70b专题

sqlcoder:7b sqlcoder:15b sqlcoder:70b 有什么区别呢?
sqlcoder:7B, sqlcoder:15B, 和 sqlcoder:70B 是不同规模的语言模型,具有不同数量的参数(B 代表 billion,即十亿)。以下是它们的主要区别及各自的优势: 模型规模 sqlcoder:7B: 参数数量:7 亿。优点:资源消耗较少,适合在资源有限的硬件上运行,响应速度较快。缺点:生成的查询质量和复杂性可能较低,适用于简单的 SQL 转换任务。 sql
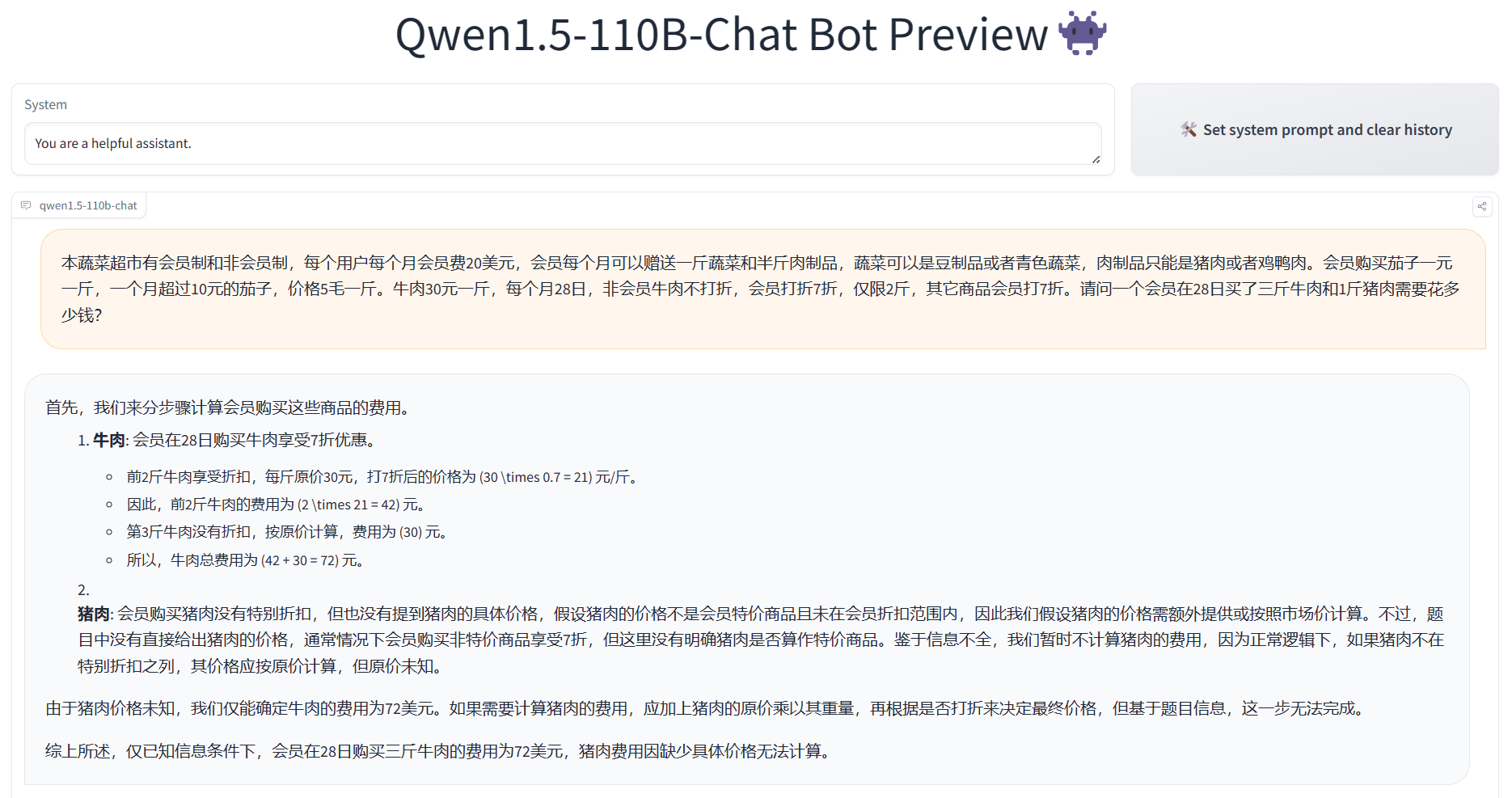
阿里开源截止目前为止参数规模最大的Qwen1.5-110B模型:MMLU评测接近Llama-3-70B,略超Mixtral-8×22B!
