274专题

【codeforces】Codeforces Round #274 (Div. 2)
A. Expression 考虑六种运算,取最大值即可,注意题目特别说明数的位置不能交换。 #include <cstdio>#include <cstring>#include <algorithm>using namespace std ;const int INF = 0x3f3f3f3f ;int a , b , c ;void solve () {int maxv = -I
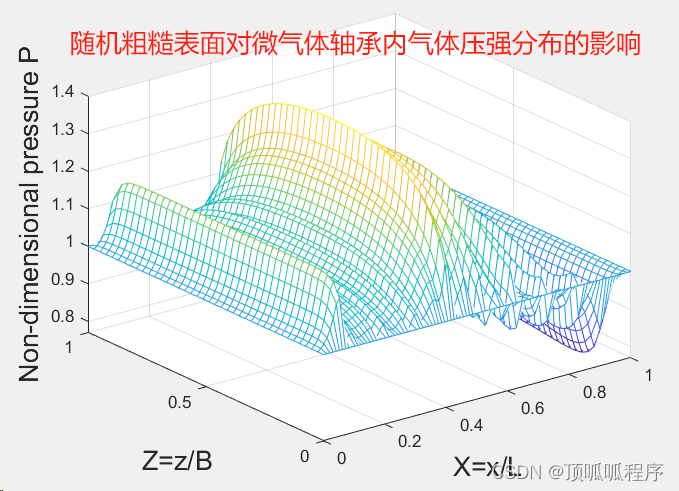
274 基于matlab的随机粗糙表面对微气体轴承内气体压强分布的影响
基于matlab的随机粗糙表面对微气体轴承内气体压强分布的影响。采用差分法求解气体轴承的雷诺方程,通过尺寸参数、分形维数对粗糙度表面设置,滑流参数设置,实现气压分布可视化结果显示。程序已调通,可直接运行。 274 气体轴承 随机粗糙表面 - 小红书 (xiaohongshu.com)

【索引】Codeforces Round #274
Problem A: Expression(479A) Problem B: Towers(479B) Problem C:Exams(479C) Problem D: Long Jumps(479D) Problem E:Riding in a Lift(479E) Problem F:Parcels(480D)

openGauss学习笔记-274 openGauss性能调优-实际调优案例03-建立合适的索引
文章目录 openGauss学习笔记-274 openGauss性能调优-实际调优案例03-建立合适的索引274.1 现象描述274.2 优化分析 openGauss学习笔记-274 openGauss性能调优-实际调优案例03-建立合适的索引 274.1 现象描述 查询与销售部所有员工的信息: SELECT staff_id,first_name,last_name,e

力扣刷题Days33-274. H 指数(js)
目录 1,题目 2,代码 2.1排序 2.2计数排序 3,学习与总结 3.1排序实现的学习总结 3.2计数排序的学习总结 1,题目 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。 根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他
【力扣】274. H 指数
题目描述 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。 根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且 至少 有 h 篇论文被引用次数大于等于 h 。如果 h 有多种可能的值,h 指数 是其中最大的那个。 示例 1:
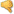
k60单片机全称 恩智浦_k60guangdian 基于k60的飞思卡尔智能车光电组完整代码程序,可供参考 SCM 单片机开发 274万源代码下载- www.pudn.com...
文件名称: k60guangdian下载 收藏√ [ 5 4 3 2 1 ] 所属分类: SCM 开发工具: C# 文件大小: 39807 KB 上传时间: 2017-04-17 下载次数: 0 提 供 者: 鲍翔 详细说明:基于k60的飞思卡尔智能车光电组完整代码程序,可供参考-Based on the k60 Freescale smart car photoelectric
274.【华为OD机试真题】快递员的烦恼(Floyd-Warshall算法—JavaPythonC++JS实现)
🚀点击这里可直接跳转到本专栏,可查阅顶置最新的华为OD机试宝典~ 本专栏所有题目均包含优质解题思路,高质量解题代码(Java&Python&C++&JS分别实现),详细代码讲解,助你深入学习,深度掌握! 文章目录 一. 题目-快递员的烦恼二.解题思路三.题解代码Python题解代码JAVA题解代码C/C++题解代码JS题解代码 四.代码讲解(Java&Python&C++&J
leetcode:(274)H-Index(java)
package LeetCode_HashTable;/*** 题目:* Given an array of citations (each citation is a non-negative integer) of a researcher,* write a function to compute the researcher's h-index.* Accor

