拉链专题

数据仓库中的表设计模式:全量表、增量表与拉链表
在现代数据仓库中,管理和分析海量数据需要高效且灵活的数据存储策略。全量表、增量表和拉链表是三种常见的数据存储模式,各自针对不同的数据管理需求提供了解决方案。全量表通过保存完整的数据快照确保数据的一致性,增量表则通过记录数据的变化部分优化性能和存储效率,而拉链表则通过维护数据的历史版本满足复杂的分析和审计需求。了解这三种表的特点和应用有助于设计更为高效和可靠的数据仓库系统。 全量表(Full

大数据-数据仓库:快照表、拉链表,全量表,增量表
转载自 (15条消息) 大数据-数据仓库:快照表、拉链表,全量表,增量表_u013250861的博客-CSDN博客https://blog.csdn.net/u013250861/article/details/113732856
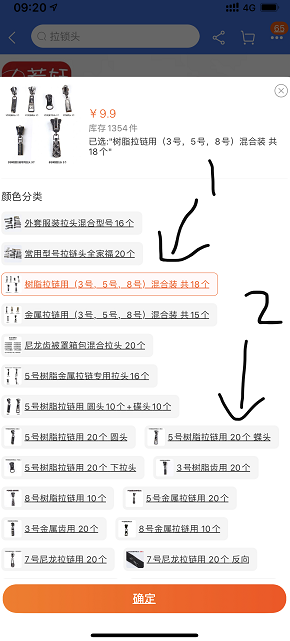
世事洞明皆学问-拉链拉头的拆分安装
分享一下自己生活中的坑,生活也是不断学习总结的过程。希望自己每天都开心。 一、事情背景: 昨天羽绒服拉链的拉头就坏了。自己琢磨了半天,还用蛮力使劲拉,结果拉头坏了。 去淘宝上,搜索了拉头,买了新的。 二、拆分问题: 羽绒服的拉链主要是两部分构成的,拉链和拉头。 根据材质不同呢,又分为,金属,尼龙和树脂(我的就是树脂的) 拉头还有不同的型号。可以看拉头背面会有数字。一般分为 3 5 8
Hive-拉链表的设计与实现
Hive-拉链表的设计与实现 在Hive中,拉链表专门用于解决在数据仓库中数据发生变化如何实现数据存储的问题。 1.数据同步问题 Hive在实际工作中主要用于构建离线数据仓库,定期的从各种数据源中同步采集数据到Hive中,经过分层转换提供数据应用。 解决方案 (1)直接更新 (2)全量快照 (3)构建拉链表 2.拉链表的设计

Scala---集合(数组,Map,元组(Tuple),Zip拉链)详解
