本文主要是介绍【已解决】pandas读excel中长数字变成科学计数法的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
pandas 读excel中的长数字时,即使excel中已经设置为文本,读进df后也会自动变成科学计数法。
在日常的数据分析和处理工作中,Excel和pandas是数据分析师们不可或缺的得力助手。然而,在使用pandas读取Excel文件时,我们有时会遇到一个令人头疼的问题:明明在Excel中已经把某些长数字列设置为了文本格式,但使用pandas读取进DataFrame(df)后,这些长数字却自动变为了科学计数法的表示形式。
这个问题看似简单,但却会给后续的数据处理和分析带来不少麻烦。特别是对于需要精确处理这些长数字的同事来说,比如我们的同事小卷王,他最近就遇到了这样的困扰。小卷王在处理一份包含订单编号的Excel文件时,发现原本清晰可见的订单编号在读取到pandas的DataFrame后变得面目全非,变为了难以直接识别和使用的科学计数法表示。
为了帮助小卷王解决这个问题,也为了让更多遇到类似困扰的同事能够顺利解决这一难题,我特地撰写了本篇博客。
源数据:
import pandas as pd
data_path = r"C:\Users\Desktop\table.xlsx"
data = pd.read_excel(data_path)
data.head()
数值型数据

科学计数法显示的数据
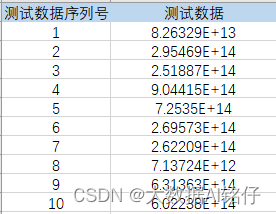
python中显示就是这样滴

解决方法
import pandas as pd
data_path = r"C:\Users\Desktop\table.xlsx"
'''在读取时加上converter参数,先转成str再读'''
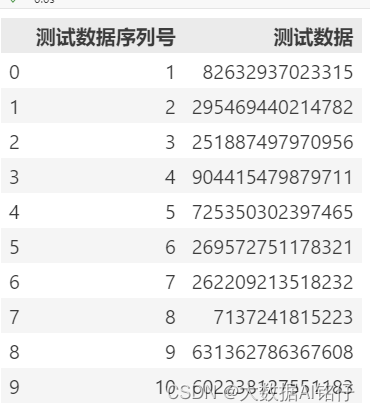
data = pd.read_excel(data_path, converters={'测试数据':str})
data.head()结果:
对于上述问题的解决方法,我们期待您在评论区分享您的看法和讨论。如果您觉得这篇文章对您有所帮助,请不要吝啬您的点赞和收藏,您的支持是我持续分享知识和经验的最大动力。让我们一起在解决问题的道路上不断前行,共同进步!
这篇关于【已解决】pandas读excel中长数字变成科学计数法的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



