词性专题

NLP-文本处理:依存句法分析(主谓、动宾、动补...)【基于“分词后得到的词语列表A”+“A进行词性标注后得到的词性列表B”来进行依存句法分析】【使用成熟的第三方工具包】
句法分析(syntactic parsing)是自然语言处理中的关键技术之一,它是对输入的文本句子进行分析以得到句子的句法结构的处理过程。对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的重要一环,另一方面也为其它自然语言处理任务提供支持。例如句法驱动的统计机器翻译需要对源语言或目标语言(或者同时两种语言)进行句法分析。 第三方工具包: 哈工大LTP首页 哈工大LTP4 文档

NLP-信息抽取:关系抽取【即:三元组抽取,主要用于抽取实体间的关系】【基于命名实体识别、分词、词性标注、依存句法分析、语义角色标注】【自定义模板/规则、监督学习(分类器)、半监督学习、无监督学习】
信息抽取主要包括三个子任务: 实体抽取与链指:也就是命名实体识别关系抽取:通常我们说的三元组(triple)抽取,主要用于抽取实体间的关系事件抽取:相当于一种多元关系的抽取 一、关系抽取概述 关系抽取通常在实体抽取与实体链指之后。在识别出句子中的关键实体后,还需要抽取两个实体或多个实体之间的语义关系。语义关系通常用于连接两个实体,并与实体一起表达文本的主要含义。常见的关系抽取结果

NLP-文本处理:词性标注【使用成熟的第三方工具包:中文(哈工大LTP)、英文()】【对分词后得到的“词语列表”进行词性标注,词性标注的结果用于依存句法分析、语义角色标注】
词性: 语言中对词的一种分类方法,以语法特征为主要依据、兼顾词汇意义对词进行划分的结果, 常见的词性有14种, 如: 名词, 动词, 形容词等. 顾名思义, 词性标注(Part-Of-Speech tagging, 简称POS)就是标注出一段文本中每个词汇的词性. 举个栗子: 我爱自然语言处理==>我/rr, 爱/v, 自然语言/n, 处理/vnrr: 人称代词v: 动词n: 名词vn

HMM在自然语言处理中的应用一:词性标注2
http://www.52nlp.cn/hmm-application-in-natural-language-processing-one-part-of-speech-tagging-2 上一节我们对自然语言处理中词性标注的基本问题进行了描述,从本节开始我们将详细介绍HMM与词性标注的关系以及如何利用HMM进行词性标注。首先回顾一下隐马尔科夫模型(HMM)的定义和三大基本问题,并由
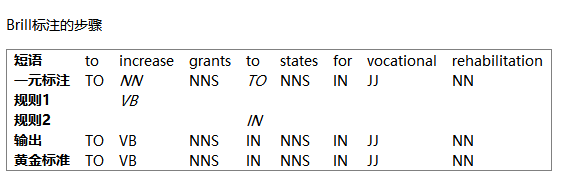
NLTK(5)词性标注
文章目录 如何确定一个词的词性1形态学线索2句法线索3语义线索 NLTK标注器标注语料库查看标注未简化标记集词性搜索 @字典定义字典反转字典字典方法 自动标注默认标注器(不好) 标注效果评估正则表达式标注器查询标注器回退 N-gram标注一元标注器N-gram标注器缺点 组合标注器标注生词一个基于上下文标注生词的方法: @准确性的极限Brill标注器思想Brill标注的步骤代码
python3进行中文分词和词性标注
配置python环境(win10) 下载python3,网址:https://www.python.org/双击安装,我安装在了D:\python 中。添加环境变量。 在我的电脑处右键 -> 高级系统设置 -> 环境变量 -> 系统变量 -> 双击path -> 新建 ->看下图-> 确定 因为我的电脑已经安装了python2.7(硬要安装python3是因为后面中文分词简便一点),所以这里