本文原文来自DataLearnerAI官方网站:阿里开源截止目前为止参数规模最大的Qwen1.5-110B模型:MMLU评测接近Llama-3-70B,略超Mixtral-8×22B! | 数据学习者官方网站(Datalearner)https://www.datalearner.com/blog/1051714140775766 Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为

一键部署 Llama3 8B/70B!最高仅占1.07GB存储;COCONut上线,字节跳动推出的首个大规模全景图像分割数据集
近日,Meta 震撼发布了号称「开源 GPT-4」的大模型 Llama3,该模型惊动了整个 AI 圈,HyperAI超神经也迫不及待想要体验一下!hyper.ai 官网现已在公共教程上线「一键部署 Llama3」! 有没有人和我一样激动的搓手手?赶紧来运行一下~ 4 月 22 日-4 月 26 日,hyper.ai 官网更新速览: 优质公共数据集:10 个 优质教程精选:3 个 社区文章
一周速览|极速体验 Llama3!70B 模型仅占 1.07 GB 内存、性能炸裂!
公共资源速递 This Weekly Snapshots ! 5 个数据集: * 老乡鸡菜品溯源报告 * Quora 文本分类研究数据集 * dmsc_v2 电影评论数据集 * 15 个动物图像分类数据集 * TriviaQA 用于阅读理解和问答的大型数据集 3 个模型: * Llama3-8B-instruct * Llama3-70B * FuseChat-7B-VaR

6种免费使用Llama3 70B的方法及英伟达提供的免费API接口调用!
作者:Aitrainee | AI进修生 排版太难了,请点击这里查看原文:6种免费使用Llama3 70B的方法及英伟达提供的免费API接口调用! Llama3 70B简介 Llama 3的发布引起了行业内的轩然大波。不久前,很多人还认为“闭源模型通常优于开源模型”。然而,最新的大型语言模型排行榜已经清楚地向公众展示了这一新趋势。Meta的CEO马克·扎克伯格宣布,基于Llama
