房屋信息专题
Scrapy58同城租房房屋信息(完整)
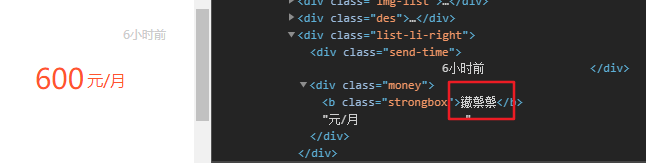
Scrapy 创建Scrapy项目 scrapy startproject mySpider 生成一个爬虫 scrapy genspider 爬虫名字 "允许爬取网址范围" 运行爬虫 scrapy crawl 爬虫名字 Xpath语法提取元素 小编相信你们都会的,在此就放上一个官方文档,有需要便可查看 Xpath教程 58同城字体加密 破解字体加密,一
使用lxml爬取房屋信息(静态网页,无反爬)
先上代码 后面有解释 import requestsfrom lxml import etreeimport csvimport timeheader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:104.0) Gecko/20100101 Firefox/104.0"}def download(url)