取斗图专题
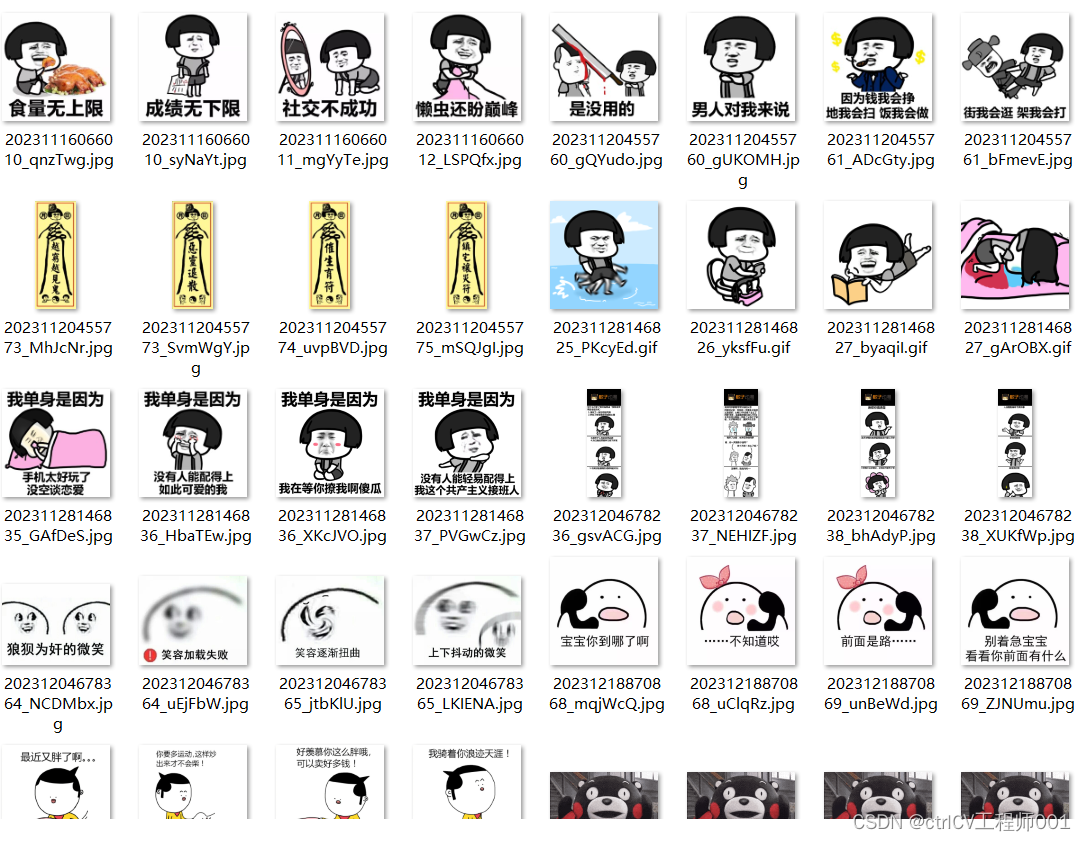
爬取斗图网页前五页的图片
单线程爬取 import requestsfrom lxml import etreeimport osimport timedef tupi_url():for tape in range(1, 4):url = f'https://www.pkdoutu.com/article/list/?page={tape}'headers = {'User-Agent': 'Mozilla/

python爬取斗图啦表情包
自从会了python,斗图我怕过谁 不多说上代码 # -*- coding: utf-8 -*-# @Time : 2020/4/11 21:40# @Author : zhao~xiujie# @email : zxj0314@outlook.com# @FileName: