accelerate专题
accelerate 笔记:对齐不同设备配置的性能
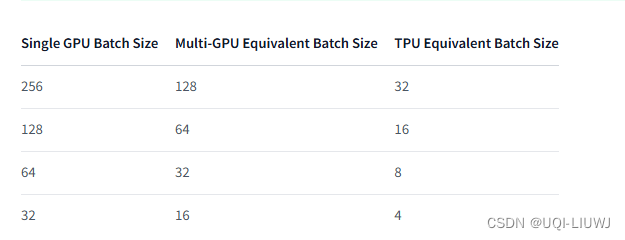
在TPU、多GPU和单GPU上使用accelerate运行相同的脚本和相同的batch_size,可能结果是不一样的那应该怎么做呢? 1 设置正确的种子 确保在所有分布式情况下使用 utils.set_seed() 完全设置种子,以使训练可复现 from accelerate.utils import set_seedset_seed(42) acclerate的设置随机种子涵盖了5种不同
Accelerate 笔记:保存与加载文件
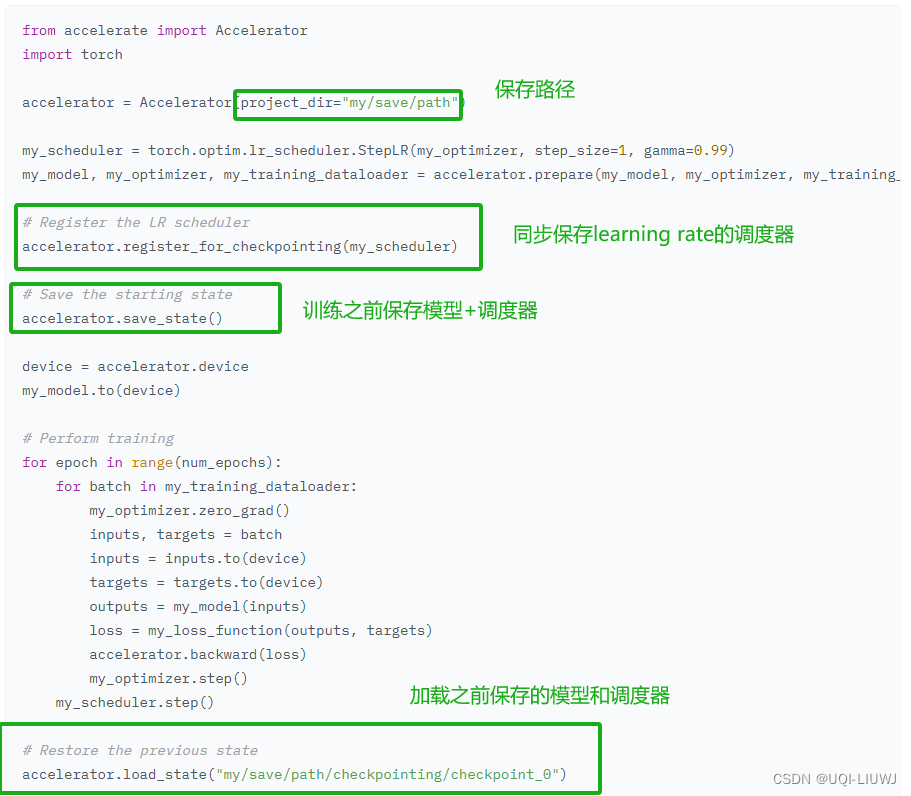
保存和加载模型、优化器、随机数生成器和 GradScaler 使用 save_state() 将上述所有内容保存到一个文件夹位置使用 load_state() 加载之前通过 save_state() 保存的状态通过使用 register_for_checkpointing(),可以注册自定义对象以便自动从前两个函数中存储或加载 只要对象具有 state_dict 和 load_state_dict

accelerate笔记:实验跟踪
Accelerate支持七种集成的跟踪器: TensorBoardWandBCometMLAimMLFlowClearMLDVCLive要使用这些跟踪器,可以通过在 Accelerator 类的 log_with 参数中传入所选类型来实现 from accelerate import Acceleratorfrom accelerate.utils import LoggerTypeaccel

huggingface笔记:使用accelerate加速
1 介绍 随着模型规模的增大,并行处理已成为在有限硬件上训练大型模型和提高训练速度的重要策略。Hugging Face 创建了Accelerate库,帮助用户在任何类型的分布式环境中轻松训练Transformers模型,无论是单机多GPU还是跨多机的多GPU 2 创建Accelerator对象 from accelerate import Acceleratoraccelerator

