描述统计专题
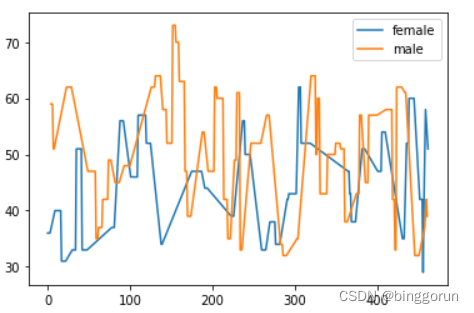
python实现描述统计
数据基础情况 import numpy as npimport pandas as pdimport matplotlib.pyplot as pyplotpd.options.display.max_rows = 10##最多输出10行数据data_url= 'https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cl

R语言系统教程(六):描述统计量
R语言系统教程(六):描述统计量 6.1 位置的度量6.1.1 均值6.1.2 顺序统计量6.1.3 中位数6.1.4 百分位数 6.2 分散程度的度量6.2.1 方差、标准差等6.2.2 极差等 6.3 分布形状的度量6.3.1 偏度系数6.3.2 峰度系数 6.1 位置的度量 6.1.1 均值 即样本期望,使用mean()函数计算,声明如下: mean(x, trim =


pandas的汇总和计算描述统计
pandas提供了很多常用的数学和统计方法,其中大部分都属于约简和汇总统计,用于从Series中提取单个值(如sum或mean)或从DataFrame的行或列中提取一个Series。 一、DataFrame的sum和mean方法 a = [[1,np.nan,9],[2,8,3],[3,5,np.nan]]data = DataFrame(a,index=["a","b","c"]
![[R分析] 描述统计:频数和频率分布直方图](https://img-blog.csdn.net/20180208121228445?watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvc2luYXRfMjU4NzM0MjE=/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[R分析] 描述统计:频数和频率分布直方图
n<-round(runif(1000,0,100)) #生成0到100的1000个随机数hist(n) #频数分布直方图,纵坐标名字为frequencyhist(n,freq = F) #频率分布直方图,纵坐标名字为density n<-rnorm(1000) #服从正态分布的1000个数hist(n)hist(n,freq = F)

sas简单描述统计分析和散点图
简单描述统计分析 一、 means过程 (一)例题和语句分析 例题1:某车间有30个人分成4组,求车间工人平均每小时制作的配件个数 data data3_1;input no w n; /*按自由格式输入变量no、w和n*/cards;01 10 3502 6 3203 8 2904 6 26;run;proc means data= data3_1 n
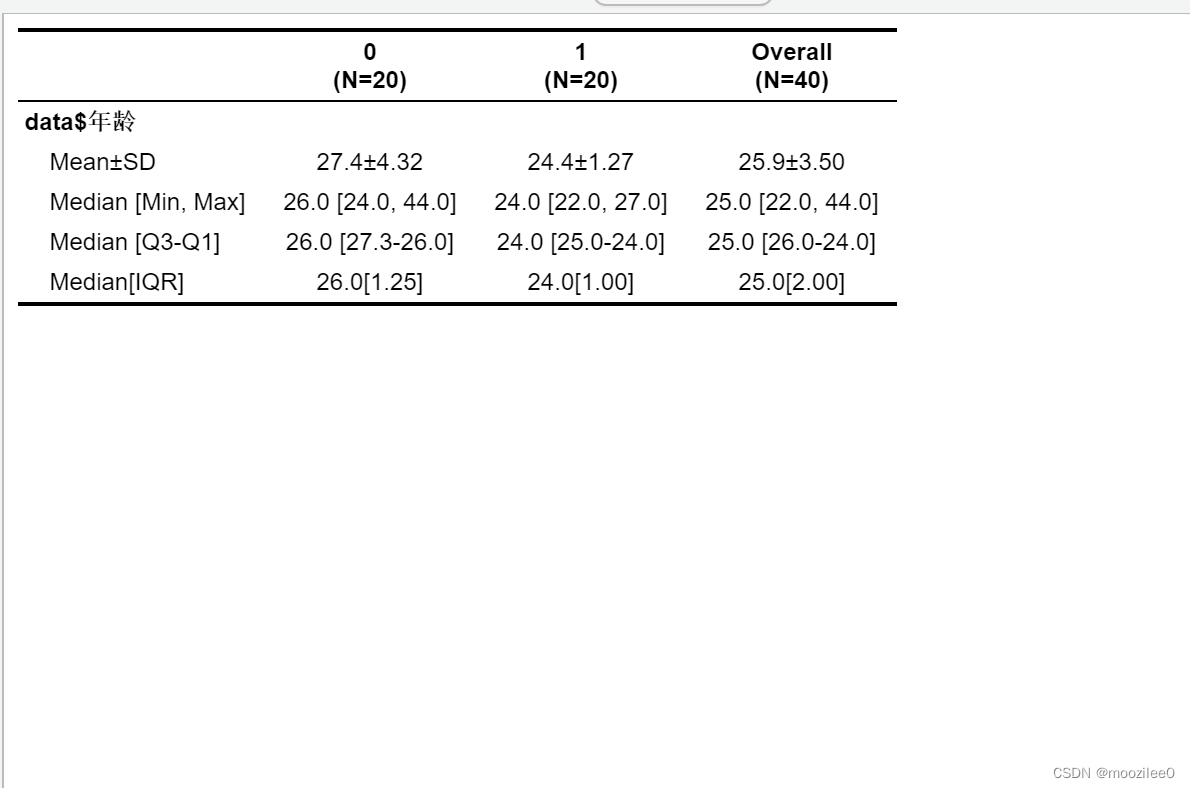
R语言描述统计(数值方法)
R语言描述统计 前言连续型变量均值计算自编函数进行均值和五数计算自编函数进行均值和标准差计算 使用R自带包进行均值计算Hmisc包psych 包tableone包 分类变量R自带函数gmodels包 前言 描述统计(Descriptive statistics)是描述总结观察对象的基本特征的统计方法的总称。数值方法指利用数据进行观察量位置,离散程度的描述。 连续型变量均值计
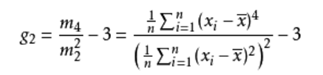
泛统计理论初探——高阶描述统计指标
统计学习-高阶统计指标 再谈描述性统计指标 在上一篇文章中,我们探讨了一些最常见的统计指标:比如中位数,平均数,众数等指标。其实上一篇文章讨论的都是一阶的统计指标,即根据当前的数据能够直接计算或观察得到的指标,这种一阶指标不需要再借助其他指标去做进一步计算的。那么既然有一阶指标,就会有二阶的指标以及高阶的指标。因此在本文中,我们将会介绍几种高阶的统计指标,并阐述如何在实际情况中去使用这些指标,从