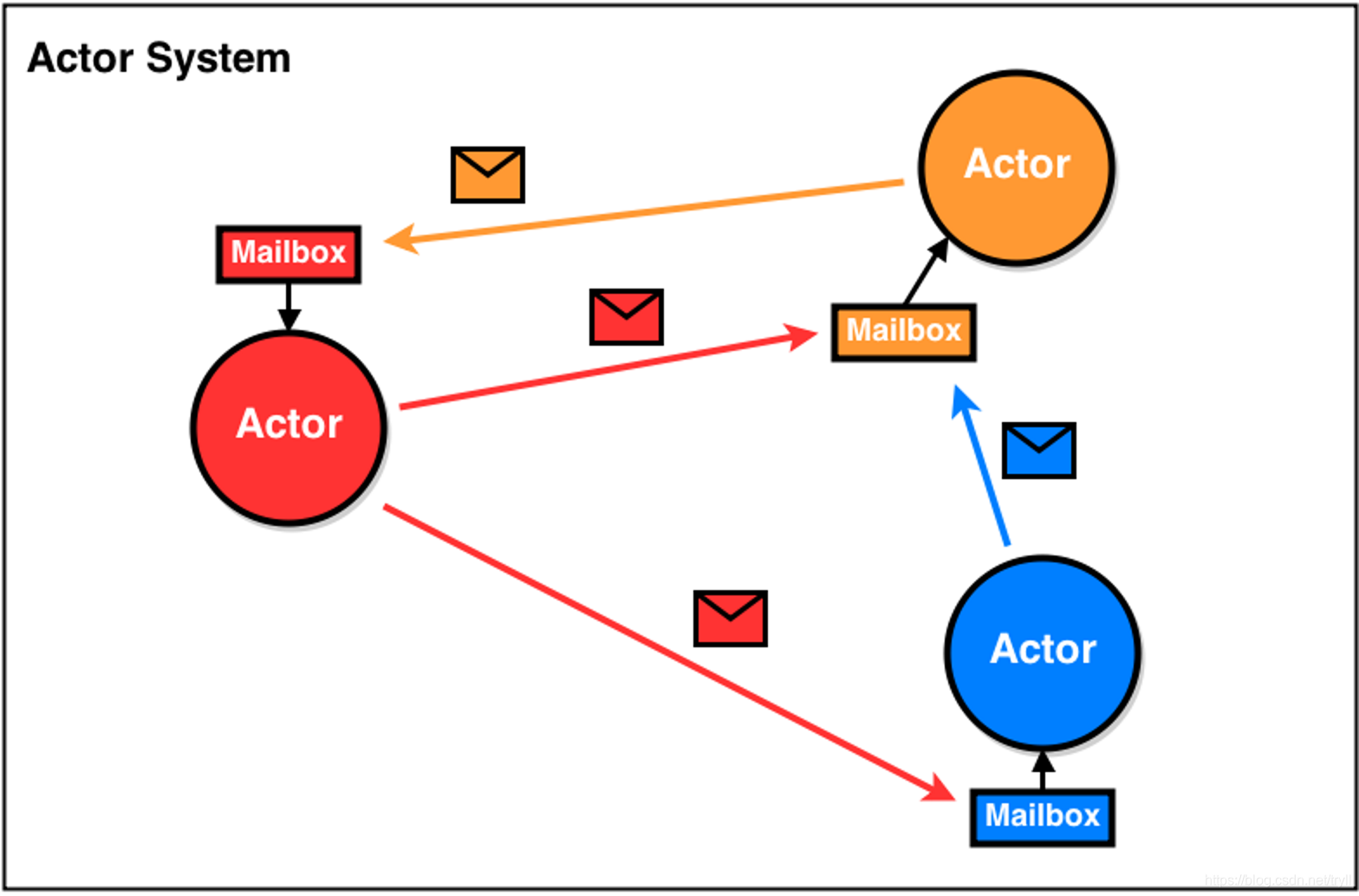
Akka 并发编程简述
概述 Akka官方网址:https://akka.io/ Akka是一个构建在JVM上,基于Actor模型的的并发框架,为构建伸缩性强,有弹性的响应式并发应用提高更好的平台 Akka解决了什么问题? 传统的处理并发思路是多线程处理,为了保证数据一致性和正确性,最通常的方法就是使用锁。通过加锁可以保证同一时刻只有一个线程能进入该方法,但这是一个代价非常昂贵的方法: 这些现实
akka 消息 not delivered deadletter
最近在学习akka,写了个特别简单的helloword例子,但是从local给remote发消息的时候总是提示 message not delivered,找了很长时间才发现导致这个问题的原因,我的错误源于在local 获取remote 的引用的时候,路径中的 val worker1 = context.actorSelection("akka.tcp://Worker1@10.175.37
akka remote
http://www.soso.io/article/8715.html Akka的设计目标就是为分布式准备的,因此所有Actor之间的交互都是通过消息,且所有动作都是异步的。这种做法就是为了确保Akka的所有功能无论是在单独的JVM,还是包含了成百上千机器的Cluster,都是可用的。 然而,本地与分布式总是存在区别,主要牵涉到两点: 消息需要支持序列号; 消息传递的可靠性问题; 为了
SDP(0):Streaming-Data-Processor - Data Processing with Akka-Stream
再有两天就进入2018了,想想还是要准备一下明年的工作方向。回想当初开始学习函数式编程时的主要目的是想设计一套标准API給那些习惯了OOP方式开发商业应用软件的程序员们,使他们能用一种接近传统数据库软件编程的方式来实现多线程,并行运算,分布式的数据处理应用程序,前提是这种编程方式不需要对函数式编程语言、多线程软件编程以及集群环境下的分布式软件编程方式有很高的经验要求。前面试着发布了一个基于s
Akka(43): Http:SSE-Server Sent Event - 服务端主推消息
因为我了解Akka-http的主要目的不是为了有关Web-Server的编程,而是想实现一套系统集成的api,所以也需要考虑由服务端主动向客户端发送指令的应用场景。比如一个零售店管理平台的服务端在完成了某些数据更新后需要通知各零售门市客户端下载最新数据。虽然Akka-http也提供对websocket协议的支持,但websocket的网络连接是双向恒久的,适合频繁的问答交互式服务端与客户端的
Akka(42): Http:身份验证 - authentication, authorization and use of raw headers
当我们把Akka-http作为数据库数据交换工具时,数据是以Source[ROW,_]形式存放在Entity里的。很多时候除数据之外我们可能需要进行一些附加的信息传递如对数据的具体处理方式等。我们可以通过Akka-http的raw-header来实现附加自定义消息的传递,这项功能可以通过Akka-http提供的raw-header筛选功能来实现。在客户端我们把附加消息放在HttpReques
