计数法专题

java fastxml json 科学计数法转换处理
背景: 由于 canal 切换为 tx dbbridge后,发现dbbridge对于canal的兼容性存在较大问题,从而引发 该文档的实践。 就目前发现 dbbrige 的字段 大小写 和 数据类型格式 从binlog 写入kafka 同canal 都会存在差异。 canal之前导出都是小写,但是dbbrige接出来后部分字段名大写,部分字段名小写。 如果下游代码 对于 大小写敏感的消费者

microsoft微软excel或WPS表格打开vivado逻辑分析仪ILA保存的csv文件,自动转换科学计数法损失精度的bug
问题 vivado的逻辑分析仪ILA,可以方便的把数据导出成CSV(Comma-Separated Values)文件,实际是逗号作为分隔符的数据文件。 导出数据文件用文本编辑器打开,第74行有如下数据: 但是使用excel打开这个csv文件,则这个数据自动显示为科学计数法,但是值的最后一位已经从8变成0: 误差 这个值代表的双精度浮点数,误差-0.00000000000005

字符串排序:键索引计数法
字符串排序:键索引计数法 描述适用性步骤1、频率统计2、构建索引3、数据分类4、回写数组 代码实现总结参考 描述 关于字符串的排序有很多种方式,像《算法》一书中列举的低位优先、高位优先等,其中最先提到的是键索引计数法,它也是其他排序方式的基础,我们先来了解下。 适用性 关于键索引计数法进行字符串排序,并不是全部都适用,因为它的排序算法核心就是通过统计元素出现频次、构建排序因子

【Numpy】np.savetxt保存时数据不使用科学计数法形式
使用np.savetxt可以dump数据 np.set_printoptions(suppress=True)np.set_printoptions(precision=4) #设精度np.savetxt('data_name‘, data.view(-1, 1), fmt='%.04f') #保留4位小数 numpy在print时会有...省略掉中间部分,如果希望显示处完整数组:
数学建模学习(125):使用Python实现Borda计数法进行多标准决策分析
文章目录 1. 背景2. 理论与原理3. 案例背景与数据构建4. Python代码实现5. 代码解析与结果解读参考文献 1. 背景 Borda计数法由法国数学家Jean-Charles de Borda于1781年提出,是一种用于多选项投票系统的排名方法。它被广泛应用于多标准决策分析(MCDA)中,以解决在复杂的决策场景中如何选择最佳方案的问题。 传统的多数决投票方式在候选项
c# 导出excel 数字太长而显示为科学计数法的解决方法
使用c#导出excel的时候,当数字太长时,如身份证号,导出后的excel就会显示为科学计数法。如“511122154712121000”会显示成“5.111E+1”。解决方法是在文本前添加一个单引号。如“'511122154712121000”。导出后显示就正常了。
如何处理Golang中int64类型变为科学计数法?
背景 这周时候在处理订单消息传递的时候,发现定义的orderID大多数时候是正常的(例如:1152921570135310348)偶现科学计数法(例如:1.1529215701353103e+18)。 传参的结构是这样的:map[string]interface{} 赋值:data[“id”] = 1152921570135310348 后面就开始调接口,记录日志等一系列操作。查了一会儿发现
TOP150-LC274-h指数-二分、计数法
/*H指数给你一个整数数组 citations ,其中 citations[i] 表示研究者的第 i 篇论文被引用的次数。计算并返回该研究者的 h 指数。根据维基百科上 h 指数的定义:h 代表“高引用次数” ,一名科研人员的 h 指数 是指他(她)至少发表了 h 篇论文,并且 至少 有 h 篇论文被引用次数大于等于 h 。如果 h 有多种可能的值,h 指数 是其中最大的那个。*/ publi
如何不使用 ndarray 默认的科学计数法格式
在程序的开头加上两句话: import numpy as npnp.set_printoptions(suppress=True) 补充: 1、在Python 中设置不使用科学计数法 >>> a = -7.1855143557448603e-17>>> '{:f}'.format(a)'-0.000000' 上述默认小数点后六位,需要手动指定保留小数点后边位数: >>> '{:.

