频数专题

力扣1838.最高频的元素的频数
力扣1838.最高频的元素的频数 首先排序 然后右指针遍历补成的数 每次加**差值(num[i] - num[i-1]) * 位数(i - j) class Solution {public:int maxFrequency(vector<int>& nums, int k) {int res=1,n = nums.size();sort(nums.begin(),nums.end());
R语言计算频数和频率
首先,筛选出需要的列: data <- data2[,which(colnames(data2) %in% c("产品分类", "期数", "逾期月数"))] 产品分类期数逾期月数委托贷款241委托贷款361担保贷款242委托贷款242信用贷款364担保贷款243信用贷款241委托贷款363担保贷款242 现在希望得到每种产品种类在不同期数时,逾期月数的占比,使用table函数: #fre
【SQL】一条查询中统计同一字段不同记录值数量(频数统计)的写法
更新一: 有一些参考者反馈文中“COUNT写法”的可用性问题,这里就在文首提前聊一个概念性问题。众所周知,关系型数据库思想和SQL规范都源自IBM。然后基于(并非完全遵守)关系型数据库的理论思想和SQL标准,很多商业版或社区开源版的关系型数据库软件产品出现了。其中商业版比较知名的有IBM的DB2、Oracle的Oracle以及Microsoft的SQL Server;开源免费版比较流行的有MyS
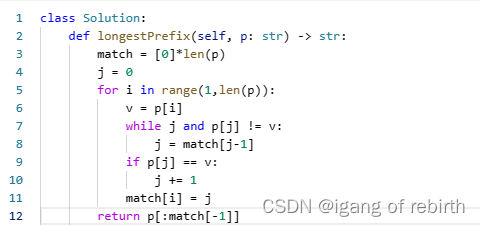
955. 删列造序 II;1838. 最高频元素的频数;1392. 最长快乐前缀
955. 删列造序 II 核心思想:我们可以按照一行一行排列strs,删除索引序列就代表删除某一列,那么我们如何判断一列是否应该删除呢,我们可以从反方向思考,应该保留那些列呢?从第一列开始,如果它不满足字典序肯定就不保存,如果它加上后面的列依旧满足的话就保存,反之判断下一列。即后面的某些列加起来如果满足字典序,如果前面有一列满足字典序加上这列肯定也是满足的。 1838. 最高频元素的频数

频数表和列联表,以及进一步处理分析 -- R
目的 数据框包含了一些分类变量,问? 1.如何统计分类变量的分布次数 -- 频数表2.如何统计多分类变量的分布次数 -- 频联表3.单个分类变量的分类结果是否满足理论分类结果 -- 拟合优度问题4.多个分类变量的分类结果是否相关干扰 -- 分类变量(多因素)独立性检验 数据 library(vcd)data(Arthritis)head(Arthritis)# ID Tre
Origin绘制频数分布直方图+曲线拟合分布
问题描述 有组数据大概分布如下,现在想在Origin中绘制出以下效果 流程 如果我们想要人为每个柱子的边界,以方便展示,需要新建一列,输入数据分布的大概区间。 需要注意的是,C(Y)列中删除数据时若留下的“-”符合存在,则后续使用会报错,而且也不能手动删除“-”符合,只可以删除该列重新建立,然后粘贴区间。 之后选中数据列,统计-描述统计-频数分布 对话框中选择指定区间范围依据,然后下
![[R分析] 描述统计:频数和频率分布直方图](https://img-blog.csdn.net/20180208121228445?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc2luYXRfMjU4NzM0MjE=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[R分析] 描述统计:频数和频率分布直方图
n<-round(runif(1000,0,100)) #生成0到100的1000个随机数hist(n) #频数分布直方图,纵坐标名字为frequencyhist(n,freq = F) #频率分布直方图,纵坐标名字为density n<-rnorm(1000) #服从正态分布的1000个数hist(n)hist(n,freq = F)
1838.最高频元素的频数
我的双指针法: class Solution:def maxFrequency(self, nums:list, k: int) -> int:nums.sort()print(nums)length = len(nums)if length == 1:return 1maxn = 0pleft,pright = 0, 0 # 左右指针curn = 0while pright<length:
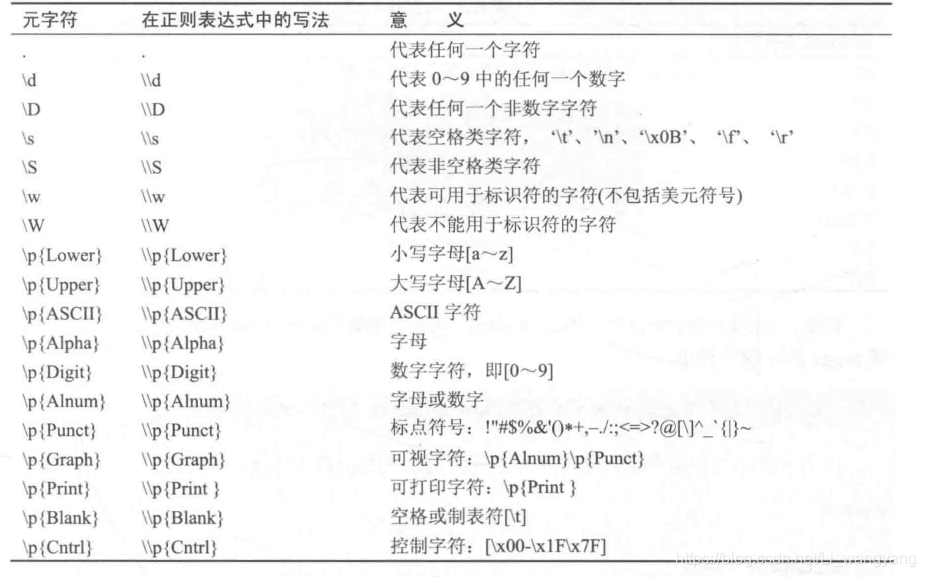
Java练习-使用数组统计一段英语文章中的单词频数
Java练习-使用数组统计一段英语文章中的单词频数 一、分析1.1 基本要求1.2 进阶要求 二、代码实现(分步骤)2.1 赋值,变小写,正则表达式及分割2.2 频数统计排序输出:冒泡 2.3 进阶要求实现2.3.1 介词的处理2.3.2 单复数处理2.3.3 时态处理 三、完整代码输出结果 要求:基于java 找一段较长的英文文章(500个单词左右),赋值给一字符串,设计以

Leecode<每日一题>最高频元素的频数
Leecode<每日一题>最高频元素的频数 题目链接 思路:排序+滑动窗口 int maxFrequency(vector<int>& nums, int k) {if (nums.size() ==

6.R语言【频数、频率统计函数】一维、二维、三维
b站课程视频链接: https://www.bilibili.com/video/BV19x411X7C6?p=1 腾讯课堂(最新,但是要花钱,我花99😢😢元买了,感觉讲的没问题,就是知识点结构有点乱,有点废话): https://ke.qq.com/course/3707827#term_id=103855009 本笔记前面的笔记参照b站视频,【后面的画图】参考了付费视频 笔记顺序做了

R 统计频数大于某个值的值
例子:实现统计某一列频数大于2的名称 a <- c(10,20,30,40,10,20,30,40)b <- c('book', 'pen', 'textbook', 'pencil_case','book', 'pen', 'textbook', 'textbook')df <- data.frame(a,b)# printtable(df$b)[table(df$b)>2]names