本文主要是介绍python3 爬取斗图啦网站的表情包图片,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
爬取斗图啦网的表情包
前一阵子在网易云课堂学习了一些关于爬虫的教程,现在来实践一下,当做练习。本人小白,初学编程,如有错误,望不吝告之,多谢。
本人使用的是python3.6版本,引用里的注释是为了记忆相关爬虫模块的知识,请忽略,
相关代码如下:
from urllib import request
import requests
from bs4 import BeautifulSoup
import os
from urllib.error import URLError
# from urllib.request import ProxyHandler, build_openerheaders = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}def get_imgurl_list(url):req = requests.get(url=url, headers=headers)response = req.textsoup = BeautifulSoup(response, 'lxml')# 找出带有相关class的img标签imgurl_list = soup.find_all('img', attrs={'class':'img-responsive lazy image_dta'})return imgurl_listdef save_imgs(list):for img in list:try:# 获取图片的源地址photo_url = img['data-original']# 给图片命名为 .jpg 或 .giffilename = img['alt'] + photo_url[-4:]# 将图片保存到指定目录path = os.path.join('D:/images', filename)# 开始用request.urlretrieve(photo_url, path)时出现403错误,可能是有反爬虫机制,后改为加上请求头的Requestresp = request.Request(photo_url, headers=headers)data = request.urlopen(resp).read()with open(path, 'wb') as f:f.write(data)except URLError as e:print(e)def main():# 此地址是到‘斗图啦’里的‘最新表情’里得到base_url = 'http://www.doutula.com/photo/list/?page='# 我只爬取了前四页,数字4可以更改for x in range(1, 4):url = base_url + str(x)save_imgs(get_imgurl_list(url))if __name__ == '__main__':main()
如果要爬取大量图片可以改用多线程爬取,相对效率能高一些:
from urllib import request
import requests
from bs4 import BeautifulSoup
import os
# from urllib.request import ProxyHandler, build_opener
from urllib.error import URLError