doutu.py.py# @IDE: PyCharmimport requestsfrom lxml i

Python实战---使用多线程爬取斗图啦表情包
使用多线程爬取斗图啦表情包 目标 爬取前一百页的表情包。 话不多说,直接上爬取结果: 只是作为练习,所以中途就把程序关掉了,可以看出来多线程爬取是真的快。 思路 1、先写出不使用多线程爬取页面的代码 2、使用多线程的生产者和消费者模式来爬取。 实现代码 '''@Description: 爬取斗图啦的表情包@Author: sikaozhifu@Date: 2020-06-11
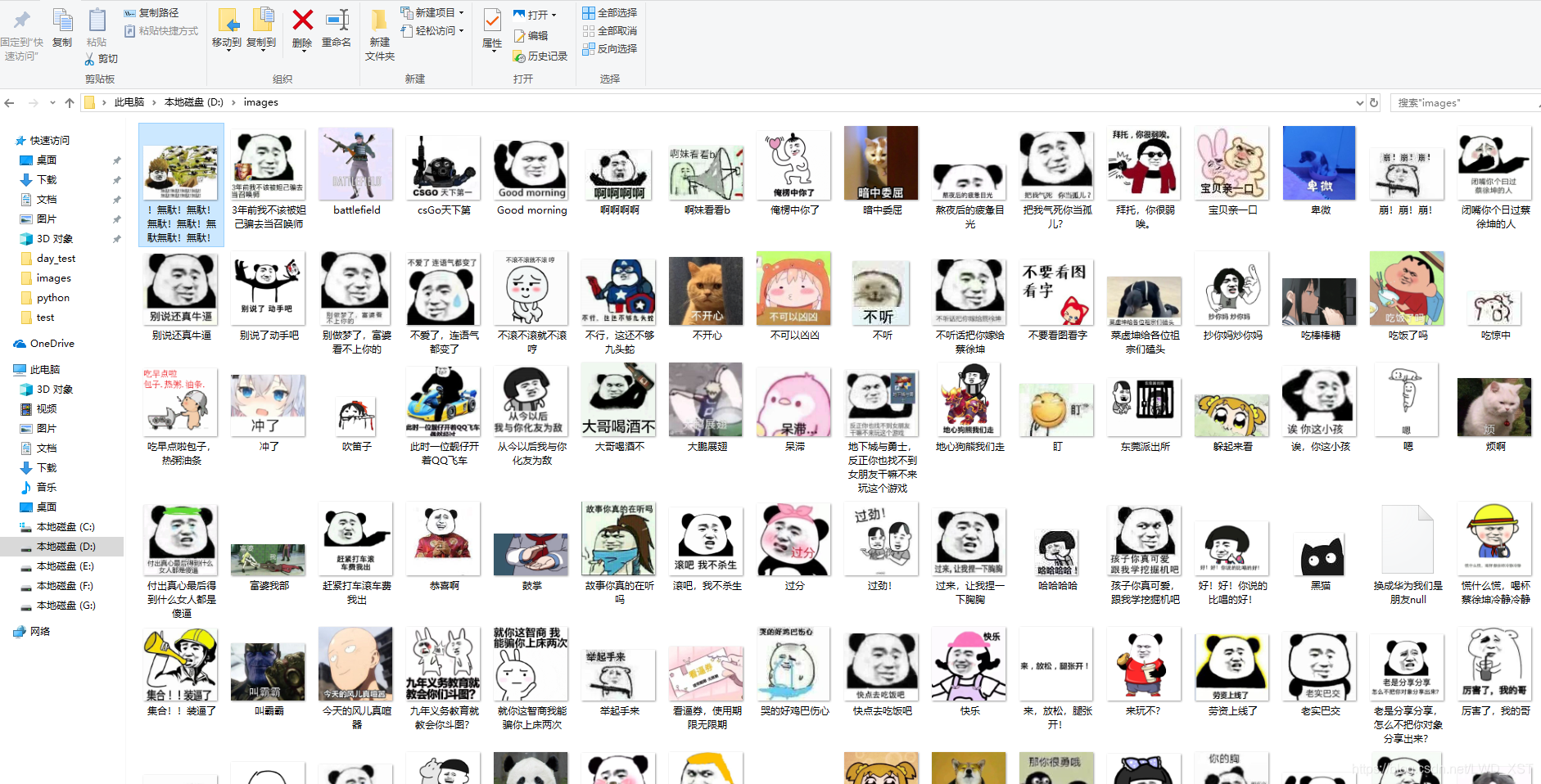
python3 爬取斗图啦网站的表情包图片