NLP-词性标注+动态规划实现
目录 一、计算 1.实现目标 2.训练数据 3.计算原理 二、实现 1.训练数据 2.构建参数 3.统计数据 4.维特比算法 ①定义数组 ②计算第一列分数 ③循环计算后面的分数(举例) ④找最优解 一、计算 1.实现目标 给出一句话,输出每个词的词性 2.训练数据 类似于下面的数据,左边是句子中的每个词,右边是对应的词性,其中句号代表一句话结束。

使用Spacy做中文词频和词性分析
使用Spacy python库做中文词性和词频分析,读取word并给出其中每个词的词频和词性,写入excel表。 1、为什么选择Spacy库 相比与NLTK这个库更快和更准 2、模型比较 zh_core_web_trf模型,模型大,准确性高。 需要确保你的Spacy版本是最新的,因为zh_core_web_trf是一个基于transformer的模型,因为它包含了整个transformer模型。

Python 文本挖掘:jieba中文分词和词性标注
转自:http://rzcoding.blog.163.com/blog/static/222281017201310155331241/ jieba 分词:做最好的Python 中文分词组件。 这是结巴分词的目标,我相信它也做到了。操作简单,速度快,精度不错。而且是Python 的库,这样就不用调用中科院分词ICTCLAS了。 妈妈再也不用担心我不会分词啦。 jieba 的主页有详
jieba(结巴)分词种词性简介
jieba为自然语言语言中常用工具包,jieba具有对分词的词性进行标注的功能,词性类别如下: Ag 形语素 形容词性语素。形容词代码为 a,语素代码g前面置以A。 a 形容词 取英语形容词 adjective的第1个字母。 ad 副形词 直接作状语的形容词。形容词代码 a和副词代码d并在一起。 an 名形词 具有名词功能的形容词。形容词代码 a和名词代码n并在一

【Larry】英语学习笔记语法篇——换一种方式理解词性
目录 一、换一种方式理解词性 1、名词、形容词、副词,这就是一切 2、词性之间的修饰关系 3、介词其实很简单 形容词属性的介词短语 副词属性的介词短语 ①修饰动词 ②修饰形容词 ③修饰其他副词 一、换一种方式理解词性 1、名词、形容词、副词,这就是一切 图1.1 2、词性之间的修饰关系 图1.2 常见词性和种类 图1.3 词性分类

