化及专题

JVM上篇:内存与垃圾回收篇-08-对象实例化及直接内存
笔记来源:尚硅谷 JVM 全套教程,百万播放,全网巅峰(宋红康详解 java 虚拟机) 文章目录 8. 对象实例化及直接内存8.1. 对象实例化8.1.1. 创建对象的方式8.1.2. 创建对象的步骤1. 判断对象对应的类是否加载、链接、初始化2. 为对象分配内存3. 处理并发问题4. 初始化分配到的内存5. 设置对象的对象头6. 执行 init 方法进行初始化 8.2. 对象内存

从零开始学数据结构系列之第三章《中序线索二叉树线索化及总代码》
文章目录 中序线索化总代码往期回顾 中序线索化 void inThreadTree(TreeNode* T, TreeNode** pre) {if(T){inThreadTree(T->lchild,pre);if(T->lchild == NULL){T->ltag = 1;T->lchild = *pre;}if(*pre != NULL && (*pre)->
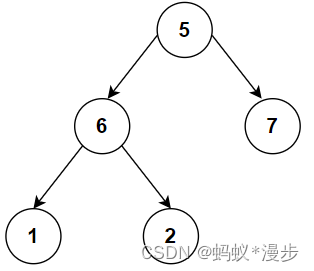
Python 二叉数的实例化及遍历
首先创建一个这样的二叉树,作为我们今天的实例。实例代码在下方。 #创建1个树类型class TreeNode:def __init__(self,val,left=None,right=None):self.val=valself.left=leftself.right=right#实例化类node1=TreeNode(5)node2=TreeNode(6)node3=Tree

Redis持久化及过期删除策略
一、Redis 持久化之RDB和AOF 1.1 RDB 详解 RDB 是 Redis 默认的持久化方案。在指定的时间间隔内,执行指定次数的写操作,则会将内存中的数据写入到磁盘中。即在指定目录下生成一个dump.rdb文件。Redis 重启会通过加载dump.rdb文件恢复数据。 从配置文件了解RDB 打开 redis.conf 文件,找到 SNAPSHOTTING 对应内容 RDB核心规

机器学习(深度学习)缓解过拟合的方法——正则化及L1L2范数详解
机器学习(深度学习)缓解过拟合的方法——正则化 L1范数和L2范数L1范数L2范数 过拟合的本质:模型对于噪声过于敏感,把训练样本里的噪声当做特征进行学习,以至于在测试集的表现不好,加入正则化后,当输入有轻微的改动,结果受到的影响较小。 正则化的方法主要有以下几种: 参数范数惩罚,比较好理解,将范数加入目标函数(损失函数),常见的有一范数,二范数数据集增强添加噪声ear

第二门课:改善深层神经网络<超参数调试、正则化及优化>-超参数调试、Batch正则化和程序框架
文章目录 1 调试处理2 为超参数选择合适的范围3 超参数调试的实践4 归一化网络的激活函数5 将Batch Norm拟合进神经网络6 Batch Norm为什么会奏效?7 测试时的Batch Norm8 SoftMax回归9 训练一个SoftMax分类器10 深度学习框架11 TensorFlow 1 调试处理 需要调试的参数:α是最重要的。 可以采用随机取值,然后选择哪
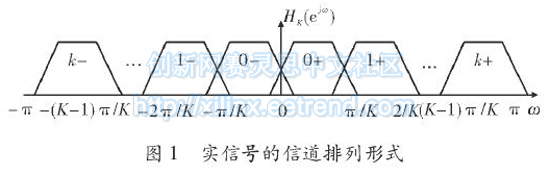
matlab仿真求算采样频率,基于多相滤波结构的信道化及FPGA实现
摘要:随着现代电子战中电磁环境的日益复杂,军用接收机需具备同时处理多个信道信号的能力,即具备全概率截获能力。信道化接收机可将一个复杂信号分成多个信道,从而方便后续处理。文中利用一种简化的结构验证了该种信道化方案的可行性,并节省了逻辑资源。 在电子战中,传统上主要采用扫频式搜索接收机,但其截获概率受搜索速度的影响较为严重,且因其受到搜索速度与分辨率之间关系的制约,所以扫频式接收机对跳频信号的截获效

