本文主要是介绍Hive拉链表设计、实现、总结,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
水善利万物而不争,处众人之所恶,故几于道💦
文章目录
- 环境介绍
- 实现
- 1. 初始化拉链表
- 2. 后续拉链表数据的更新
- 总结
- 彩蛋 - 想清空表的数据:转成内部表,清空数据后,再转成外部表,将分区目录删掉,然后再次跑脚本,其他表都没问题就拉链表新算出过期分区的数据拉不进去,这是啥原因?有高人指点一下吗?
环境介绍
拉链表可以用来记录数据的声明周期,适合那种数据量大但新增和修改频率不是很高的场景。比如总共100万条数据,每天新增大约1万条,修改1万条,这种变化不是很大的维度数据可以用拉链表来存。
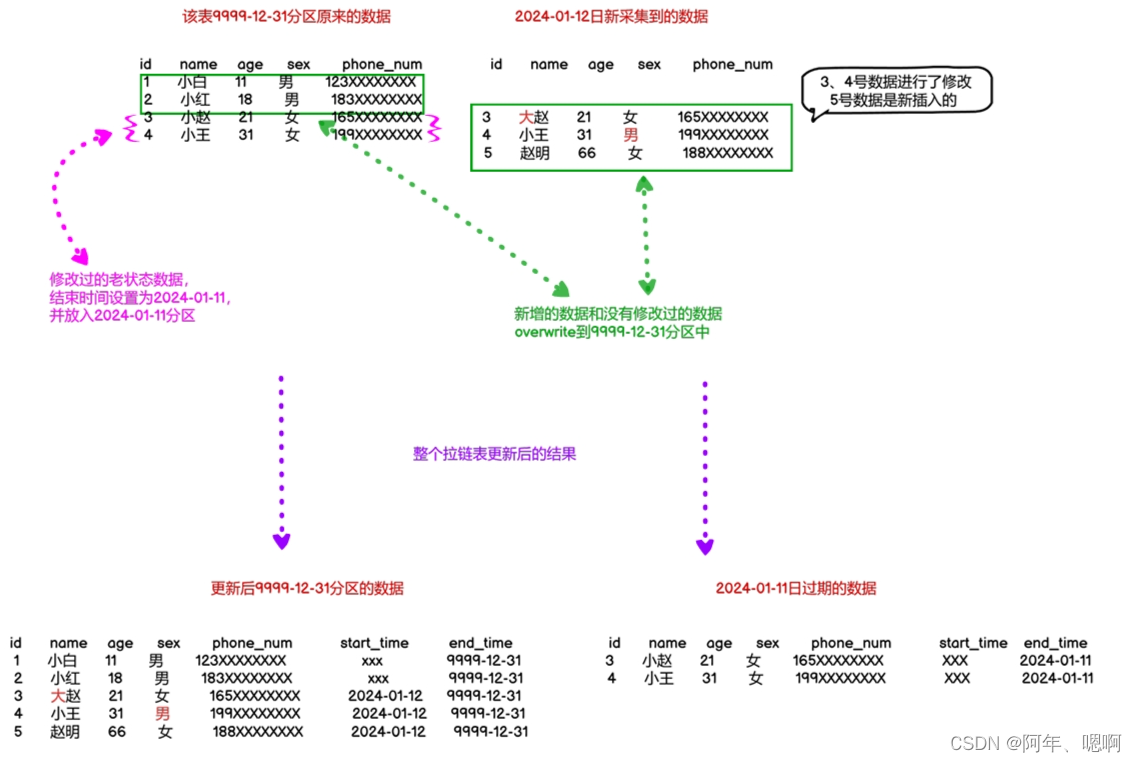
我们这里将拉链表中每日最新的数据放入到9999-12-31分区中,过期的数据放入到前一天的分区中。
比如,2024-01-12日所有新增和修改数据(该拉链表采用增量同步)被采集到数仓的ODS层中,进入DIM层的时候将2024-01-12日修改过的老状态的数据(也就是过期数据)结束时间设置为前一天(标志该条数据生命周期结束),并放入前一天的分区中,而新增的数据和没有修改(没有修改过,那么这条数据的状态目前也是最新数据)过的数据放入到9999-12-31分区中,表示这张表最新状态的数据。
实现
1. 初始化拉链表
第一次向拉链表中导入数据的时候直接将ODS层中所有的数据overwrite到9999-12-31分区中就可以了,因为那天的数据就是最新的数据。
insert overwrite table dim_user_zip partition(dt="9999-12-31")
--insert overwrite local directory "ods_user2"
select
data.id,
data.login_name,
data.nick_name,
data.name,
data.phone_num,
data.email,
data.user_level,
data.birthday,
data.gender,
data.create_time,
data.operate_time,
date_format(nvl(data.operate_time,data.create_time),"yyyy-MM-dd") start_time,
"9999-12-31" end_time
from ods_user_info_inc
where dt="2024-01-11" and type="bootstrap-insert"
这步完成后就初始化完成了拉链表,也就对应上图中左上角那个 “该表9999-12-31分区原来的数据” 表中的数据。
2. 后续拉链表数据的更新
方式1:
新增数据和原来分区的数据进行 full join 然后判断选择要哪条数据,然后overwrite到表中就行了
with new as (select *,"2024-01-12" start_date,"9999-12-31" end_datefrom ods_user_info_incwhere dt = "2024-01-12"
), old as (select *from dim_user_zip_incwhere dt = "9999-12-31"
), full_user as (select old表的所有字段,new表的所有字段from old full join newon old.id=new.id
)
-- 将数据更新到dim层的拉链表中,这里采用动态分区,按最后一列选插入到哪个分区
insert overwrite table dim_user_zip_inc partition(dt)
select if(new_id is not null, new_id, old_id),......--取完表中的字段后,要多加一个字段,用来动态分区到哪个分区中,最新的数据要放入9999-12-31分区if(new_id is not null, new_end_date, old_end_date)
from full_user
-- 这是筛选出新增的数据和没有修改过的数据
where new_id is not null or (new_id is null and old_id is not null)
union all
select选出老数据的字段,注意最后一个失效时间要改成前一天cast (date_sub("2024-01-12", 1) as string),-- 最后还是要多加一个字段,用来动态分区到哪个分区中,过期的数据要放入前一天分区cast (date_sub("2024-01-12", 1) as string)
from full_user
-- 这是筛选出修改过的老数据
where new_id is not null and old_id is not null;========================================================================with new as (select id,login_name,nick_name,name,phone_num,email,user_level,birthday,gender,create_time,operate_time,start_date,end_datefrom (selectdata.id,data.login_name,data.nick_name,data.name,data.phone_num,data.email,data.user_level,data.birthday,data.gender,data.create_time,data.operate_time,"2024-01-12" start_date,"9999-12-31" end_date,row_number() over (partition by data.id order by ts desc) rnfrom ods_user_info_incwhere dt = "2024-01-12") t1where rn = 1), old as(select id,login_name,nick_name,name,phone_num,email,user_level,birthday,gender,create_time,operate_time,start_date,end_datefrom dim_user_zipwhere dt="9999-12-31"