单词的词性由什么决定?出现这样的搭配是什么原因? ved + prep ving + n英语大概可以分出多少种时态?介绍一下语态The teacher respected by stu
目录 单词的词性由什么决定? 出现这样的搭配是什么原因? ved + prep ving + n 英语大概可以分出多少种时态? 介绍一下语态 The teacher respected by students explains the lesson. 介绍一下respected在这个句子中的作用 介绍一下插入语 介绍一下ferry这个名字的含义 介绍一下effect这个单词 介绍
基于百度开源项目LAC实现文本分词、词性标注和命名实体识别
文本分词、词性标注和命名实体识别都是自然语言处理领域里面很基础的任务,他们的精度决定了下游任务的精度,今天在查资料的时候无意间发现了一个很好玩的开源项目,具体查了一下才知道这是百度开源的一个主要用于词性标注和命名实体识别的项目,决定拿来尝试一下。 首先是项目环境的配置安装,当前已经支持一键式安装了,具体命令如下所示: python -m pip install LAC 简单进行一下安装验证,成功截
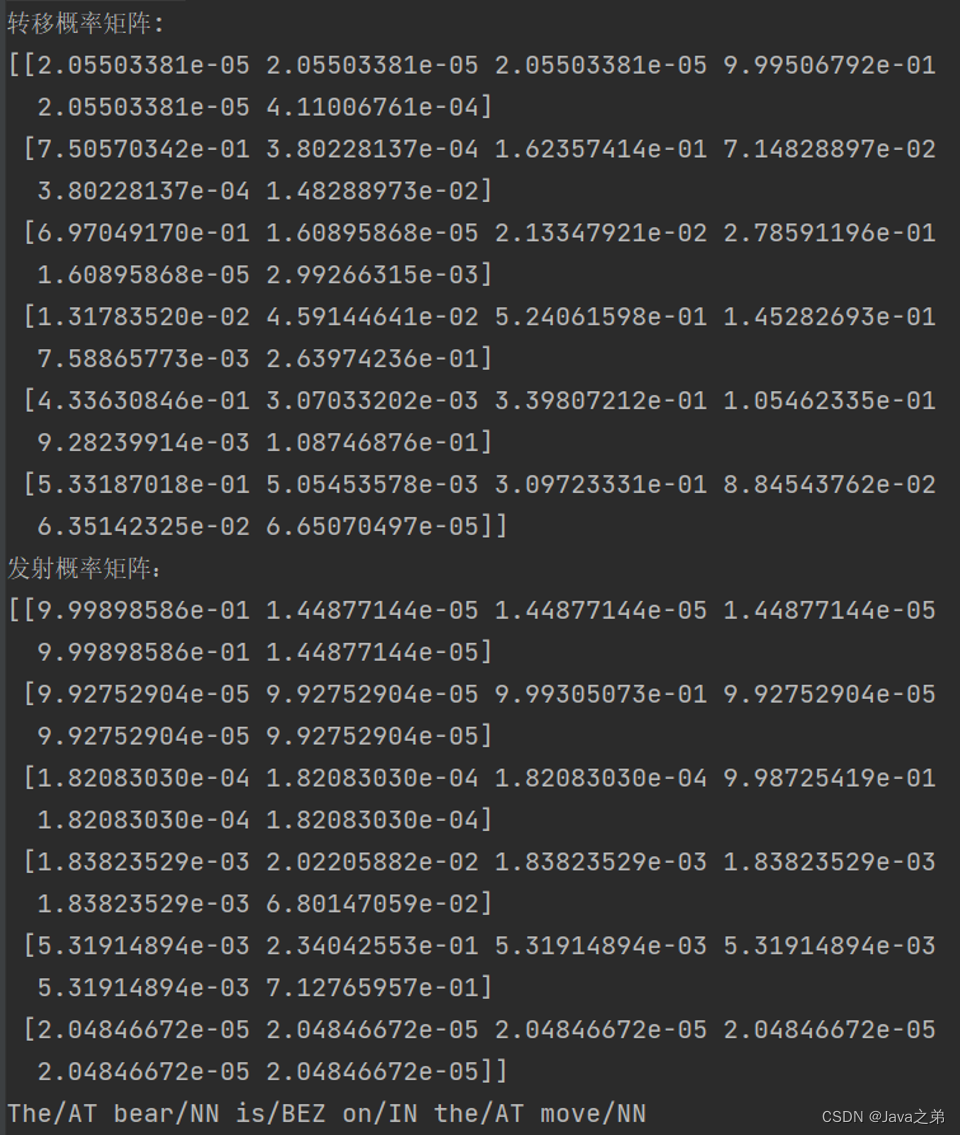
自然语言处理--基于HMM+维特比算法的词性标注
自然语言处理作业2--基于HMM+维特比算法的词性标注 一、理论描述 词性标注是一种自然语言处理技术,用于识别文本中每个词的词性,例如名词、动词、形容词等; 词性标注也被称为语法标注或词类消疑,是语料库语言学中将语料库内单词的词性按其含义和上下文内容进行标记的文本数据处理技术; 词性标注可以由人工或特定算法完成,使用机器学习方法实现词性标注是自然语言处理的研究内容。常见的词性标注算法包括隐
命名实体识别以及词性自动标注
一、命名实体识别 大数据风靡的今天,不从里面挖出点有用的信息都不好意思见人,人工智能号称跨过奇点,统霸世界,从一句话里都识别不出一个命名实体?不会的,让我们大话自然语言处理的囊中取物,看看怎么样能让计算机像人一样看出一句话里哪个像人、哪个像物 请尊重原创,转载请注明来源网站www.shareditor.com以及原始链接地址 话说天下大事,分久必合,合久必分。 之
浅谈聊天机器人 ChatBot 涉及到的技术点 以及词性标注和关键字提取
一、浅谈聊天机器人 ChatBot 涉及到的技术点 聊天机器人到底该怎么做呢?我日思夜想,于是乎我做了一个梦,梦里面我完成了我的聊天机器人,它叫chatbot,经过我的一番盘问,它向我叙述了它的诞生记 请尊重原创,转载请注明来源网站 www.shareditor.com 以及原始链接地址 聊天机器人是可行的 我:chatbot,你好! chatbot:你也好! 我:聊天
