司南专题
CompassArena 司南大模型测评--代码编写
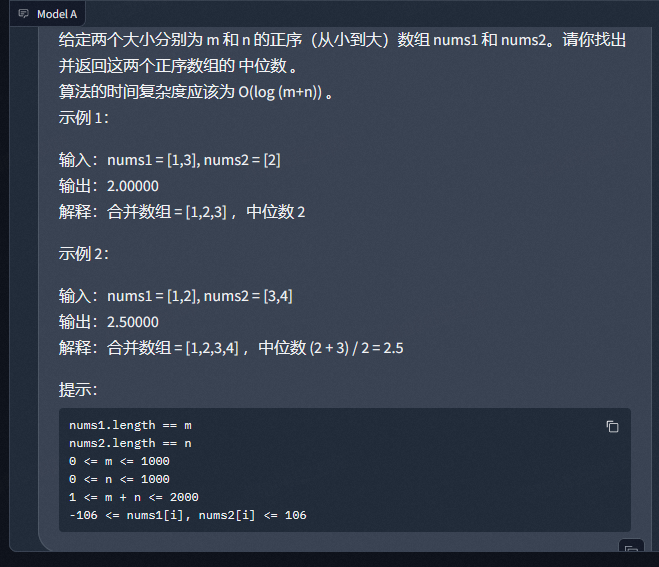
测试角度 要说测试模型,对咱们程序员来说,那自然是写代码的能力强不强比较重要了。那么下面我们以 leetcode 中的一道表面上是困难题的题目来考考各家大模型,看看哪个才应该是咱们日常写程序的帮手。 部分模型回答 问题部分如下截图,后边就不再重复粘贴了,主要来看回答。我们注意到这里的难点在于在于对时间复杂度有要求,看看各个模型能不能注意到这一点。 出于篇幅,这里只贴出来结果比较好的几个模型进

第七节课《OpenCompass司南--大模型评测实战》
OpenCompass 大模型评测实战_哔哩哔哩_bilibili https://github.com/InternLM/Tutorial/blob/camp2/opencompass/readme.md InternStudio 一、通过评测促进模型发展 面向未来拓展能力维度:评测体系需增加新能力维度(数学、复杂推理、逻辑推理、代码和智能体等),以全面评估模型性能。扎根通用能力聚焦垂直

OpenCompass 2.0 司南大模型评测榜单介绍
OpenCompass 2.0,也称为“司南”,是由上海人工智能实验室发布的一个大模型评测体系。这个评测体系旨在为大语言模型和多模态模型等提供一站式的评测服务,全面量化这些模型在知识、语言、理解、推理和考试等五大能力维度的表现。据2023年的评测结果显示,GPT-4 Turbo 在这些评测中获得了最佳表现,紧随其后的是国内的一些模型,例如智谱清言GLM-4、阿里巴巴Qwen-Max