), full_user as(selectold.id old_id,old.login_name old_login_name,old.nick_name old_nick_name,old.name old_name,old.phone_num old_phone_num,old.email old_email,old.user_level old_user_level,old.birthday old_birthday,old.gender old_gender,old.create_time old_create_time ,old.operate_time old_operate_time ,old.start_date old_start_date,old.end_date old_end_date,new.id new_id,new.login_name new_login_name,new.nick_name new_nick_name,new.name new_name,new.phone_num new_phone_num,new.email new_email,new.user_level new_user_level,new.birthday new_birthday,new.gender new_gender,new.create_time new_create_time ,new.operate_time new_operate_time ,new.start_date new_start_date,new.end_date new_end_datefrom old full join new on old.id=new.id
)
insert overwrite table dim_user_zip partition(dt)
selectif(new_id is not null,new_id,old_id),if(new_id is not null,new_login_name,old_login_name),if(new_id is not null,new_nick_name,old_nick_name),if(new_id is not null,new_name,old_name),if(new_id is not null,new_phone_num,old_phone_num),if(new_id is not null,new_email,old_email),if(new_id is not null,new_user_level,old_user_level),if(new_id is not null,new_birthday,old_birthday),if(new_id is not null,new_gender,old_gender),if(new_id is not null,new_create_time,old_create_time),if(new_id is not null,new_operate_time,old_operate_time),if(new_id is not null,new_start_date,old_start_date),if(new_id is not null,new_end_date,old_end_date),if(new_id is not null,new_end_date,old_end_date)
from full_user where new_id is not null or (new_id is null and old_id is not null)
union all
selectold_id,old_login_name,old_nick_name,old_name,old_phone_num,old_email,old_user_level,old_birthday,old_gender,old_create_time ,old_operate_time ,old_start_date,cast(date_sub("2024-01-12",1) as string),cast(date_sub("2024-01-12",1) as string)
from full_user where new_id is not null and old_id is not null;
方式二:
将旧数据和新数据都查出来然后union all到一起,然后根据用户id和start_time倒叙排序,编号为1的就是最新的数据,放到最新的分区,否则就是过期数据放到前一天的分区
with new as(-- 取出当天修改的最后一条结果select *,'2024-01-12' start_time,"9999-12-31" end_timefrom (select*,row_number() over (partition by user_id order by ts desc) rnfrom ods_user_info_incwhere dt = '2024-01-12') t1where rn = 1
), old as(select*from dim_user_zip_incwhere dt = "9999-12-31"