jieba分词的基本用法和词性标注
jieba分词的基本用法和词性标注 一、jieba 分词基本概述二、添加自定义词典3、关键词提取四、词性标注 *五、并行分词六、Tokenize:返回词语在原文的起始位置 jieba分词的基本用法和词性标注 一、jieba 分词基本概述 它号称“做最好的Python中文分词组件”的jieba分词是python语言的一个中文分词包。 它有如下三种模式: 精确模式,试图将句子最
java调用Hanlp分词器获取词性;自定义词性字典
若解读用户输入的一段话,找出输入内容的构成(名词、动词、形容词、地名、人名等)以便进一步的处理。 一、配置pom,导包: <dependency><groupId>com.hankcs</groupId><artifactId>hanlp</artifactId><version>portable-1.6.8</version></dependency> 二、java代码实现分词:
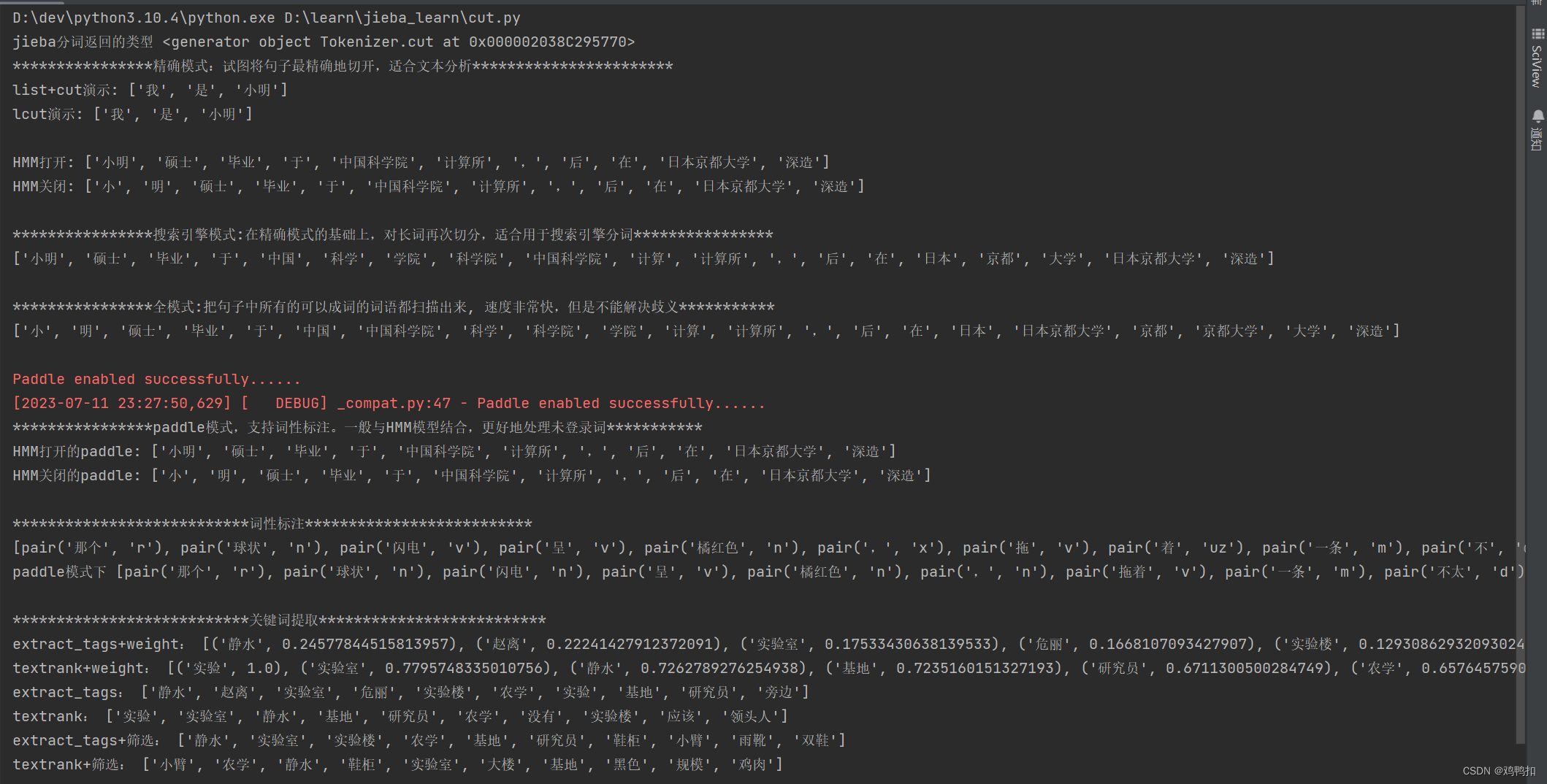
中文分词工具jieba:代码之分词、词性标注、关键词提取与两个问题一个注意。问题一:安装jieba库成功但导入失败,问题二:paddle模式使用不了。注意:关闭paddle模式的控制台信息提示
一、官方入口 jieba官方项目入口:fxsjy/jieba: 结巴中文分词 (github.com) 二、两个问题: 问题一:已经通过命令行或者pycharm安装成功jieba,但是运行代码报错说“ModuleNotFoundError:No module named 'jieba' ” 解决方案:再次打开命令行输入pip install jieba,提示已经成功安装,记下路径后找
jieba-fenci 结巴分词之词性标注实现思路 speechTagging segment
拓展阅读 DFA 算法详解 为了便于大家学习,项目开源地址如下,欢迎 fork+star 鼓励一下老马~ 敏感词 sensitive-word 分词 segment 词性标注 词性标注的在分词之后进行标注,整体思路也不难: (1)如果一个词只有一种词性,那么直接固定即可。 (2)如果一个词有多种词性,那么需要推断出最大概率的一种。 这个其实有些类似分词的时候做的事情,
R语言自然语言处理:词性标注与命名实体识别
欢迎关注天善智能,我们是专注于商业智能BI,人工智能AI,大数据分析与挖掘领域的垂直社区,学习,问答、求职一站式搞定! 对商业智能BI、大数据分析挖掘、机器学习,python,R等数据领域感兴趣的同学加微信:tstoutiao,邀请你进入数据爱好者交流群,数据爱好者们都在这儿。 作者:黄天元,复旦大学博士在读,目前研究涉及文本挖掘、社交网络分析和机器学习等。希望与大家分享学