scala的集合分为了两类,一类是可变的集合(集合可以执行增删改查操作),另一类是不可变集合(集合元素在初始化的时候确定,后续只能进行查,有的可以进行修改,有的不可以)。二者可能名称一样,但是在不同的包下面,对应的包为:scala.collection.mutable和scala.collection.immutable。scala默认使用的集合,或者默认导入的包是immutable。(说明:这里

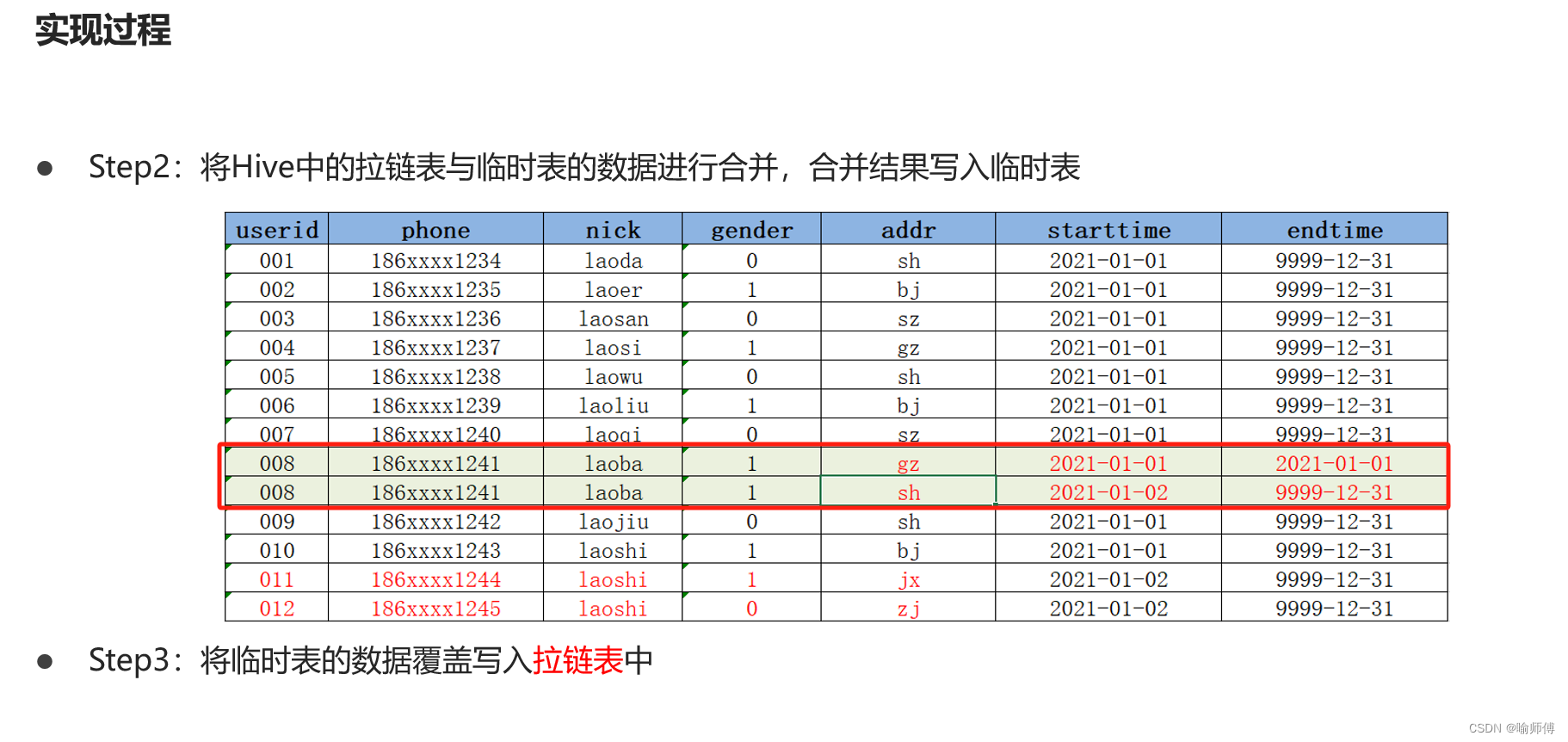
数据治理 - 数据仓库历史数据存储 - 拉链表
什么是拉链表 拉链表是针对数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。 我们先看一个示例,这就是一张拉链表,存储的是用户的最基本信息以及每条记录的生命周期。我们可以使用这张表拿到最新的当天的最新数据以及之前的历史数据。 注册日期用户编号手机号码t_start_datet_end_date2017-01-0
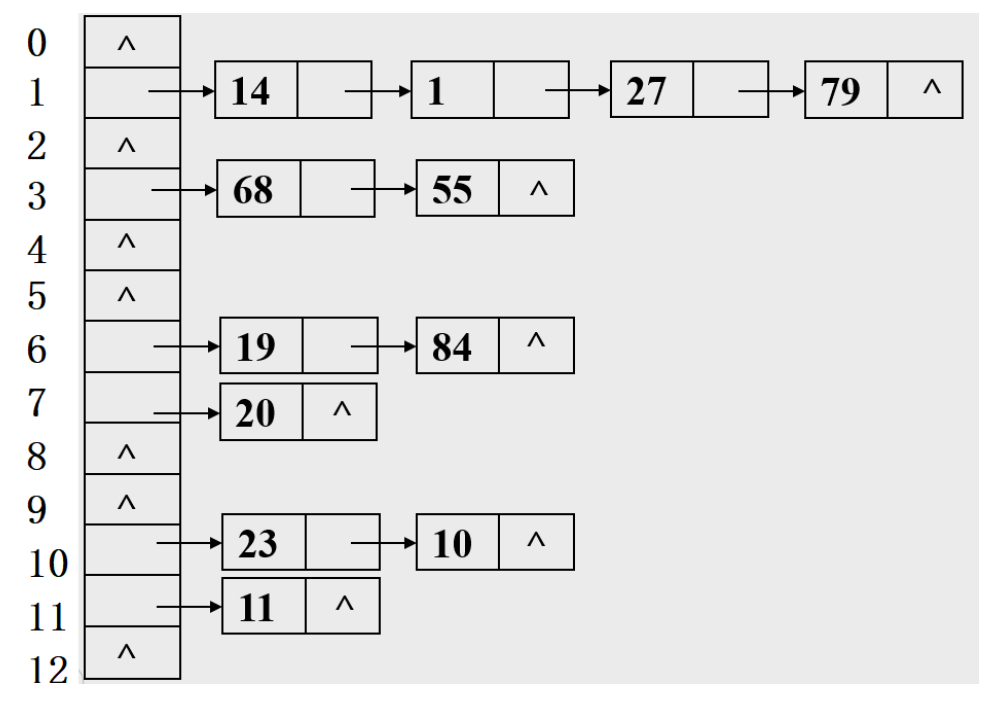
【深入解析算法】基于拉链法的散列表
8.2 基于拉链法的散列表 一个散列函数能够将键转化为数组索引。散列算法的第二步是碰撞处理,也就是处理两个或多个键的散列值相同的情况。一种直接的办法是将大小为M的数组中的每个元素指向一条链表,链表中的每个结点都存储了散列值为该元素的索引的键值对。这种方法被称为拉链法,因为发生冲突的元素都被存储在链表中。这个方法的基本思想就是选择足够大的M,使得所有链表都尽可能短以保证高效的查找。查找分两步:首
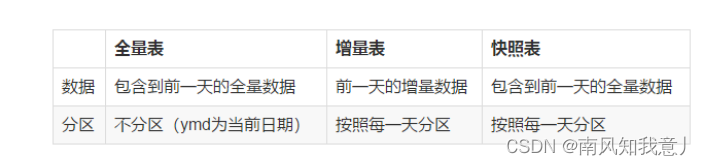
数仓之缓慢变化维(拉链表)
文章目录 缓慢变化维拉链表 -- 理论缓慢变化维解决方案:拉链表场景:拉链表缺点:拉链表查询优化: 拉链表 -- 示例sql查询方式 补充流水表全量表增量表 缓慢变化维 什么是缓慢变化维? 缓慢变化维,简称SCD(Slowly Changing Dimensions) 一些维度表的数据不是静态的,而是会随着时间而缓慢地变化(这里的缓慢是相对事实表而言,事实表数据变化的速度比
数据结构 - 哈希表(开放地址法、拉链法、字符串前缀哈希)
