第一页专题

python使用get在百度搜索并保存第一页搜索结果
python使用get在百度搜索并保存第一页搜索结果 作者:vpoet 日期:大约在夏季 注:随意copy,不用在意我的感受 #coding:utf-8import urllibimport urllib2import re"""使用GET在百度搜索引擎上查询此例演示如何生成GET串,并进行请求."""if __name__=="__main__":url =

word自动生成目录如何从正文第一页开始
word2007: 1.自动生成目录:引用--目录; 2.插入--页码; 3.在目录后面空白位置单击,页面布局--分隔符--下一页; 3.在你的正文第一页,双击页脚,取消“链接到前一条页眉”;然后,页码--设置页码格式,选择“起始页码”--确定。 你会发现此时页码从正文的第一页开始了,然后,单击目录,重新生成即可。(此时目录的页码已经和正文的页码分开了,你可以通过页码--设置页码格式--
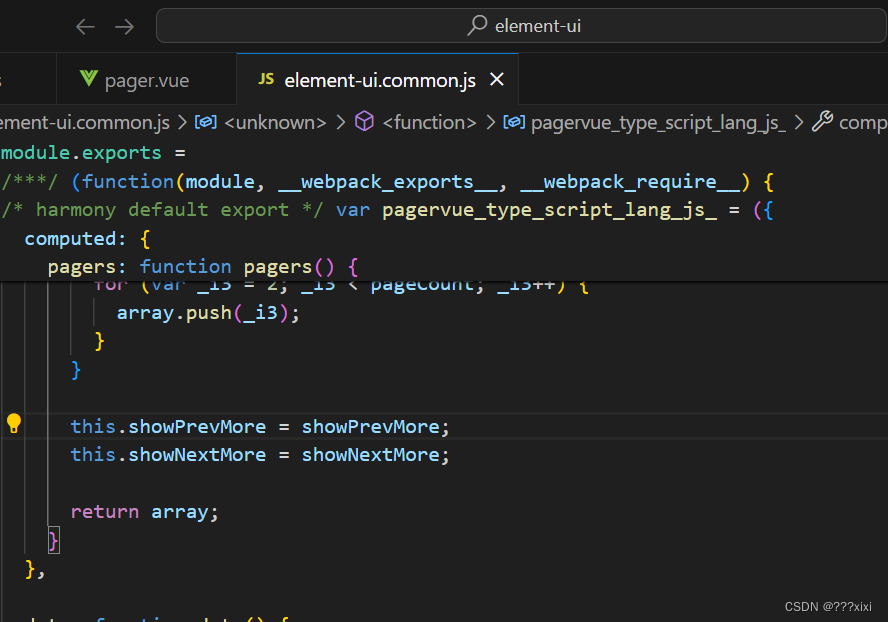
el-pagination在删除非第一页的最后一条数据遇到的问题
文章目录 前言一、问题展示二、解决方案三、源码解析1、elementui2、elementplus 总结 前言 这个问题是element-ui中的问题,可以从源码中看出来,虽然页码更新了,active也是对的,但是未调用current-change的方法,这里就不是很合理。我先是在网上找的答案,然后改好之后去看的源码。因为大都是只说怎么改的,没有解析源码,我就记录一下;本来寻

printjs打印表格的时候多页的时候第一页出现空白
现象:打印多页的时候第一页空白了,一页的时候没有问题 插件:printjs 网上搜索半天找到的方式解决: 1. 对于我这次的现象毫无作用。其他情况不得而知,未遇见过。(这个应该是大家用的比较多的方式) printJS({ printable: [`data:image/jpg;base64,${this.printData.url}`], type: 'image', st
将一个文件夹的pdf都去掉第一页后生成在另一个文件夹
目录 一.前言 二.环境配置 三.完整代码 一.前言 在日常的工作和学习中,我们经常需要处理大量的PDF文件。有时候,我们可能希望将一个文件夹中的所有PDF文件进行一些特定的操作,例如去掉每个PDF文件的第一页。 为了解决这个问题,本项目旨在提供一个自动化的解决方案,可以批量处理一个文件夹中的PDF文件,并将处理后的文件生成到另一个目标文件夹中。 该项目采用了Python