爬取斗图啦网的表情包 前一阵子在网易云课堂学习了一些关于爬虫的教程,现在来实践一下,当做练习。本人小白,初学编程,如有错误,望不吝告之,多谢。 本人使用的是python3.6版本,引用里的注释是为了记忆相关爬虫模块的知识,请忽略, 相关代码如下: from urllib import requestimport requestsfrom bs4 import BeautifulSo
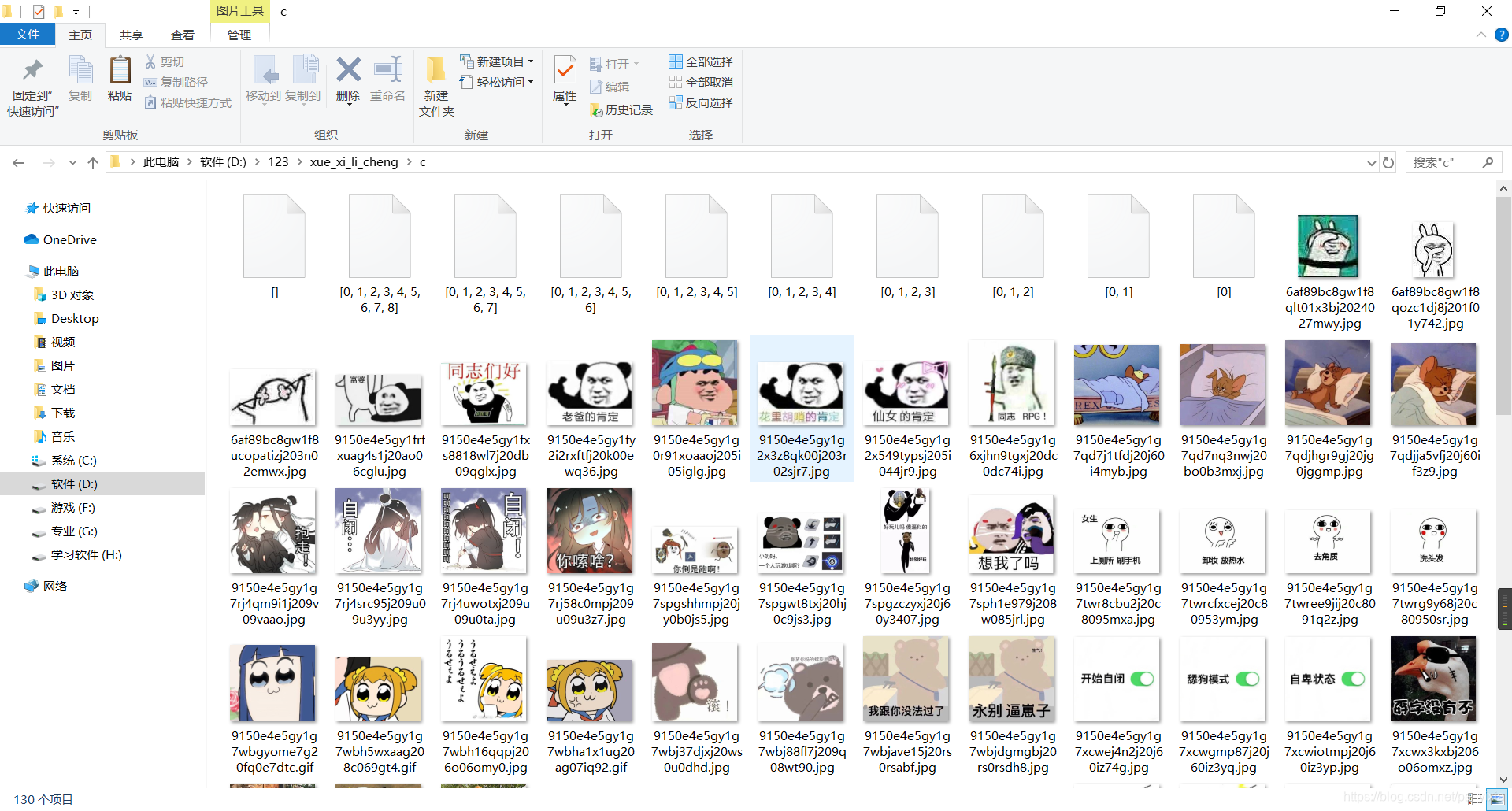
爬虫实战(一)零基础应该也能看懂 爬取斗图啦上的图片爬取
爬虫(模仿博客上的内容:换一个网站进行操作) 爬取网站上的图片 1.搞清思路 想要下载图片就要搞清图片的代码在哪里 想要批量下载就要搞清这些图片的代码规律 下面图片里有我的思路 下面是我写的代码 和解释 =前面的是自己命名的,不知道他会出来什么的时候可以print()打印一下名字 看结果是什么 这是效果图 我写的时间 2019/11/03 复制下 改一下保存那个位置应该可以用 2 在这里插