202112专题

202112 CSP认证 | 登机牌条码
登机牌条码 这个题的难度相比于神经脉冲网络感觉是往两个方向,该题没有太多的注重时间和空间的优化,重难点在于实现矩阵除法,也就是算法逻辑。 借鉴了这个链接实现:登机牌条码 详细图解 链接详细讲述了如何实现矩阵除法以及矩阵乘法,感觉在今后的算法题中都是很好的借鉴!! 本题代码中为了方便我用了deque双端队列,实现在两端的存储和删除操作(主要针对于乘法操作的地位补0更加方便);感觉在理解了矩阵

【CSP试题回顾】202112-2-序列查询新解
CSP-202112-2-序列查询新解 关键点:时间复杂度 本题关键在于它避免暴力枚举法的时间复杂度。暴力枚举法可能会对每一对可能的 f(x) 和 g(x) 组合进行比较,其时间复杂度为 O ( n 2 ) O(n^2) O(n2),这对于大数据集来说是不可行的。 【解决思路】:通过逐步遍历 f(x) 和 g(x) 的值(每次只移动到下一个 f(x) 或 g(x) 值),将时间复杂
DataWhale-(scikit-learn教程)-Task08(可视化总结)-202112
西瓜书代码实战 一、决策树可视化 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.model_sele
DataWhale-(scikit-learn教程)-Task08(可视化总结)-202112
西瓜书代码实战 一、决策树可视化 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltfrom sklearn.datasets import load_irisfrom sklearn.tree import DecisionTreeClassifierfrom sklearn.model_sele
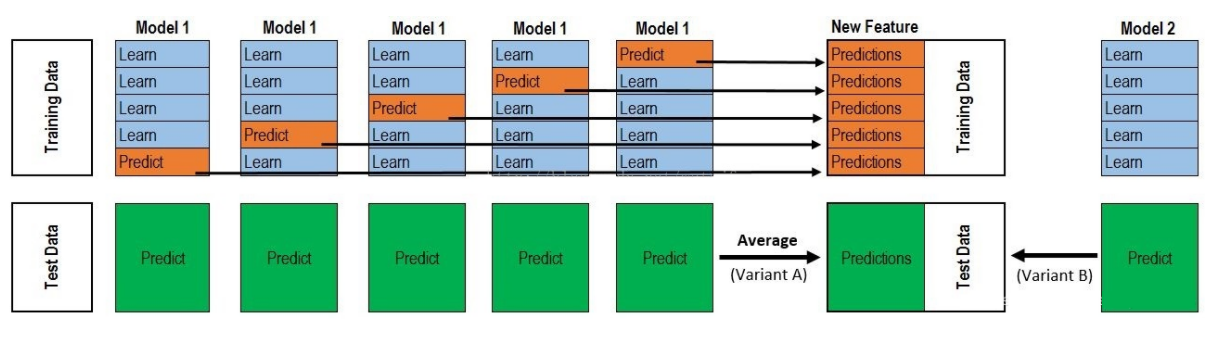
DataWhale-(scikit-learn教程)-Task07(集成学习)-202112
一、基本原理 集成学习(ensemble learning) 通过构建并结合多个学习器来完成学习任务,以提高比单个学习器更好的泛化和稳定性能。要获得好的集成效果,个体学习器应该“好而不同”。按照个体学习器的生成方式,集成学习可分为两类:序列集成方法,即个体学习器存在强依赖关系,必须串行生成,如Boosting;并行集成方法,即个体学习器不存在强依赖关系,可以并行生成,如Bagging,随机森林。
DataWhale-(scikit-learn教程)-Task07(集成学习)-202112
一、基本原理 集成学习(ensemble learning) 通过构建并结合多个学习器来完成学习任务,以提高比单个学习器更好的泛化和稳定性能。要获得好的集成效果,个体学习器应该“好而不同”。按照个体学习器的生成方式,集成学习可分为两类:序列集成方法,即个体学习器存在强依赖关系,必须串行生成,如Boosting;并行集成方法,即个体学习器不存在强依赖关系,可以并行生成,如Bagging,随机森林。