Latex 第一页出现空白
latex编译的时候出现如下空白 用\begin{titlepage}和\end{titlepage}让latex把第一页当成封面 虽然我们不能直接删除,但后期交pdf的时候删掉第一页就好

批量提取PDF指定区域内容到 Excel 以及根据PDF里面第一页的标题来批量重命名-附思路和代码实现
首先说明下,PDF需要是电子版本的,不能是图片或者无法选中的那种。 需求1:假如我有一批数量比较多的同样格式的PDF电子文档,需要把特定多个区域的数字或者文字提取出来 需求2:我有一批PDF文档,但是文件的名称都是一些乱码,我需要根据PDF文件里面第一页内容的标题来批量重命名这些文件 需求1思路:我们任意选一个PDF文件作为样本,然后用代码把要提取的区域用方框标注出来,再然后把这些区域的

php开发项目 docx,pptx,excel表格上传阿里云,腾讯云存储后截取第一页生成缩略图
服务器或者存储上传的word,ppt和excel表格需要截取内容展示的时候,就需要管理后台每次上传文件时根据不同文件类型截取图片保存起来,并讲图片的地址保存到数据字段中.网上搜索了很多相关文章遇到的坑不少,经过2天时间终于完成了,将代码和遇到的问题完整记录下来. 本文用的方案是:首先给服务器安装libreoffice;文章下面记录有在开发途中遇到的问题,如果文档中文乱码,gs命令报错
php docx,pptx,excel表格上传阿里云,腾讯云存储后截取第一页生成缩略图
php把word转图片的方法:首先给服务器安装libreoffice;然后使用exec函数来调用命令行操作;最后通过“exec(“soffice --headless --invisible…””方法把word转图片即可。 服务器环境:centos7 *集成环境:宝塔 我们开始给服务器安装libreoffice 直接执行下面的代码就可以(第一个安装好就ok了,后面两个安装的时候可能会报
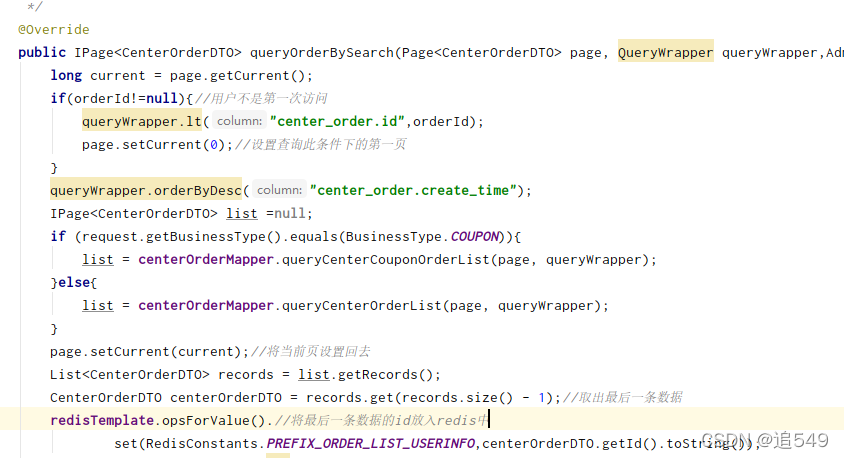
记录一次分页查询第一页和第二页数据重复问题
前端使用的是ajax查询,根据订单时间倒叙查询,查询第一页后,下滑查询第二页,此时数据库更新,第二页和第一页的数据有重复 。 解决方案:每次返回分页信息的时候将最后一条数据的时间或者id记录下来放在redis中 当前端传过来的分页信息pageNo=null或者0时,删除缓存,如果pageNo!=0时,查询条件加上时间小于redis中的值,并将pageNo设为0;