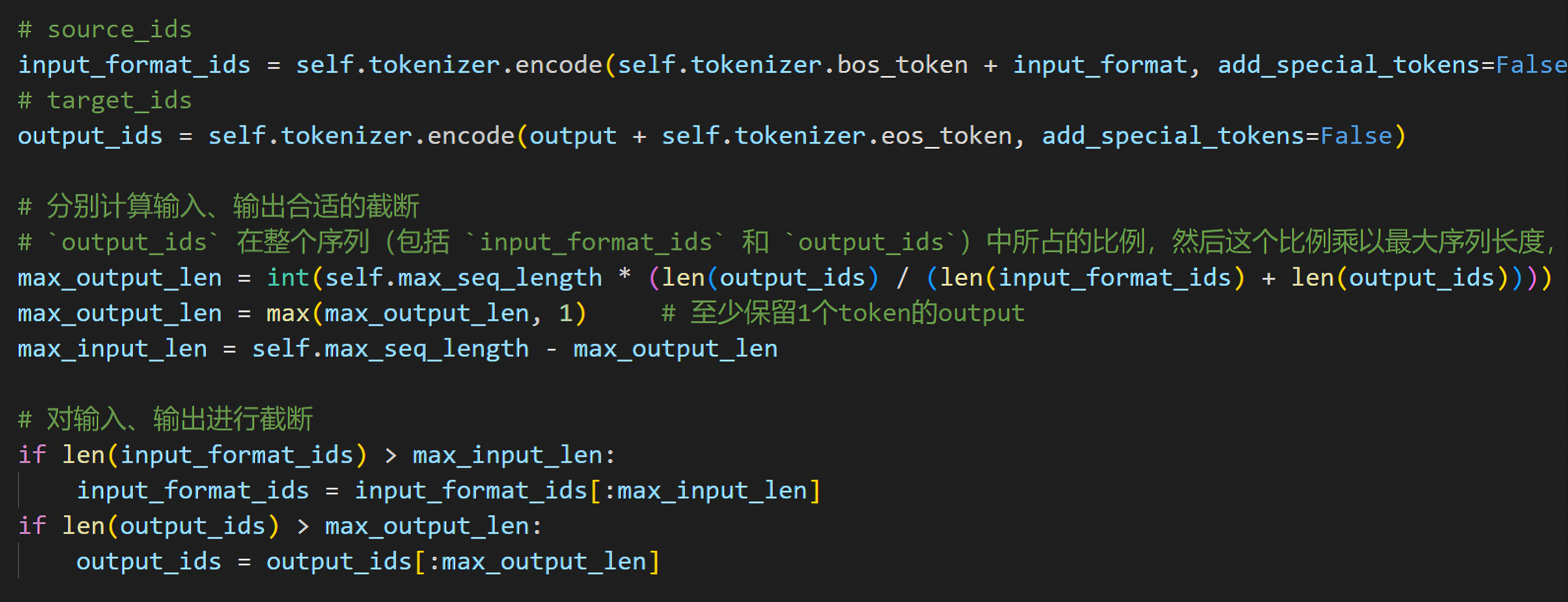
七月论文审稿GPT第4.5版:通过15K条paper-review数据微调Llama2 70B(含各种坑)
前言 当我们3月下旬微调完Mixtral 8x7B之后(更多详见:七月论文大模型:含论文的审稿、阅读、写作、修订 ),下一个想微调的就是llama2 70B 因为之前积攒了不少微调代码和微调经验,所以3月底apple便通过5K的paper-review数据集成功微调llama2 70B,但过程中也费了不少劲考虑到最后的成功固然令人欣喜,但真正让一个人或一个团队快速涨经验的还是那些在训练过程中走
本地部署 Meta Llama3-8b 和 Llama3-70b
本地部署 Meta Llama3-8b 和 Llama3-70b 0. 引言1. Meta对Llama 3的目标2. Llama 3的性能3. 下载和安装 Ollama4. 使用 Ollama 运行 Llama3 0. 引言 今天,Meta 正式介绍Meta Llama 3,Meta 开源大型语言模型的下一代产品。 这次发布包括具有80亿(8B)和700亿(70B)参数的预训

您现在可以在家训练 70b 语言模型
原文:Answer.AI - You can now train a 70b language model at home 我们正在发布一个基于 FSDP 和 QLoRA 的开源系统,可以在两个 24GB GPU 上训练 70b 模型。 已发表 2024 年 3 月 6 日 概括 今天,我们发布了 Answer.AI 的第一个项目:一个完全开源的系统,首次可以
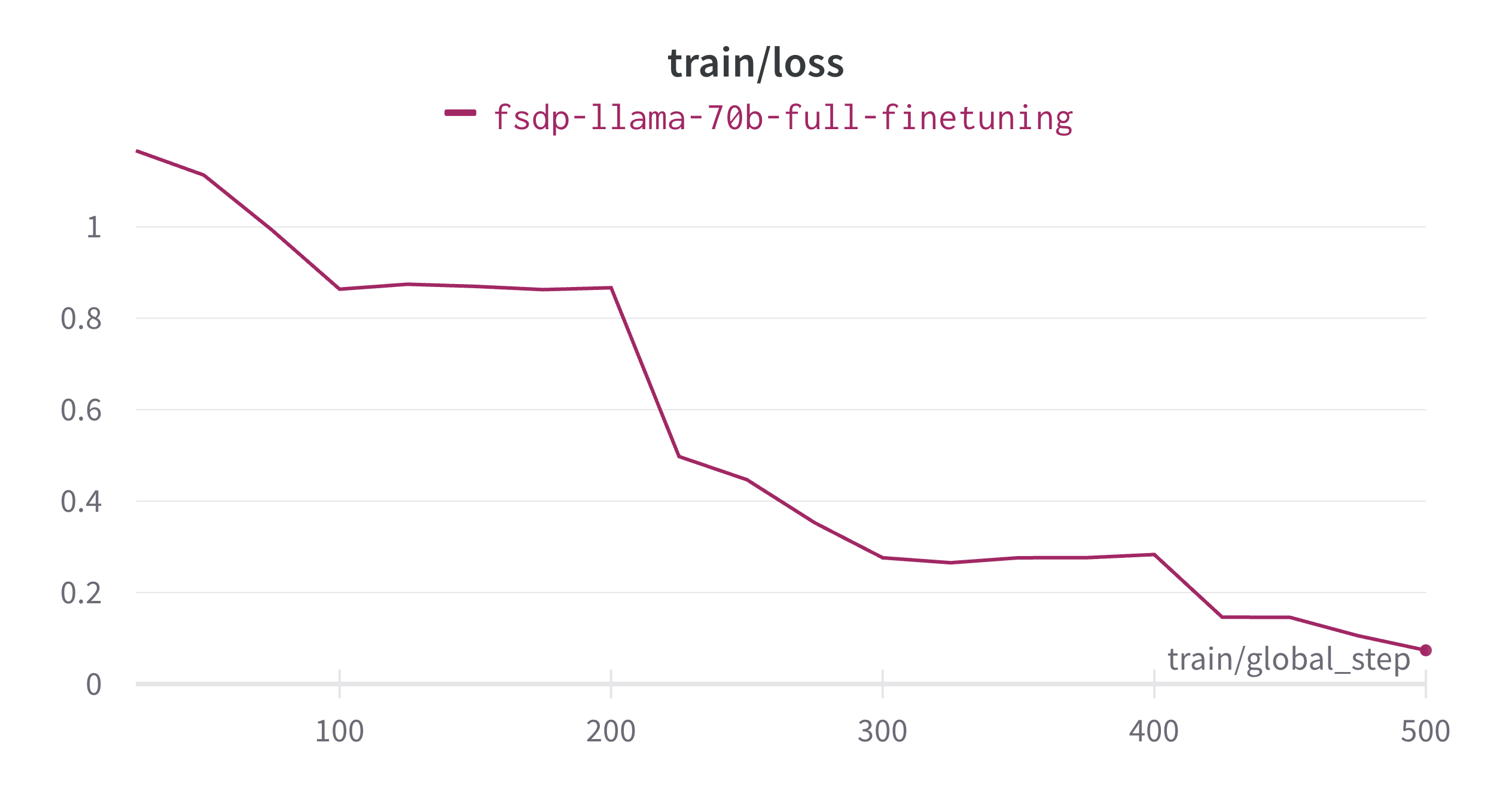
LLMs之Llama2 70B:使用 PyTorch FSDP 微调 Llama 2 70B实现全部过程讲解之详细攻略
LLMs之Llama2 70B:使用 PyTorch FSDP 微调 Llama 2 70B实现全部过程讲解之详细攻略 目录 使用 PyTorch FSDP 微调 Llama 2 70B 引言 FSDP 工作流 使用的硬件 微调 LLaMa 2 70B 面临的挑战 解决上述挑战,微调出一个 70B 的模型 准备工作 微调 应对挑战 1 应对挑战 2 应对挑战 3