DataWhale-(scikit-learn教程)-Task06(主成分分析)-202112
一、 PCA主成分分析算法介绍 二、算法实现 import sysfrom pathlib import Pathcurr_path = str(Path().absolute()) # 当前文件所在绝对路径parent_path = str(Path().absolute().parent) # 父路径sys.path.append(parent_path) # 添加路径到系统
DataWhale-(scikit-learn教程)-Task06(主成分分析)-202112
一、 PCA主成分分析算法介绍 二、算法实现 import sysfrom pathlib import Pathcurr_path = str(Path().absolute()) # 当前文件所在绝对路径parent_path = str(Path().absolute().parent) # 父路径sys.path.append(parent_path) # 添加路径到系统

DataWhale-(scikit-learn教程)-Task05(K均值聚类)-202112
sklearn机器学习实战 周志华《机器学习》 一、K均值聚类基本原理及算法 二、K均值聚类算法实现 import matplotlib.pyplot as pltfrom sklearn.datasets import make_blobsfrom sklearn.cluster import KMeans# make_blobs:生成聚类的数据集# n_samples:
DataWhale-(scikit-learn教程)-Task05(K均值聚类)-202112
sklearn机器学习实战 周志华《机器学习》 一、K均值聚类基本原理及算法 二、K均值聚类算法实现 import matplotlib.pyplot as pltfrom sklearn.datasets import make_blobsfrom sklearn.cluster import KMeans# make_blobs:生成聚类的数据集# n_samples:

DataWhale-Linux组队学习-(Task08-10)-202112
Datawhale Linux组队学习 任务8 步骤1: 步骤2: 1.统计歌词中 包含【超人】的歌词 2. 统计歌词中 包含【外婆】但不包含【期待】的歌词 3. 统计歌词中 以【我】开头的歌词 4.统计歌词中 以【我】结尾的歌词 步骤3: 1.将歌词中 第2行 至 第40行 删除 2. 将歌词中 所有【我】替换成【你】 任务9 步骤1: 步骤2:
DataWhale-Linux组队学习-(Task08-10)-202112
Datawhale Linux组队学习 任务8 步骤1: 步骤2: 1.统计歌词中 包含【超人】的歌词 2. 统计歌词中 包含【外婆】但不包含【期待】的歌词 3. 统计歌词中 以【我】开头的歌词 4.统计歌词中 以【我】结尾的歌词 步骤3: 1.将歌词中 第2行 至 第40行 删除 2. 将歌词中 所有【我】替换成【你】 任务9 步骤1: 步骤2:

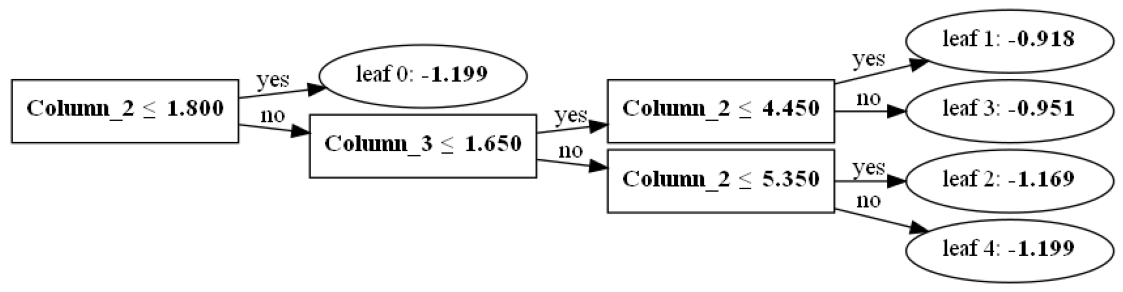
DataWhale-(scikit-learn教程)-Task04(决策树)-202112
一、决策树基本算法 二、基于sklearn的算法实现 https://github.com/datawhalechina/machine-learning-toy-code/tree/main/ml-with-sklearn import seaborn as snsfrom pandas import plottingimport pandas as pdimport numpy
DataWhale-(scikit-learn教程)-Task04(决策树)-202112
一、决策树基本算法 二、基于sklearn的算法实现 https://github.com/datawhalechina/machine-learning-toy-code/tree/main/ml-with-sklearn import seaborn as snsfrom pandas import plottingimport pandas as pdimport numpy