import threadingBASE_URL = 'http://www.doutula.com/photo/list/?page='
PAGE_URL_LIST = []
FACE_URL_LIST = []for x in range(1, 5):url = BASE_URL + str(x)PAGE_URL_LIST.append(url)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
gLock = threading.Lock()def get_imgurl_list():while True:gLock.acquire()if len(PAGE_URL_LIST) == 0:gLock.release()breakelse:page_url = PAGE_URL_LIST.pop()gLock.release()req = requests.get(url=page_url, headers=headers)response = req.textsoup = BeautifulSoup(response, 'lxml')# 找出带有相关class的img标签,这里返回数据需要通过迭代或listimgurl_list = soup.find_all('img', attrs={'class':'img-responsive lazy image_dta'})gLock.acquire()for img in imgurl_list:url = img['data-original']FACE_URL_LIST.append(url)gLock.release()def save_imgs():while True:gLock.acquire()if len(FACE_URL_LIST) == 0:gLock.release()continueelse:face_url = FACE_URL_LIST.pop()gLock.release()try:# 这里没有上面代码的命名方法好filename = face_url[-14:]# 将图片保存到指定目录path = os.path.join('D:/images', filename)# 由于斗图啦网有反爬虫,所以需要加上请求头resp = request.Request(face_url, headers=headers)data = request.urlopen(resp).read()with open(path, 'wb') as f:f.write(data)except URLError as e:print(e)def main():# 创建3个线程来获取图片地址for i in range(3):t = threading.Thread(target=get_imgurl_list)t.start()# 创建4个线程来下载图片for i in range(4):t = threading.Thread(target=save_imgs)t.start()if __name__ == '__main__':main()
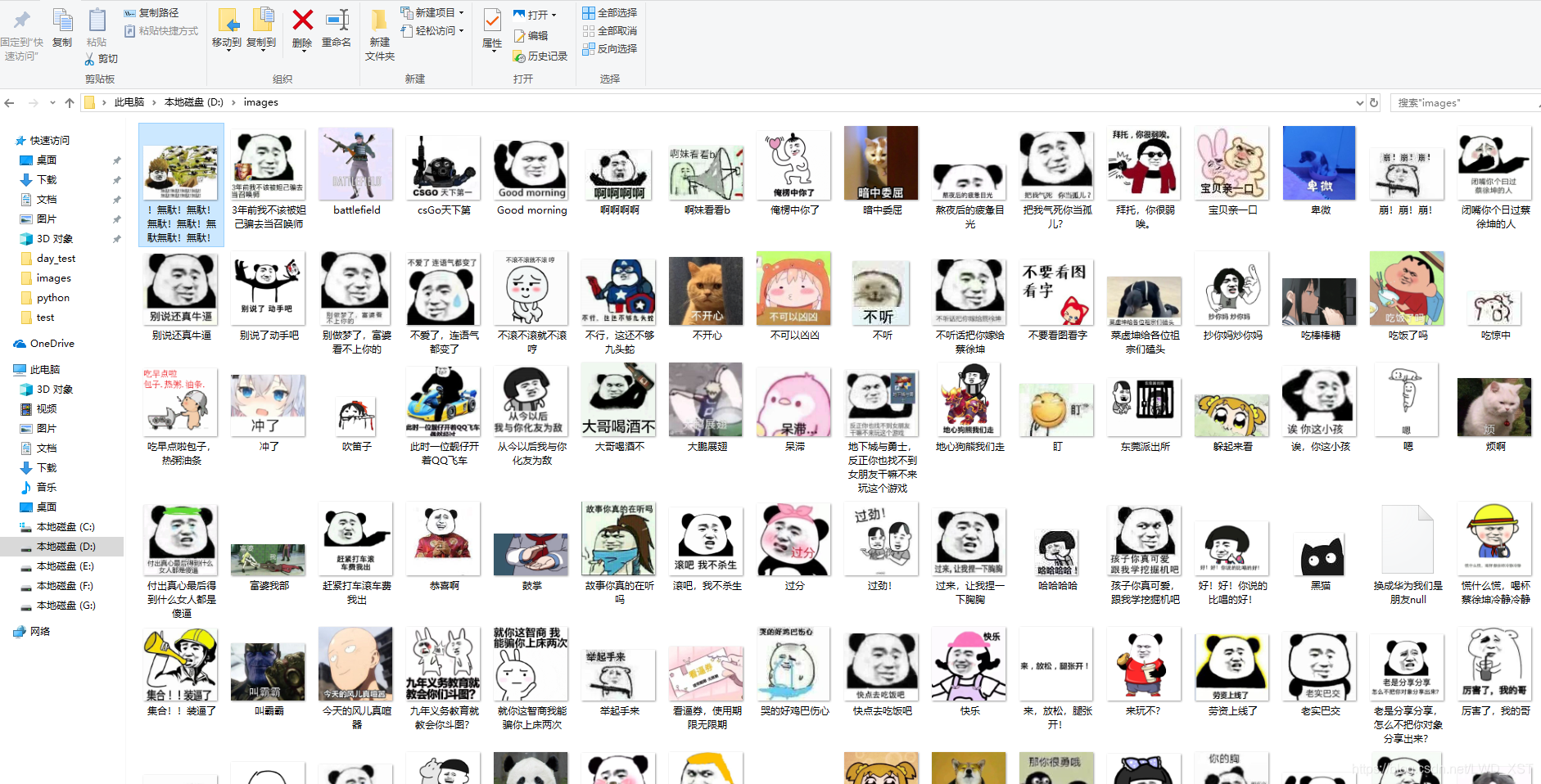
运行第一个程序后,获得图片 如下, 在使用多线程爬取时,爬取一定图片后,出现了很长的等待时间,我给中断了,可能爬取过快网站采取了相关的反爬虫机制。
这篇关于python3 爬取斗图啦网站的表情包图片的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