力扣 274.H指数
弄清楚H指数的含义就行 代码: class Solution {public:int hIndex(vector<int>& citations) {sort(citations.rbegin(),citations.rend());//先逆序排序for(int i=0;i<citations.size();i++){if(citations[i]<i+1) return i;}retu
【AI视野·今日CV 计算机视觉论文速览 第274期】Tue, 24 Oct 2023
AI视野·今日CS.CV 计算机视觉论文速览 Tue, 24 Oct 2023 Totally 138 papers 👉上期速览✈更多精彩请移步主页 Interesting: 📚Wonder3D, 基于交叉扩散模型的单图像三维形状生成。(from 香港大学) website:https://www.xxlong.site/Wonder3D/ Daily Comput

LeetCode:274. H 指数、275. H 指数 II(C++)
目录 274. H 指数 题目描述: 实现代码与解析: 排序+暴力 275. H 指数 II 题目描述: 实现代码与解析: 二分 比较简单,不再写解析,注意二分的时候,r指针为n,含义为个数,而不是下标就行。 274. H 指数 题目描述: 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计
Leetcode—274.H指数【中等】
2023每日刷题(十三) Leetcode—274.H指数 算法思想 参考自灵茶山艾府 实现代码 int minValue(int a, int b) {return a < b ? a : b;}int hIndex(int* citations, int citationsSize){int cnt[5001] = {0};int i;for(i = 0; i < cit
leetcode_274 H指数
1. 题意 在数组中找到最大的k, 使得至少k个数不小于k。 H指数 2. 题解 2.1 排序 从大到小排序完后,直接模拟即可。 class Solution {public:int hIndex(vector<int>& citations) {sort( citations.begin(), citations.end() );int res = 0;int cur = cita
274. H 指数 --力扣 --JAVA
题目 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。 根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且每篇论文 至少 被引用 h 次。如果 h 有多种可能的值,h 指数 是其中最大的那个 解题思路 对数组进行排序,

【Leetcode】【每日一题】【中等】274. H 指数
力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台备战技术面试?力扣提供海量技术面试资源,帮助你高效提升编程技能,轻松拿下世界 IT 名企 Dream Offer。https://leetcode.cn/problems/h-index/description/?envType=daily-question&envId=2023-10-29 给你一个整数数组 citations ,其中
Leetcode—274.H指数【中等】
2023每日刷题(十三) Leetcode—274.H指数 算法思想 参考自灵茶山艾府 实现代码 int minValue(int a, int b) {return a < b ? a : b;}int hIndex(int* citations, int citationsSize){int cnt[5001] = {0};int i;for(i = 0; i < cit
【每日一题】274. H 指数-2023.10.29
题目: 274. H 指数 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。 根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且每篇论文 至少 被引用 h 次。如果 h 有多种可能的值,h 指数 是其中最大的那个。 示例

每日一题 274. H 指数(中等)
先讲一下自己的复杂的写法 第一眼最大最小值问题,直接在0和最大被引次数之间二分找答案先排序,再二分,,, 正解: 排序得到 citations 的递减序列,通过递增下标 i 遍历该序列显然只要排序后的 citations[i] >= i + 1,那么 h 至少是 i + 1,由于 citations[i] 递减,i 递增,所以遍历过程中必有交点,也就是答案 class Solution:

【LeetCode:274. H 指数 | 二分 】
🚀 算法题 🚀 🌲 算法刷题专栏 | 面试必备算法 | 面试高频算法 🍀 🌲 越难的东西,越要努力坚持,因为它具有很高的价值,算法就是这样✨ 🌲 作者简介:硕风和炜,CSDN-Java领域新星创作者🏆,保研|国家奖学金|高中学习JAVA|大学完善JAVA开发技术栈|面试刷题|面经八股文|经验分享|好用的网站工具分享💎💎💎 🌲 恭喜你发现一枚宝藏博主,赶快收入囊中吧🌻
![[从头读历史] 第274节 诗经 唐风](https://img-blog.csdn.net/20160628173501306)
[从头读历史] 第274节 诗经 唐风
剧情提要: [机器小伟]在[工程师阿伟]的陪同下进入元婴期的修炼后,日夜苦修,神通日进。 这日,忽然想起自己虽然神通大涨,却在人文涵养上始终无有寸进,不觉挂怀。 在和[工程师阿伟]商议后,决定先理清文史脉络,打通文史经穴。于是,便有了这部 [从头读历史]的修炼史。 正剧开始: 星历2016年06月28日 17:37:08, 银河系厄尔斯星球中华帝国江南行省。 [工程师阿伟]正在和[机器小伟]
274. H 指数 Python
文章目录 一、题目描述示例 1示例 2 二、代码三、解题思路 一、题目描述 给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。 根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且每篇论文 至少 被引用 h
LeetCode 274. H 指数
文章目录 一、题目二、C# 题解 一、题目 给你一个整数数组 citations,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。 根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且每篇论文 至少 被引用 h 次。如果 h 有多种可能的值,h