), full_user as(select * from newunion allselect * from old
), ordered as(select *,row_number() over (partition by user_id order by start_time desc) rnfrom full_user
)
insert overwrite table dim_user_zip_inc partition(dt)
select *,if(rn=1,"9999-12-31",cast(date_sub("2024-01-12",1) as string)),if(rn=1,"9999-12-31",cast(date_sub("2024-01-12",1) as string))
from ordered==============================================================================with new as(-- 取出当天修改的最后一条结果select id,login_name,nick_name,name,phone_num,email,user_level,birthday,gender,create_time,operate_time,start_time,end_timefrom(selectdata.id,data.login_name,data.nick_name,data.name,data.phone_num,data.email,data.user_level,data.birthday,data.gender,data.create_time,data.operate_time,"2024-01-12" start_time,"9999-12-31" end_time,row_number() over (partition by data.id order by ts desc) rnfrom ods_user_info_incwhere dt = '2024-01-12') t1 where rn=1
), old as(select id,login_name,nick_name,name,phone_num,email,user_level,birthday,gender,create_time,operate_time,start_date,end_datefrom dim_user_zipwhere dt = "9999-12-31"
), full_user as(select * from newunion allselect * from old
), ordered as(select id,login_name,nick_name,name,phone_num,email,user_level,birthday,gender,create_time,operate_time,start_time,end_time,row_number() over (partition by id order by start_time desc) rnfrom full_user
)
insert overwrite table dim_user_zip partition(dt)
--insert overwrite local directory "dim_user_zip2"
select id,login_name,nick_name,name,phone_num,email,user_level,birthday,gender,create_time,operate_time,start_time,if(rn=1,end_time,date_sub('2024-01-12',1)),if(rn=1,'9999-12-31',cast(date_sub('2024-01-12',1) as string))
from ordered
这样就完成了拉链表的制作,包括拉链表的初始化和后续拉链表数据的更新,以后只需要改里面的时间就可以了。
总结
拉链表第一次导入数据就都是最新状态的数据,然后新采集到的数据和最新状态的数据join后将最新状态的数据写入最新的分区,过期数据写入前一天的分区,注意日期不要交叉。
踩坑:脚本中日期引用不要使用双引号,使用单引号就行了,也就是sql中变量字符等用单引号,双引号写入脚本中,最后再套一个双引号有问题。
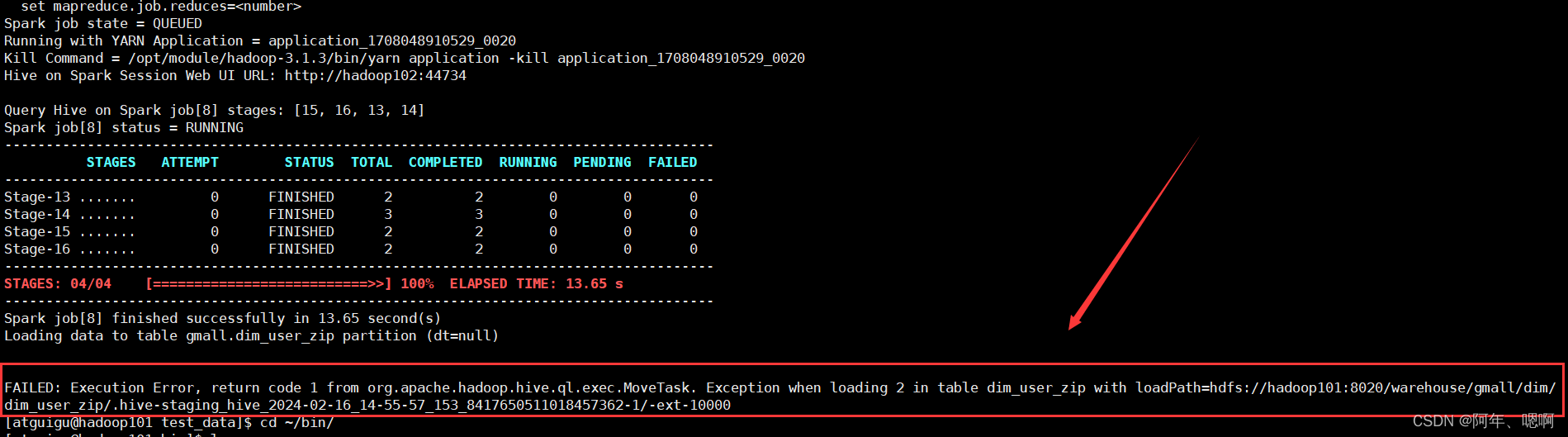
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.MoveTask. Exception when loading 2 in table dim_user_zip with loadPath=hdfs://hadoop101:8020/warehouse/gmall/dim/dim_user_zip/.hive-staging_hive_2024-02-16_14-55-57_153_8417650511018457362-1/-ext-10000
彩蛋 - 想清空表的数据:转成内部表,清空数据后,再转成外部表,将分区目录删掉,然后再次跑脚本,其他表都没问题就拉链表新算出过期分区的数据拉不进去,这是啥原因?有高人指点一下吗?
我目前的解决方案是:删除了表然后重新建下就好了。
我查的原因是文件有特殊字符(这个不太可能,同样的数据重建表就能,应该不是数据问题),修复元数据也没用,分区字段有问题(这个也没问题,我检查了),重建元数据库(这个不靠谱,没试)搞了好久,没找到根本原因,放弃了,有大哥知道的话,麻烦指点一下🎈
这篇关于Hive拉链表设计、实现、总结的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