Akka(41): Http:DBTable-rows streaming - 数据库表行交换
在前面一篇讨论里我们介绍了通过http进行文件的交换。因为文件内容是以一堆bytes来表示的,而http消息的数据部分也是byte类型的,所以我们可以直接用Source[ByteString,_]来读取文件然后放进HttpEntity中。我们还提到:如果需要进行数据库数据交换的话,可以用Source[ROW,_]来表示库表行,但首先必须进行ROW -> ByteString的转换。在上期讨论我
Akka(40): Http:Marshalling reviewed - 传输数据序列化重温
上篇我们讨论了Akka-http的文件交换。由于文件内容编码和传输线上数据表达型式皆为bytes,所以可以直接把文件内容存进HttpEntity中进行传递。那么对于在内存里自定义的高级数据类型则应该需要首先进行byte转换后才能放入HttpEntity中了。高级数据类型与byte之间的相互转换就是marshalling和unmarshalling过程了。这个我们在前几篇讨论里提及过,在本篇再
Akka(39): Http:File streaming-文件交换
所谓文件交换指的是Http协议中服务端和客户端之间文件的上传和下载。Akka-http作为一种系统集成工具应该具备高效率的数据交换方式包括文件交换和数据库表行的上传下载。Akka-http的数据交换模式支持流式操作:代表交换数据可以是一种无限长度流的元素。这种模式首先解决了纯Http大数据通过Multipart传输所必须进行的数据分段操作和复杂的消息属性设定等需要的技术门槛,再者用户还可以很方
Akka(38): Http:Entityof ByteString-数据传输基础
我们说过Akka-http是一个好的系统集成工具,集成是通过数据交换方式实现的。Http是个在网上传输和接收的规范协议。所以,在使用Akka-http之前,可能我们还是需要把Http模式的网上数据交换细节了解清楚。数据交换双方是通过Http消息类型Request和Response来实现的。在Akka-http中对应的是HttpRequest和HttpResponse。这两个类型都具备HttpE

Akka(37): Http:客户端操作模式
Akka-http的客户端连接模式除Connection-Level和Host-Level之外还有一种非常便利的模式:Request-Level-Api。这种模式免除了连接Connection的概念,任何时候可以直接调用singleRequest来与服务端沟通。下面我们用几个例子来示范singleRequest的用法: (for {response <- Http().single
Akka(36): Http:Client-side-Api,Client-Connections
Akka-http的客户端Api应该是以HttpRequest操作为主轴的网上消息交换模式编程工具。我们知道:Akka-http是搭建在Akka-stream之上的。所以,Akka-http在客户端构建与服务器的连接通道也可以用Akka-stream的Flow来表示。这个Flow可以通过调用Http.outgoingConnection来获取: /*** Creates a [[a