使用分页问题:点击第二页然后查询,数据显示为第一页的问题解决
使用分页问题:点击第二页然后查询,数据显示为第一页的问题解决 关于分页,这是在工作中接触vue+element由于逻辑混乱导致的,前几天在改系统BUG没来的及整理,今日开始动手整理,因为跨页面较多,可能会有遗漏,后续发现问题会继续补充。 具体问题是,分页后数据共两页,点击第二页查看第二页信息正常,但是如果停留在第二页上去执行查询操作,刷新回来的数据会在第二页显示,经过修改这个问题被解决,但是又

Vue项目之分页功能只显示第一页,后面有数据点击第二页也不显示
最近做项目遇到了一个小问题,就是我已经设置了6条数据,但是点击第二页却不显示第二页的数据,仍然在第一页,如下图 首先总条数是对的,说明后端返回回来的数据是正确的。 然后去前端查找与分页相关的内容,结果发现前端vue的方法里面并没有将后端返回的page和size赋给我们前端的变量。(如果不确定val是什么,可以照图中console.log一下) 所以,将其改正过来(记得赋值后,要再调用

jaspersoft 创建报表 第一页显示数据,第二页不显示数据
在variables中,创建了一个函数 设置这个函数放在page footer中 打印效果中,第一页数据显示,第二页数据不显示 解决方案: 设置数据的属性

如何让你的网站排在第一页?SEO诊断分析报告来帮你!
终于,SEO 系列来到了正篇的终章,恭喜你,你很快就可以向更加专业的 SEO 专家再迈进一步了! 今天,我们将和你一起,带上之前所学的知识、技巧,从实战出发,像手术台上的主刀医生那样,逐步剖析一个网站的状态,发现它存在的问题,并给出解决方案,最终完成一份专业的 SEO 诊断报告! 你虽然已经掌握了一系列 SEO 优化的知识与方法,但这并不意味着你已经将它们融会贯通,接下来的时间,还是跟着我

Python爬虫 使用Selenium爬取京东第一页商品的差评
使用Python中的Selenium库爬取京东口罩第一页的差评 实验目的Selenium库谷歌浏览器驱动参考代码实验结果写在最后 实验目的 使用Python中的Selenium库爬取京东口罩第一页的差评,以商品名称保存为txt文件 Selenium库 需要使用Selenium库,如无这个库的话请使用pip命令自行安装 pip install selenium 谷歌浏

BUUCTF自习笔记第一页加第二页一道笔记
SQL注入 BlackList的题目笔记(堆叠注入时新操作) 堆叠注入新姿势 预编译HANDLER Statement (运用于BlackList和他的上一道题目) Mysql注入 Hard 【极客大挑战 2019HardSQL】 题目描述呢,是一道SQL的注入题目,本着题目不会在注入点设置太大难度的想法,笔者上来先尝试使用or '1' = '1 'or'1'='1这样逻辑判断尝试,结