java BigDecimal用法详解(保留小数,四舍五入,数字格式化,科学计数法转数字等)
阿里云低价服务器1折特惠,优惠爽翻天,点我立即低价购买 一、简介 Java在java.math包中提供的API类BigDecimal,用来对超过16位有效位的数进行精确的运算。双精度浮点型变量double可以处理16位有效数。在实际应用中,需要对更大或者更小的数进行运算和处理。float和double只能用来做科学计算或者是工程计算,在商业计算中要用java.m
【C语言中的科学计数法】
C语言中的科学计数法 在数学中,科学计数法指代==>把数表示成a与10的N次幂相乘的形式。(1<=|a|<=10) 但对于c语言中,科学计数法通常使用e或者E来表示指数的部分,对于前面的a并没有明确的范围限制。 基本的格式是:[正负号]数字.数字 E(e) [正负号] 整数 两个数字:代表十进制数字部分。e和E本身无意义,但是用于表示接下来是指数部分。 举例: 如 1.4e+5 就

解决PyQt5中柱状图上显示的数值为带e的科学计数法
PyQt5生成柱状图的代码参考:PyQt5 QtChart-柱状图 参照上述文章,生成柱状图后,数值较大或较小情况下会导致柱状图上显示数值为带e的科学计数法,这样会影响数值的识别: 经过分析QBarSet方法得到解决方法:需要删除掉barSeries.setLabelsPrecision(2)这行代码。barSeries.setLabelsPrecision(2)这行代码的意思是设置柱状图
np.savetxt保存数据时不使用科学计数法形式,保留原数据
import numpy as npdata = np.array([[1.2345, 6.78901, 2.34567]])np.savetxt('./data1.txt', data) 上面的代码输出为 1.234499999999999931e+00 6.789010000000000211e+00 2.345670000000000144e+00 未指定存储格式,会默认使用科