第二门课:改善深层神经网络<超参数调试、正则化及优化>-深度学习的实用层面
文章目录 1 训练集、验证集以及测试集2 偏差与方差3 机器学习基础4 正则化5 为什么正则化可以减少过拟合?6 Dropout<随机失活>正则化7 理解Dropout8 其他正则化方法9 归一化输入10 梯度消失和梯度爆炸11 神经网络的权重初始化12 梯度的数值逼近13 梯度检验14 关于梯度检验的注记 1 训练集、验证集以及测试集 验证集与测试集要确保来自同一个分布 因为验

数据结构(十七) -- C语言版 -- 树 - 二叉树的线索化及遍历 -- 先序线索化、中序线索化、后序线索化
内容预览 零、读前说明一、线索化概述二、中序线索化及其遍历2.1、线索化过程说明2.2、遍历过程说明2.3、线索化及遍历的代码实现2.4、线索化的测试2.4.1、测试案例工程结构2.4.2、测试案例代码2.4.3、测试效果图 三、先序线索化及其遍历3.1、线索化过程说明3.2、遍历过程说明3.3、线索化及遍历的代码实现3.4、线索化的测试 四、后序线索化及其遍历4.1、线索化过程说明4.2
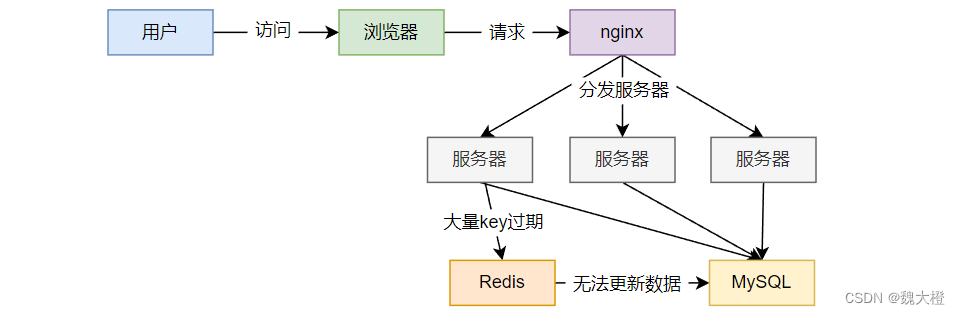
第六章 数据持久化及高频面试题
1、数据持久化 官网文档地址:https://redis.io/docs/management/persistence/ Redis提供了主要提供了 2 种不同形式的持久化方式: RDB(Redis数据库):RDB 持久性以指定的时间间隔执行数据集的时间点快照。 AOF(Append Only File):AOF 持久化记录服务器接收到的每个写操作,在服务器启动时再次播放,重建原始数据集
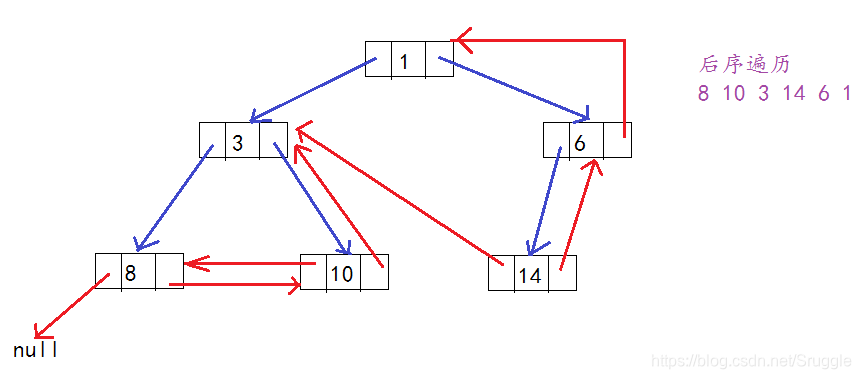
二叉树的线索化及遍历
目录 一、需求 二、前序线索化 2.1 前序线索化图解 2.2 前序线索化代码实现 2.3 前序线索化的遍历 三、中序线索化 3.1 中序线索化图解 3.2 中序线索化代码实现 3.3 中序线索化的遍历 四、后序线索化 4.1 后序线索化图解 4.2 后序线索化代码实现 五、完整代码 一、需求 /** 需求:实现线索化二叉树* 分析:* A
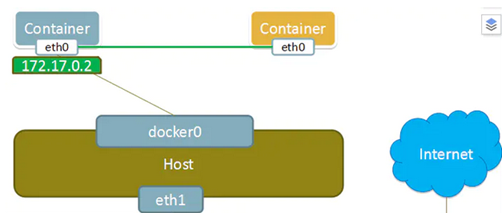
【Docker】容器数据持久化及容器互联
一、Docker容器的数据管理 1.1、什么是数据卷 数据卷是经过特殊设计的目录,可以绕过联合文件系统(UFS),为一个或者多个容器提供访问,数据卷设计的目的,在于数据的永久存储,它完全独立于容器的生存周期。因此,docker不会在容器删除时删除其挂载的数据卷,也不会存在类似的垃圾收集机制,对容器引用的数据卷进行处理,同一个数据卷可以只支持多个容器的访问。 1.2、数据卷特点 数据卷在容器

