化层专题

Node.js 数据库操作详解:构建高效的数据持久化层
Node.js 数据库操作详解:构建高效的数据持久化层 目录 🔍 MongoDB 📌 使用 mongoose 连接 MongoDB📌 定义模型和数据验证📌 实现 CRUD 操作 🛠️ MySQL 📌 使用 mysql 或 mysql2 模块连接 MySQL📌 执行 SQL 查询📌 处理结果和错误 📊 SQLite 📌 使用 sqlite3 模块连接 SQLite📌 执行
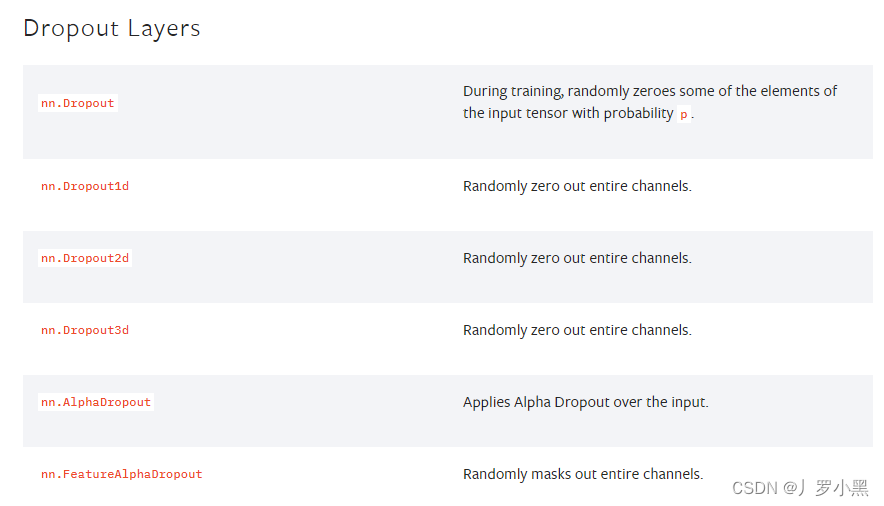
Pytorch学习 day08(最大池化层、非线性激活层、正则化层、循环层、Transformer层、线性层、Dropout层)
最大池化层 最大池化,也叫上采样,是池化核在输入图像上不断移动,并取对应区域中的最大值,目的是:在保留输入特征的同时,减小输入数据量,加快训练。参数设置如下: kernel_size:池化核的高宽(整数或元组),整数时表示高宽都为该整数,元组时表示分别在水平和垂直方向上的长度。stride:池化核每次移动的步长(整数或元组),整数时表示在水平和垂直方向上使用相同的步长。元组时分别表示在水平和垂直

EJB3.0中 持久化层的开发
EJB3.0中的持久化是有JPA管理的 包括三个部分 1。实体 @Entity @Table(name="users") public class User implements Serializable{ @Id@GeneratedValue(strategy=GenerationType.AUTO) private int id; @Column(nulla
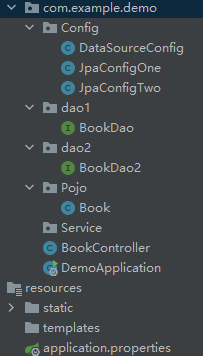
SpringBoot:整合持久化层
1,单数据源 1.1,整合Jdbc JdbcTemplate是Spring提供的一套JDBC模板框架,利用AOP技术来解决使用JDBC时大量重复代码的问题。JdbcTemplate虽然没有MyBatis那么灵活,但是比直接使用JDBC要方便很多。Spring Boot中对JdbcTemplate的使用提供了自动化配置类JdbcTemplateAutoConfiguration。 1.1

Sqlite3+RabbitMQ+Celery Python从零开始搭建一个持久化层的生产者消费者服务模型
1. 一张图说明我们接下来要造什么: 本次实验所使用到的玩具: 【1】RabbitMQ:消息队列中间件,做broker角色 【2】Celery:异步调度中间件,做workers的调度者(包工头) 【3】Sqlite:异步计算结果存储的角色 我们的 workers 可以理解为多进程/多线程,然后通过Celery来进行智能化的调度,至于他怎么调度的我们暂时不关心,然后我们使用RabbitM