文章目录 前言Part 1:模拟散列表1.题目描述输入格式输出格式数据范围输入样例输出样例 2.算法(开放地址法)3.算法(拉链法) Part 2:字符串哈希1.题目描述输入格式输出格式数据范围输入样例输出样例 2.算法(字符串前缀哈希) 前言 本篇博客将介绍哈希表的存储方式(拉链法、开放地址法),以及一类十分重要的应用字符串哈希,字符串哈希可以取代KMP功能十分强大,而
「建模学习」zbrush中如何制作拉链?拉链笔刷来帮忙,轻松搞定
zbrush提供了很多笔刷,很多物件我们可以直接用笔刷刷出来。其功能非常的强大也非常的方便。在这里我用zbrsuh4R6版本来介绍zbrsuh提供的拉链笔刷。 注:在使用zbrush提供的IMM笔刷之前,模型需要删除细分等级。 拉链笔刷介绍: 1.拉链笔刷的命名是IMM ZipperP和IMM ZipperM这两个笔刷。 zbrush拉链笔刷位置 这两个笔刷的区别在于刷出来的拉链形状
拉链表的概念设计与实现
拉链表 一、概念 拉链表是针对数据仓库设计中表存储数据的方式而定义的,所谓拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。 用处: 解决持续增长且存在一定时间时间范围内重复的数据 场景: 数据规模庞大,新数据【在有限的时间】内存在多种状态变化 原来解决方案: 采用分区表,用户分区存储历史增量数据,缺点是重复数据太多 优点: 节约空间 二、拉链表的设计 以订单为例:
hive拉链表实现实例
1、准备数据表userods create table userods(u_name string,u_pwd string,u_register date,u_des string) row format delimited fields terminated by '\t'; 2、准备增量表user_inc create table user_inc(u_name string,u_p
Hive拉链表设计、实现、总结