Akka(35): Http:Server side streaming
在前面几篇讨论里我们都提到过:Akka-http是一项系统集成工具库。它是以数据交换的形式进行系统集成的。所以,Akka-http的核心功能应该是数据交换的实现了:应该能通过某种公开的数据格式和传输标准比较方便的实现包括异类系统之间通过网上进行的数据交换。覆盖包括:数据编码、发送和数据接收、解析全过程。Akka-http提供了许多网上传输标准数据的概括模型以及数据类型转换方法,可以使编程人员
akka-streams - 从应用角度学习:basic stream parts
实际上很早就写了一系列关于akka-streams的博客。但那个时候纯粹是为了了解akka而去学习的,主要是从了解akka-streams的原理为出发点。因为akka-streams是akka系列工具的基础,如:akka-http, persistence-query等都是基于akka-streams的,其实没有真正把akka-streams用起来。这段时间所遇到的一些需求也是通过集合来解决
akka-grpc - 应用案例
上期说道:http/2还属于一种不算普及的技术协议,可能目前只适合用于内部系统集成,现在开始大面积介入可能为时尚早。不过有些项目需求不等人,需要使用这项技术,所以研究了一下akka-grpc,写了一篇介绍。本想到此为止,继续其它项目。想想这样做法有点不负责任,像是草草收场。毕竟用akka-grpc做了些事情,想想还是再写这篇跟大家分享使用kka-grpc的过程。 我说过,了解akka-grp
akka-grpc - 基于akka-http和akka-streams的scala gRPC开发工具
关于grpc,在前面的scalaPB讨论里已经做了详细的介绍:google gRPC是一种全新的RPC框架,在开源前一直是google内部使用的集成工具。gRPC支持通过http/2实现protobuf格式数据交换。protobuf即protocol buffer,是google发明的一套全新的序列化传输协议serialization-protocol,是二进制编码binary-encoded的
akka-typed(9) - 业务分片、整合,谈谈lagom, 需要吗?
在讨论lagom之前,先从遇到的需求开始介绍:现代企业的it系统变得越来越多元化、复杂化了。线上、线下各种系统必须用某种方式集成在一起。从各种it系统的基本共性分析:最明显的特征应该是后台数据库的角色了,起码,大家都需要使用数据。另外,每个系统都可能具备大量实时在线用户、海量数据特性,代表着对数据处理能力有极大的要求,预示系统只有通过分布式处理方式才能有效运行。 一个月前开始设计一个企业的i
akka-typed(8) - CQRS读写分离模式
前面介绍了事件源(EventSource)和集群(cluster),现在到了讨论CQRS的时候了。CQRS即读写分离模式,由独立的写方程序和读方程序组成,具体原理在以前的博客里介绍过了。akka-typed应该自然支持CQRS模式,最起码本身提供了对写方编程的支持,这点从EventSourcedBehavior 可以知道。akka-typed提供了新的EventSourcedBehavior