拉钩专题

python 爬取拉钩网数据
python 爬取拉钩网数据 #!/usr/bin/env python# -*- coding: utf-8 -*-import randomimport timeimport requestsfrom openpyxl import Workbookimport pymysql.cursorsdef get_conn():conn = pymysql.connect(host='
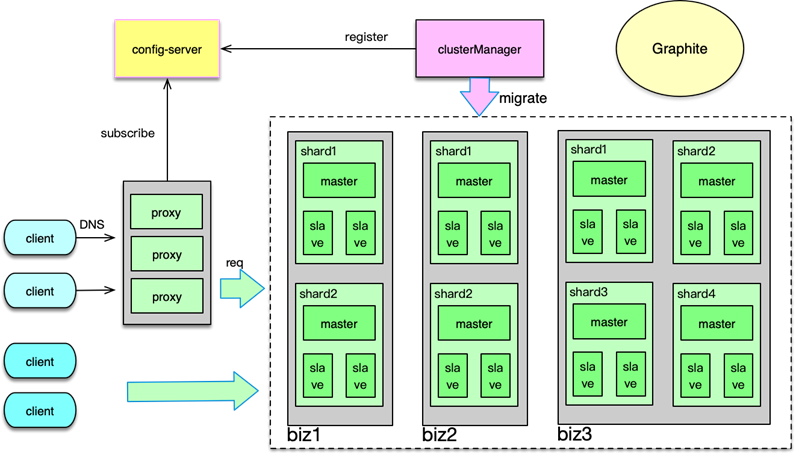
300分钟吃透分布式缓存(拉钩教育总结)
开篇寄语 开篇寄语:缓存,你真的用对了吗? 你好,我是你的缓存老师陈波,可能大家对我的网名 fishermen 会更熟悉。 我是资深老码农一枚,经历了新浪微博从起步到当前月活数亿用户的大型互联网系统的技术演进过程,现任新浪微博技术专家。我于 2008 年加入新浪,最初从事新浪 IM 的后端研发。2009 年之后开始微博 Feed 平台系统的的研发及架构工作,深度参与最初若干个版本几乎所有业务

nxp c语言 编程,悠然乱弹:拉钩网FizzBuzzWhizz试题之悠然版解答
试题 乱弹 据说是直接用来面试的,呵呵,很明显,写得少不是目标,写得快也不是目标,怎么样优雅的解决此问题还是重点。 如果用一个方法解决了此问题的同学,我可以负责任的说,基本上没有啥戏了。 悠然的方法不是最快的,悠然的方法也不是最小的,因此从这两个方面与悠然比较的,悠然承认落败了。 悠然主要从扩展性及代码的优雅性方面来做一下解答,也顺便普及一下设计方面的一些心得体会,与大家分享。 思路 此题明显是
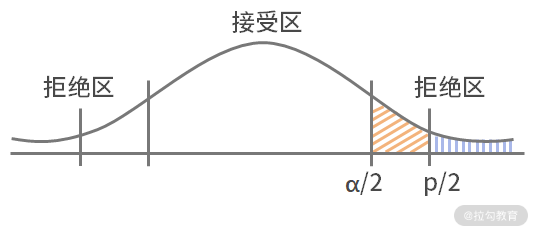
拉钩教育的数据分析课程归纳小结:数据分析中的概率统计初步
统计学基础当中描述性统计的基本概念: 首先,什么叫作推理性统计呢? 简而言之,推理性统计是通过样本数据去推理总体数据特性的方法。它跟描述统计不一样,描述统计是用整体的数据来描述整体特征,而推理统计是用部分数据来推理整体特征。我们经常说的假设检验、采样与过采样、回归预测模型、贝叶斯模型都是推理性统计。 下面我们分别介绍一下推理性统计当中的概率分布与假设检验的内容,这两个概念在数据分析中
flink-拉钩教育-颗粒归仓-待续
大数据实时计算领域 流式及批量分析应用:数据实时采集、计算和下游发送 实时数据仓库和ETL(extract transform load) 核心概念 streams:有界流(固定大小的数据),无界流(随时间增加而增长) state:进行流式计算过程中的信息 time:event time、ingestion time、processing time,判断业务状态是否滞后、

拉钩网 数据分析与可视化
前端时间爬取了拉钩网的某一职位的相关信息,于是就有了分析一下这些数据的想法,爬取的方式可以看我的另一篇博客, 我的数据一被处理成了csv格式的数据,存储在云盘(https://pan.baidu.com/s/1-Iq9fcpJctvL4oe4JZ2HWg)有需要的可自行下载,代码也在里面了, csv文件的数据主要是以下的这些 在csv中存储的格式为 第一列为职位名称,第二,三列为薪

拉钩招聘数据机器学习建模(GBDT,XGBoost,LightGBM)⑤
boosting族算法:将一组弱学习器提升为强学习器的框架算法 以下boosting的分类: Adaboost GBDT XGBoost lightGBM … 了解机器学习建模详情请戳 https://blog.csdn.net/weixin_43746433/article/details/94624103 1.GBDT GBDT 是常用的机器学习算法之一,因其出色的特征自动组合能力和高效

错别字在线检查软件, 拉钩招聘网站出现错别字了
拉钩招聘网站出现错别字了 使用 JcJc 错别字在线检查工具 http://www.godecms.com 拉钩招聘网站出现错别字了 http://godecms.com/cuobiezi/daquan/index http://godecms.com/