实习点滴(3)--以“词性标注”为例理解CRF算法
看了CRF相关的东西好几天了,现在也过来总结总结。我本人喜欢以讲故事的方式阐述一些东西,纯理论总是很抽象,而且很容易让人失去耐心。那就以“词性标注”为切入点,去理解一下CRF(Conditional Random Field)条件随机场的算法原理(难免有不对或者不全的地方,持续更新)。 相关定义: CRF(Conditional Random Fie

HMM与LTP词性标注之命名实体识别与HMM
文章目录 知识图谱介绍NLP应用场景知识图谱(Neo4j演示)命名实体识别模型架构讲解HMM与CRFHMM五大要素(两大状态与三大概率)HMM案例分享HMM实体识别应用场景代码实现 知识图谱介绍 NLP应用场景 图谱的本质,就是把自然语言处理的文本段落的无序的结构转换成有数据结构的信息,图谱本身是有结构的数据。 知识图谱(Neo4j演示) 这套方法,我们需要有语料库,通

词性标注学习第二周19.08.04
词性标注学习第二周19.08.04 练习用文本文章链接文本 第二周工作心得以下总结了易混淆词词性 练习用文本 注释:黄色高亮部分为有争议部分 // 答案不确定参考词性标注规范:PFR语料库 对人民日报标注的规则 文章链接 文章地址: https://blog.csdn.net/diyiday/article/details/87940222 标记参考文档下载: 链接:ht