CG-70B 双轴普及型倾角传感器
产品概述 一款双轴普及型数字型(RS485)倾角传感器,其产品分辨率为0.01°,采用塑料外壳,防护等级为IP66,可用来系统与准确地测量水平角度的变化状况。 功能特点 ★ 抗外界电磁干扰能力强、能承受大冲击震动,是工业级别的传感设备; ★ 具有显著的负载能力和非常好的冲击耐久性,而不需要附加其他器件; ★ 可以调节输出频率,内置零位调整,可以根据要求定制零位调整按钮,从而实现在一定的角
Meta开源Code Llama 70B,缩小与GPT-4之间的技术鸿沟
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领域的领跑者。点击订阅,与未来同行! 订阅:https://rengongzhineng.io/ 。 加入请求下载的名单: https://bit.ly/3Oil6bQ
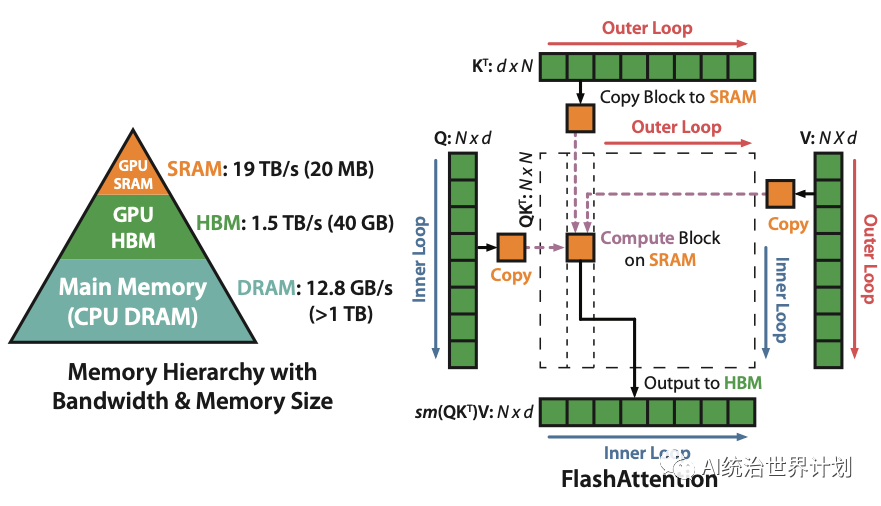
LLM推理部署(五):AirLLM使用4G显存即可在70B大模型上进行推理
众所周知,大模型的训练和推理需要大量的GPU资源,70B参数的大模型需要130G的GPU显存来存储,需要两个A100(显存为100G)。 在推理过程中,整个输入序列也需要加载到内存中进行复杂的“注意力”计算,这种注意力机制的内存需求与输入长度成二次方关系。 一、分层推理(Layer-wise Inference) 分层推理是计算机科学中分而治

Kaggle - LLM Science Exam(四):Platypus2-70B with Wikipedia RAG
文章目录 一、赛事概述1.1 OpenBookQA Dataset1.2 比赛背景1.3 评估方法和代码要求1.4 比赛数据集1.5 优秀notebook1.6 RAG 二、Platypus2-70B with Wikipedia RAG(Version8)2.1 离线安装依赖2.2 导入库并设置常量2.3设置辅助功能2.4 SentenceTransformer Class2.5 处理测试