项集专题

理解机器学习实战 --- FP-Growth算法高效发现频繁项集
FP-growth算法介绍: 一种非常好的发现频繁项集的算法 基于Apriori算法构建,但是数据结构不同,使用叫做FP树的数据结构来存储集合。 FP-grouw算法原理: 基于数据集构造FP树 支持度:某一项类别出现的次数,可以理解为出现的频率。 非频繁项:某一项出现的次数小于一定次数,我们称之为非频繁项集。 步骤一: 1.遍历所有的数据集合,计算
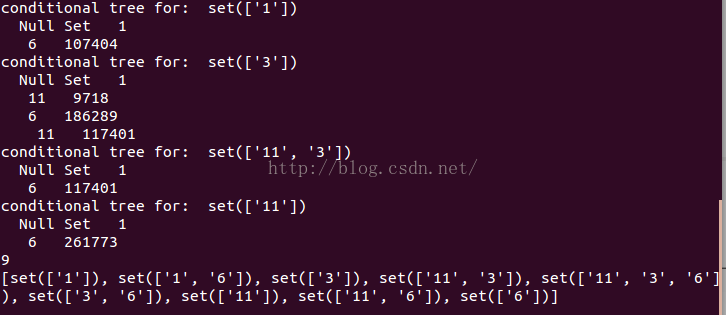
《机器学习实战》笔记之十二——使用FP-Growth算法来高效发现频繁项集
第十二章 使用FP-Growth算法来高效发现频繁项集 FP-growth算法,基于Apriori构建,但在完成相同任务时采用了不同的技术,其只需要对数据库进行两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此其比Apriori算法快。FP算法需要将数据集存储在一个特定的称作FP树的结构之后发现频繁项集或者频繁项对。 12.1 FP树:用于编
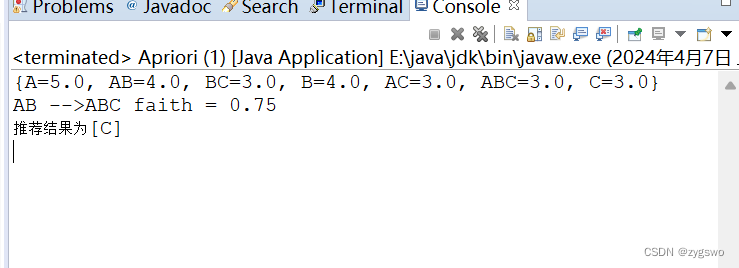
程序猿成长之路之数据挖掘篇——频繁项集挖掘介绍
频繁项集挖掘可以说是数据挖掘中的重点,下面我们来分析以下频繁项集挖掘的过程和目标 如果对数据挖掘没有概念的小伙伴可以查看上次的文章 https://blog.csdn.net/qq_31236027/article/details/137046475 什么是频繁项集? 在回答这个问题之前,我们可以看一个例子: 小明、小刚、小红三人去同一家商店购物,小明、小刚两人购买了鸡蛋,牛奶和面包,

频繁项集挖掘以及关联规则的基本概念
一.几个基本概念 1.支持度计数:即包含含特定项集的事务个数。 2.支持度: 计算方式:对于关联规则X–>Y,s=support(X∪Y)/N,其中,N为事务的个数,support(X∪Y)为项集{X,Y}的支持度计数。 3.置信度:对于关联规则X–>Y,c=support(X∪Y)/support(X)。 4.为什么要使用支持度和置信度? 支持度:是一种重要度量,因为支持度很低的规则