分层抽样专题
R语言两种方法实现随机分层抽样
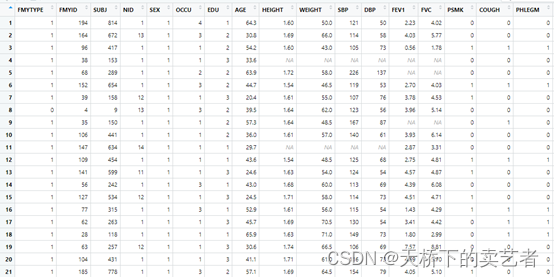
为了减少数据分布的不平衡,提供高样本的代表性,可将数据按特征分层一定的层次,在每个层次抽取一定量的样本,为分层抽样。分层抽样的特点是将科学分组法与抽样法结合在一起,分组减小了各抽样层变异性的影响,抽样保证了所抽取的样本具有足够的代表性。 既往咱们已经多篇文章介绍了R语言的随机抽样,今天咱们通过R语言的2种方法来介绍随机分层抽样。咱们先导入数据和R包,首先介绍的是sampling包, libr
【抽样调查】分层抽样上
碎碎念:在大一大二时听课有的时候会发现听不太懂,那时候只觉得是我自己的基础不好的原因,但现在我发现“听不懂”是能够针对性解决的。比如抽样调查这门课,分析过后我发现我听不懂的原因之一是“没有框架”,一大堆知识扑面而来但我没有建立起自己的逻辑框架,那些零零碎碎的知识看起来毫无章法,才导致我听不懂。那今天的分层抽样就按照讲故事的顺序展开吧~ 第一次更新:2024/5/8 目录 一. 分层抽样

方差缩减——分层抽样
方差缩减——分层抽样 分成4个子区间 import numpy as npn = 500estimates = np.empty([100, 2])def g(x):if x >= 0 and x <= 1:y = np.exp(-x) / (1 + x ** 2)else:y = 0return ydef get_mean(X):results = []for x in X:results
机器学习 | 使用Scikit-Learn实现分层抽样
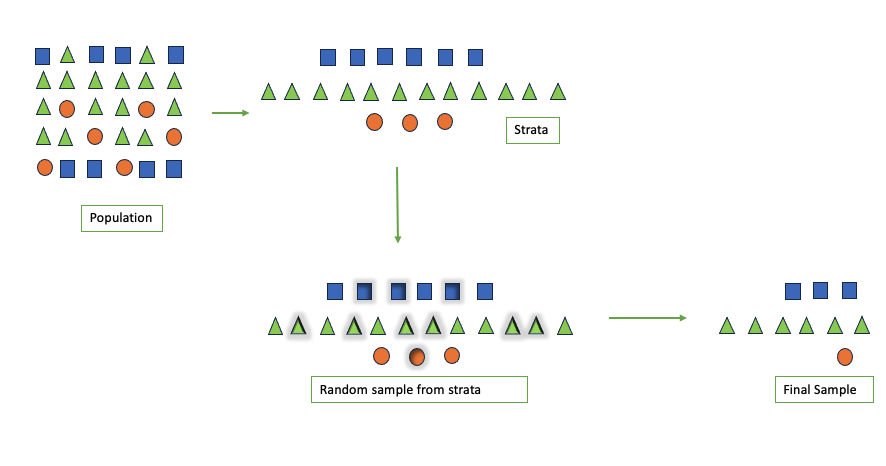
在本文中,我们将学习如何使用Scikit-Learn实现分层抽样。 什么是分层抽样? 分层抽样是一种抽样方法,首先将总体的单位按某种特征分为若干次级总体(层),然后再从每一层内进行单纯随机抽样,组成一个样本。可以提高总体指标估计值的精确度。在抽样时,将总体分成互不交叉的层,然后按一定的比例,从各层次独立地抽取一定数量的个体,将各层次取出的个体合在一起作为样本,这种抽样方法是一种分层抽样。 分
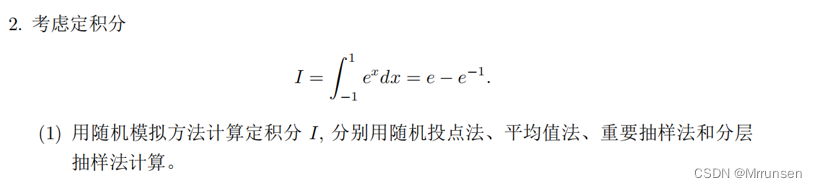
R 语言 随机模拟法计算定积分 -随机投点法- -平均值法- -重要抽样法-分层抽样法-
#-------------积分真值------------------I.true<-exp(1
抽样偏差(Sampling Bias)与 分层抽样(Stratified Sampling)
个人觉得, 把分层抽样称为“分类采样”会更贴切一些。通常最基本的采样手段是:随机抽样,但是在很多场景下,随机抽样是有问题的。最简单也最有说服力的例子就是身高和体重在性别上的差异,在对它们进行抽样时必须考虑性别因素。我们可以粗略地说:女性的身高符合165为中心的正态分布,体重符合50公斤为中心的正态分布,而男性身高则可能是175为中心的正态分布,体重是60公斤中心的正态分布。还有一些示例未必那么明细