水善利万物而不争,处众人之所恶,故几于道💦 文章目录 环境介绍实现1. 初始化拉链表2. 后续拉链表数据的更新 总结彩蛋 - 想清空表的数据:转成内部表,清空数据后,再转成外部表,将分区目录删掉,然后再次跑脚本,其他表都没问题就拉链表新算出过期分区的数据拉不进去,这是啥原因?有高人指点一下吗? 环境介绍 拉链表可以用来记录数据的声明周期,适合那种数据量大但新
哈希冲突详解(拉链法,开放地址法)
哈希冲突详解 我喜欢用问答的形式来学习,这样可以明确许多不明朗的问题。 什么是哈希冲突? 比如我们要去买房子,本来已经看好的房子却被商家告知那间房子已经被其他客户买走了。这就是生活中实实在在的冲突问题。 同样的当数据插入到哈希表时,不同key值产生的h(key)却是相等的,这个时候就产生了冲突。这个时候就要解决这个问题。 怎么解决哈希冲突? 方法1:拉链法 方法2:开地
hash table(哈希表)的拉链法程序
哈希表拉链法,简单,直接看代码: #include <iostream>using namespace std;struct Node{int iData;Node* pNext;};#define N 10typedef Node* HashTable[N]; // 指针数组HashTable hTable;void createHashTable(int a[],
用户维度表(拉链表)
步骤0:初始化拉链表(首次独立执行) (1)建立拉链表 hive (gmall)> drop table if exists dwd_dim_user_info_his; create external table dwd_dim_user_info_his( id string COMMENT ‘用户id’, name string COMMENT ‘姓名’, birthday string C

(35)用户维度表(拉链表)
用户表中的数据每日既有可能新增,也有可能修改,但修改频率并不高,属于缓慢变化 维度,此处采用拉链表存储用户维度数据。 1 )什么是拉链表 2)为什么要做拉链表 3)拉链表形成过程 4)拉链表制作过程图 5 )拉链表制作过程 步骤 0 :初始化拉链表(首次独立执行) ( 1 )建立拉链表 (2)初始化拉链表
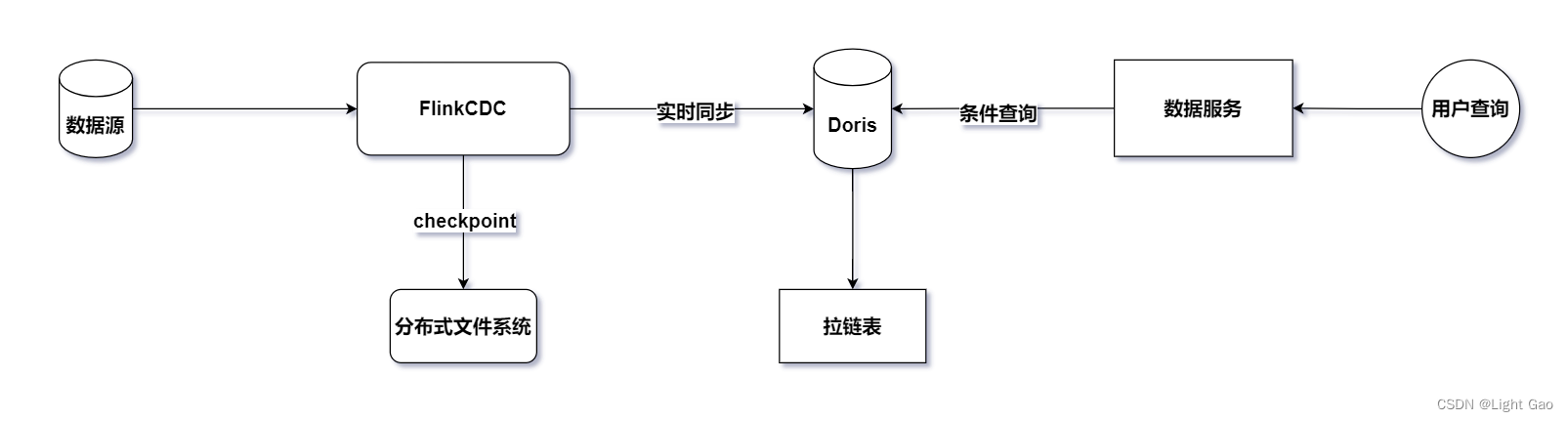
