批流专题

Flink1.12集成Hive打造自己的批流一体数仓
简介 小编在去年之前分享过参与的实时数据平台的建设,关于实时数仓也进行过分享。客观的说,我们当时做不到批流一体,小编当时的方案是将实时消息数据每隔15分钟文件同步到离线数据平台,然后用同一套SQL代码进行离线入库操作。 但是随着 Flink1.12版本的发布,Flink使用HiveCatalog可以通过批或者流的方式来处理Hive中的表。这就意味着Flink既可以作为Hive的一个批处

使用 Paimon + StarRocks 极速批流一体湖仓分析
摘要:本文整理自阿里云智能高级开发工程师王日宇,在 Flink Forward Asia 2023 流式湖仓(二)专场的分享。本篇内容主要分为以下四部分: StarRocks+Paimon 湖仓分析的发展历程使用 StarRocks+Paimon 进行湖仓分析主要场景和技术原理StarRocks+Paimon 湖仓分析能力的性能测试StarRocks+Paimon 湖仓分析能力的未来规划
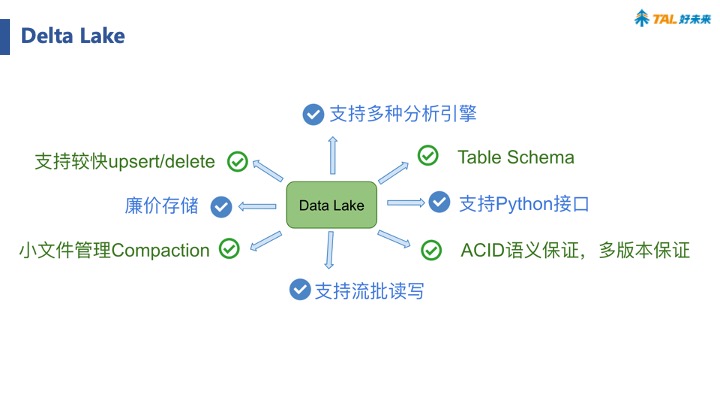
DataLake — 批流一体化的追风者(2) -- Delta Lake核心原理解析
一、Delta Lake 1.Delta Lake基础概述 接上文,我们全面地讲解了Data Lake相关的概念、对比区别以及实际发展历程等。那么这篇首章开篇我们来讲历史最为悠久的Delta Lake。它的定位是流批一体的存储中间层,支持 update/delete/merge。由于出自Databricks,spark的所有数据写入方式,包括基于dataframe的批、流,以及

Flink是如何支持批流一体的
实现批处理的技术许许多多,从各种关系型数据库的sql处理,到大数据领域的MapReduce,Hive,Spark等等。这些都是处理有限数据流的经典方式。而Flink专注的是无限流处理,那么他是怎么做到批处理的呢? 无限流处理:输入数据没有尽头;数据处理从当前或者过去的某一个时间 点开始,持续不停地进行 另一种处理形式叫作有限流处理,即从某一个时间点开始处理数据,然后在另一个时间点结束。输入数

构建批流一体数据集成平台的一致性语义保证
转自:未知的瞬间 陈肃致力于企业级数据集成平台的研发。曾就职于中国移动研究院(用户行为实验室负责人)、亿瑞互动科技有限公司(技术VP)。对消息中间件、推荐系统等领域都有丰富的实践经验。拥有十项发明专利。 批量和流式是数据集成的两种任务形态。在实际应用中,批量和流式往往需要结合使用:前者处理历史数据,后者处理增量数据。数据同步的一致性语义保证是构建批流一体数据集成平台的基本要求。无论是批流切换,