李沐学专题

跟李沐学AI:语言模型
语言模型定义 假设在给定长度为T的文本序列中的词元依次为,可被人做文本序列在时间步t处的观测或标签。在给定这样的文本序列是,语言模型的目标是估计序列的联合概率。 一个理想的与语言模型能够在一次抽取一个词元的情况下基于模型本身生成自然文本。 学习语言模型 基于语言模型的基本规则,一个包含了四个单词的文本序列的概率是: 为了训练语言模型,我们需要计算单词的概率, 以及给定前面几个单词后出

跟李沐学AI:样式迁移
样式迁移需要两张输入图像:一张是内容图像,另一张是样式图像。 我们将使用神经网络修改内容图像,使其在样式上接近样式图像,得到合成图片。类似手机相册中的滤镜效果。 奠基性工作:基于CNN的样式迁移 任务:训练一个合成图片,融合另外两张图片的样式和内容。 首先,我们初始化合成图像,例如将其初始化为内容图像。合成图像是风格迁移过程中唯一需要更新的变量,即样式迁移所需迭代的模型参数。 然后,

动手学习深度学习-跟李沐学AI-自学笔记(3)
一、深度学习硬件-CPU和GPU 芯片:Intel or AMD 内存:DDR4 显卡:nVidia 芯片可以和GPU与内存通信 GPU不能和内存通信 1. CPU 能算出每一秒能运算的浮点运算数(大概0.15左右) 1.1 提升CPU利用率 1.1.1 提升缓存 再计算a+b之前,需要准备数据(CPU可能计算的快,但是内存很慢) 主内存->L3->L2->L1->寄存器(进入
动手学习深度学习-跟李沐学AI-自学笔记(3)
一、深度学习硬件-CPU和GPU 芯片:Intel or AMD 内存:DDR4 显卡:nVidia 芯片可以和GPU与内存通信 GPU不能和内存通信 1. CPU 能算出每一秒能运算的浮点运算数(大概0.15左右) 1.1 提升CPU利用率 1.1.1 提升缓存 再计算a+b之前,需要准备数据(CPU可能计算的快,但是内存很慢) 主内存->L3->L2->L1->寄存器(进入
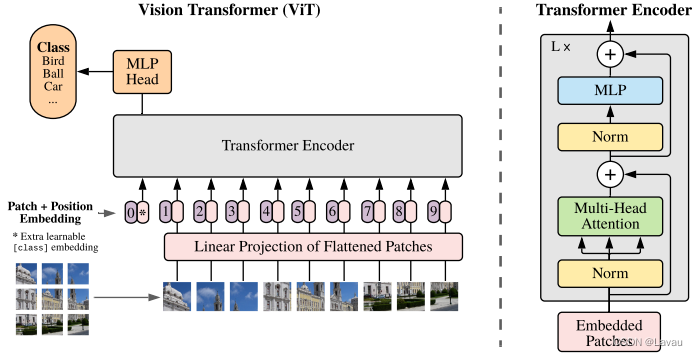
ViT 论文逐段精读——B站up:跟李沐学AI讲解笔记
https://www.bilibili.com/video/BV15P4y137jb Vision Transformer 挑战了 CNN 在 CV 中绝对的统治地位。Vision Transformer 得出的结论是如果在足够多的数据上做预训练,在不依赖 CNN 的基础上,直接用自然语言上的 Transformer 也能 CV 问题解决得很好。Transformer 打破了 CV、NLP 之
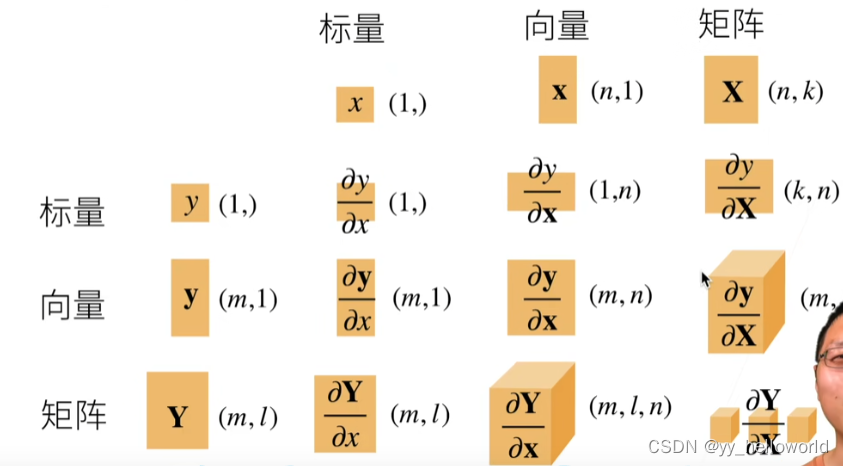
跟李沐学AI——动手学深度学习 PyTorch版——学习笔记pycharm版本(第二天——04-08)2023.2.27
一、基本数据操作知识 数据结构:标量、向量、矩阵 访问(记数是从0开始的): [1,2]:单个元素 [1,:]:单行 [:,2]:单列 [1:3,1:]:1到3行,第1列及后面的所有列 [::3,::2]:行跳3提取,列跳2提取 [-1]:最后一行 1、生成tensor数据 import torch # pytorch在导入的时候就是torchx=torch.arange(0,12) #