go 科学计数法 大数值转string 串 求和等等
最近区块链中的数值超大 会自动转换成字符串看着好别扭,go官方也没有较好的库 通过查找在git上找到了库: 引用导入 go get github.com/shopspring/decimal 代码: import ("fmt""github.com/labstack/gommon/log""github.com/shopspring/decimal""strconv")fu
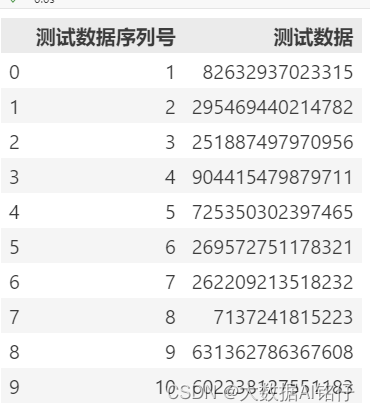
【已解决】pandas读excel中长数字变成科学计数法的问题
pandas 读excel中的长数字时,即使excel中已经设置为文本,读进df后也会自动变成科学计数法。 在日常的数据分析和处理工作中,Excel和pandas是数据分析师们不可或缺的得力助手。然而,在使用pandas读取Excel文件时,我们有时会遇到一个令人头疼的问题:明明在Excel中已经把某些长数字列设置为了文本格式,但使用pandas读取进DataFrame(df)后,这些长数字却自动
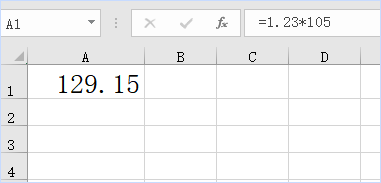
怎样将excel的科学计数法设置为指数形式?
对了,这个问题中所谓的“指数形式”是指数学上书写的右上标的指数格式,能不能通过单元格设置来做这个格式的转换呢? 一、几个尝试 以下,以数字123000为例来说明。 情况1.转换成数学上的书写方式,如下图的样子, 这个只能手工操作,在单元格中写入1.23x105,这里先有一个文本字符x,使得整体数据成为文本。然后到编辑栏,选中最后的数字5;点击开始选项卡,字体设置,勾选特殊效果中
教你如何将txt复制到excel的各个单元格;并解决科学计数法显示问题及导致的个位数变0问题
1.如果你的txt或log等文件中的数据每个数据刚好都回车了,那么直接粘贴到excel即可; 2.如果你的txt或log等文件中数据较多,回车之后的每一行数据仍需再次分列,那么要求:每一行中需要分列的数据是用特殊符号隔开的,具体操作方法如下,假如txt中数据是用“^”隔开的;特殊符号的好处是:内容中很少会出现特殊符号,分列的时候不会错分。 第一步:将需要的数据选中粘贴到excel中,这时候
【Java】bigdecimal转为string时会变成科学计数法 | 大数取消转换为科学计数法
遇见“隐形刺客” 在银行写代码,我们通常用BigDecimal来处理大数计算,确保精度无损,正所谓“精打细算”。然而,当你满怀信心地将BigDecimal转换为String,准备输出或存储时,突然发现它变成了一串让人眼花缭乱的科学计数法。在传给其他系统进行处理之后,直接一连串报错疯狂吸入,真是鸡妈妈摸孩子——完蛋。 为什么会变科学计数法 在Java中,当BigDecimal表示的数字非常大或
BigDecimal 加减乘除 | 比较大小 | 取最大最小值 | 保留小数位 |转String|科学计数法
BigDecimal 加减乘除 | 比较大小 | 取最大最小值 | 保留小数 一、加减乘除 BigDecimal num1 = new BigDecimal(2);BigDecimal num2 = new BigDecimal(6);BigDecimal num3 = null;-- 加 2+6 num3 = num1.add(num2); -- 结果:8-- 减 6-2nu
CSV文件中长数字自动变成科学计数法怎么处理?
有这么3个方法,优劣自己判断,根据实际情况使用。 1.在前面加个前缀,比如单引号'或者英文字母什么的,如D test,442354141123变成: test,'442354141123 或 test,D442354141123 2.在末尾加上制表符,可以复制上去。 test,442354141123变成: test,"442354141123 " 3.在前加
Java中数值较大的double类型转换为字符串时会用科学计数法显示的解决办法
java.text.NumberFormat nf = java.text.NumberFormat.getInstance(); // 不使用千分位,即展示为11672283.234,而不是11,672,283.234 nf.setGroupingUsed(false); // 设置数的小数部分所允许的最小位数 nf.setMinimumFractionDigits(0); //
ios 科学计数法,保留n个有效值
/*科学计数法,保留n个有效值*/-(NSString *) toExponent:(double)d rms:(unsigned)n{if(n==0){return nil;}CFLocaleRef currentLocale = CFLocaleCopyCurrent();CFNumberFormatterRef customCurrencyFormatter = CFNumberForma
数据导出为csv文件时 数值型数据为科学计数法 时间被截取的解决方法
数据导出为csv文件时 数值型数据为科学计数法 时间被截取的解决方法 2013-02-20 15:36 by swarb, ... 阅读, ... 评论, 收藏, 编辑 输入前 在每个字段前面加个"\t" 即可
Gson系列6 --- 问题篇 -- GSON处理JSON数据中Long型的数据变成 科学计数法的问题解决方案
对于 Gson 转换数值long 类型有一定的缺陷,总是转换成科学计数法的形式 Gson 转换long到科学计数法的解决方法 如下json {"username":"tomcat","uuid":123456789012} 转成的结果 {username=tomcat, uuid=1.23456789012E11} 很明显,不符合我们的要求, 因此需要改变 所需的依赖