分页第一页用0还是1_0-1!皇马又崩了,防线被3脚妙传打穿,有拉莫斯坐镇也不管用...
北京时间10月28日凌晨4点,欧冠小组赛第2轮一场焦点战,西甲豪门皇马客场挑战门兴格拉德巴赫。带着联赛3-1完胜巴萨的气势,皇马力争结束欧冠三连败,然而,开场仅仅33分钟,现实就给他们泼了一盆冷水,他们又一次率先丢球了。 从场面上看,皇马占据着绝对的优势,射门次数非常多,但射正却不多,得势不得分。而门兴虽然很被动,但效率更高,逮住一脚射门,就洞穿了库尔图瓦的十指关。这球进得很漂亮,皇马的防
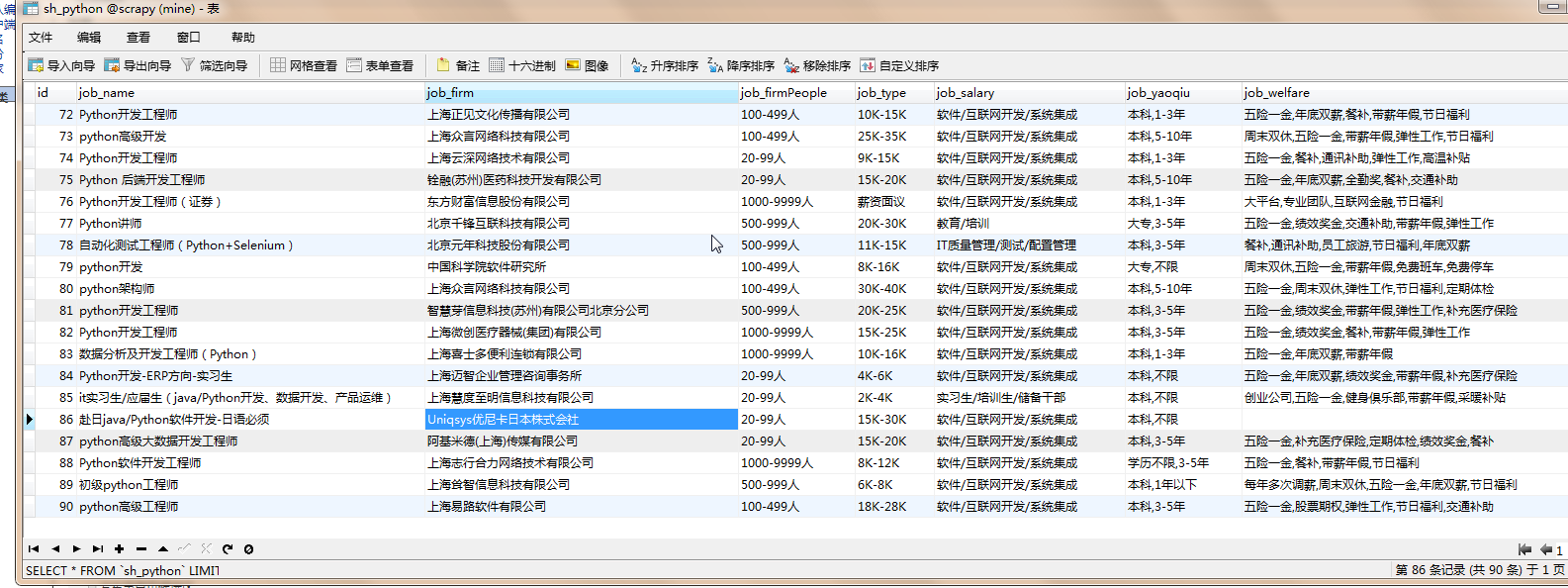
Scrapy框架爬取智联招聘网站上海地区python工作第一页(90条)
1. 创建项目: CMD下 scrapy startproject zhilianJob 然后 cd zhilianJob , 创建爬虫文件 job.py: scrapy genspider job xxx.com 2. settings.py 中: USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWeb

使用easyui工具,分页工具栏总是显示1到NaN,共NaN条记录,且只能够显示第一页的问题?
在控制层没有给easyui的参数total赋值。 只有给easyui传递返回的参数total,页面才能够知道数据库查询出了多少条数据,从而在分页的时候进行适应。

爬虫剑谱第一页(网课笔记)
什么是爬虫? 通过编写程序,模拟用户进行网页浏览,获取网页数据。 爬虫可以用来干什么? 抓取互联网上的数据,如新闻聚合阅读器、不同区域间的价格差价、美女(正能量)图片、编程技术大全等等。 其次,在当下大数据时代的大背景下,爬虫工程师也会拥有较大的发展空间,爬虫技术的应用也会也来越广泛。 总的来说,爬虫在实际应用和就业方面都有不俗的表现以及需求。 网课链接:2020年Pytho

Qt Object 类简介--Qt 类简介专题(二) 第一页
给大家推荐一个学习Qt 和 Android 的网站(http://newfaction.net/ ),挺不错的。。gaga Qt Object 类简介--Qt 类简介专题(二) 详细描述 QObject类是所有Qt对象的基类。 QObject是Qt对象模型的中心。这个模型的中心特征就是一种用于无缝对象通讯的被叫做信号和槽的非常强大的机制。你能够使用connect()把信号