Redis—高可用、持久化及性能管理
文章目录 Redis1.redis是一种非关数据库(内存、缓存)2.redis集群模式 一、Redis高可用1.1Redis高可用概述1.2Redis高可用的技术 二、Redis持久化2.1持久化的功能2.2redis提供的两种持久化方法 三、RDB持久化3.1RDB持久化概述3.2触发条件3.2.1手动触发3.2.2自动触发 3.3执行流程3.4启动时加载 四、AOF持久化4.1AOF

【Unity】数据持久化及方法
文章目录 一、Unity常见路径以及文件夹1.1 常见路径Android平台IOS平台 1.2 文件夹ResourcesStreamingAssetsAssetBundlePersistentDataPath 二、PlayerPrefs三、二进制序列化三、JSON3.1 JSON介绍 四、XML 一、Unity常见路径以及文件夹 1.1 常见路径 Unity中包含很多特
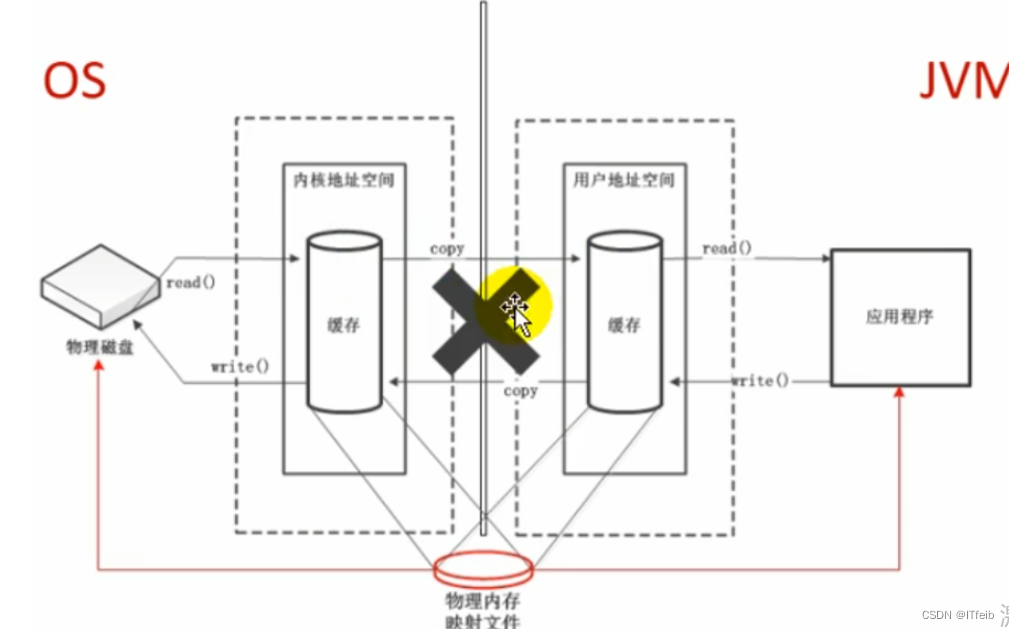
jvm--对象实例化及直接内存
文章目录 1. 创建对象2. 对象内存布局3. 对象的访问定位4. 直接内存(Direct Memory) 1. 创建对象 创建对象的方式: new最常见的方式、Xxx 的静态方法(单例模式),XxxBuilder/XxxFactory 的静态方法Class 的 newInstance 方法(已经过时):反射的方式,只能调用空参的构造器,权限必须是 publicConstru
jvm--对象实例化及直接内存
文章目录 1. 创建对象2. 对象内存布局3. 对象的访问定位4. 直接内存(Direct Memory) 1. 创建对象 创建对象的方式: new最常见的方式、Xxx 的静态方法(单例模式),XxxBuilder/XxxFactory 的静态方法Class 的 newInstance 方法(已经过时):反射的方式,只能调用空参的构造器,权限必须是 publicConstru