PyTorch——利用Accelerate轻松控制多个CPU/GPU/TPU加速计算
PyTorch——利用Accelerate轻松控制多个CPU/GPU/TPU加速计算 前言官方示例单个程序内控制多个CPU/GPU/TPU简单说一下设备环境导包加载数据 FashionMNIST创建一个简单的CNN模型训练函数-只包含训练训练函数-包含训练和验证训练 多个服务器、多个程序间控制多个CPU/GPU/TPU参考链接 前言 CPU?GPU?TPU? 计算设备太多,很混

pytorch 多卡训练 accelerate gloo
目录 accelerate 多卡训练 Windows例子 gloo 多卡训练 accelerate 多卡训练 Windows例子 import torchfrom torch.nn.parallel import DistributedDataParallel as DDPfrom torch.utils.data import DataLoader, RandomSample

LLM 分布式训练框架 | DeepSpeed与Accelerate
🚀 简单记录下根据网上资料(如Reference中所列)所学到的一些知识,这里主要介绍的是deepspeed分布式训练框架相关概念。 😄小日记:今天太舒服了,早上跑了6km,晚上吃了养生菌菇火锅~ 文章目录 1、Accelerate和deepspeed的联系2、基本概念3、通信策略4、Zero(ZeRO-Stage3、ZeRO-Offload)4.1、ZeRO中不同stage的区

使用Accelerate库在多GPU上进行LLM推理
大型语言模型(llm)已经彻底改变了自然语言处理领域。随着这些模型在规模和复杂性上的增长,推理的计算需求也显著增加。为了应对这一挑战利用多个gpu变得至关重要。 所以本文将在多个gpu上并行执行推理,主要包括:Accelerate库介绍,简单的方法与工作代码示例和使用多个gpu的性能基准测试。 本文将使用多个3090将llama2-7b的推理扩展在多个GPU上 基本示例 我们首先介

rwkv模型lora微调之accelerate和deepspeed训练加速
目录 一、rwkv模型简介 二、lora原理简介 三、rwkv-lora微调 1、数据整理 2、环境搭建 a、Dockerfile编写 b、制造镜像 c、容器启动 3、训练代码修改 四、模型推理 1、模型推理 2、lora权重合并 3、推理web服务 五、总结 由于业务采用的ChatGLM模型推理成本太大了,希望降低模型推理成

用swift和Accelerate的快速傅里叶变换(FFT)来实现对波形的整形
创建 Accelerate 的原型 -- 经过优化的信号处理 源: http://www.objccn.io/issue-16-5/ 由于使用 Cocoa 框架能够快速地创建一个可用的应用,这让许多开发者都喜欢上了 OS X 或 iOS 开发。如今即使是小团队也能设计和开发复杂的应用,这很大程度上要归功于这些平台所提供的工具和框架。Swift 的 Playground 不仅继承了快速

使用hugging face开源库accelerate进行多GPU训练(单机多卡)时,在保存模型结构的时候出现的问题
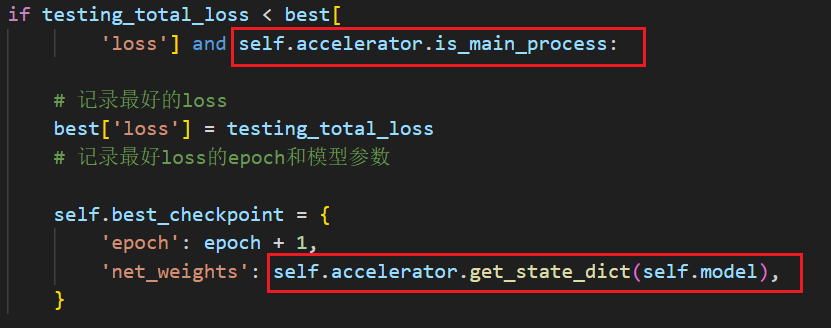
目录 问题描述问题分析问题解决 问题描述 我在保存模型结构的时候,先获取模型参数,然后再保存,代码如下: 图示代码是在训练主循环中的: 这种情况下会出现报错: nboundLocalError: UnboundLocalErrorlocal variable 'epoch checkpoint’referenced before assignment: 完整报错:
使用hugging face开源库accelerate进行多GPU(单机多卡)训练卡死问题
目录 问题描述及配置网上资料查找1.tqdm问题2.dataloader问题3.model(input)写法问题4.环境变量问题 我的卡死问题解决方法 问题描述及配置 在使用hugging face开源库accelerate进行多GPU训练(单机多卡)的时候,经常出现如下报错 [E ProcessGroupNCCL.cpp:828] [Rank 1] Watchdog caug