Flink实时数仓同步:拉链表实战详解
一、背景 在大数据领域,业务数据通常最初存储在关系型数据库,例如MySQL。然而,为了满足日常分析和报表等需求,大数据平台会采用多种不同的存储方式来容纳这些业务数据。这些存储方式包括离线仓库、实时仓库等,根据不同的业务需求和数据特性进行选择。 举例来说,假设业务部门需要在大数据平台中查看历史某一天的表数据,如下: [Mysql] 业务数据 - 用户表全量数据: idnamephonegen

用spark模拟拉链表
拉链,就是记录历史。记录一个事物从开始,一直到当前状态的所有变化的信息。包含了拉链起始时间和结束时间 业务系统可能会覆盖数据,但是抽取过来的所有数据都做了拉链操作后,可以记录历史所有的状态。 删除和更新记录在etl_flag上,是删除还是更新还是插入(D,U,I),苍南所有的拉链操作通过存储过程实现。 RRS是根据数据创建一直往里面插入,然后定期归档(历史数据备份,然后表中删除这部分数据)。
C++ 模拟散列表 || 哈希表存储与查询,模版题(拉链法)
维护一个集合,支持如下几种操作: I x,插入一个整数 x ; Q x,询问整数 x 是否在集合中出现过; 现在要进行 N 次操作,对于每个询问操作输出对应的结果。 输入格式 第一行包含整数 N ,表示操作数量。 接下来 N 行,每行包含一个操作指令,操作指令为 I x,Q x 中的一种。 输出格式 对于每个询问指令 Q x,输出一个询问结果,如果 x 在集合中出现过,则输出 Yes,否则

Scala 集合类的应用【Map映射、filter过滤、化简、折叠、扫描、拉链、迭代器、stream流、View试图、并行集合、操作符】
文章目录 Map 映射的操作应用1. 实际需求2. 高阶函数解决实际需求3. 使用 map 映射来解决4. 模拟实现 map 函数机制5. flatmap 映射(扁平化) 集合元素过滤 filter化简(reduceLeft,reduceRight,reduce)折叠(foldLeft,foldRight)扫描(scanLeft,scanRight)综合案例拉链(zip 合并)迭代器 ite