值来专题

NLP-文本匹配-2013:DSSM【首次提出将深度学习应用到文本匹配,每个文本对象均由5层的神经网络进行向量化表示,最后通过向量间的余弦值来衡量文本对象的相似度】【釆用词袋模型,丢失单词顺序关系】
深度语义结构模型(DSSM)首次提出了将深度学习应用到文本匹配方法中,该模型通过建模用户查询和文档的匹配度,同传统文本匹配模型相比获得了显著的提升。在深度语义结构模型中,每个文本对象均由5层的神经网络进行向量化表示,最后通过向量间的余弦值来衡量文本对象的相似度 DSSM模型由宁完全采用全连接神经网络构建,以至于参数较多,不利于模型参数的学习与优化,并且DSSM模型在获取词(片段)嵌入时釆用了词袋
通过改变boost值来改变文档的得分源码
在进行相关度排序的时候,如果想加某个文档的相关度,使其在搜索解雇中排名更加靠前的位置上,则使用boost。 代码: package change; import java.io.IOException; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.do
三运放仪表放大器通过设置单个电阻器的值来调整增益
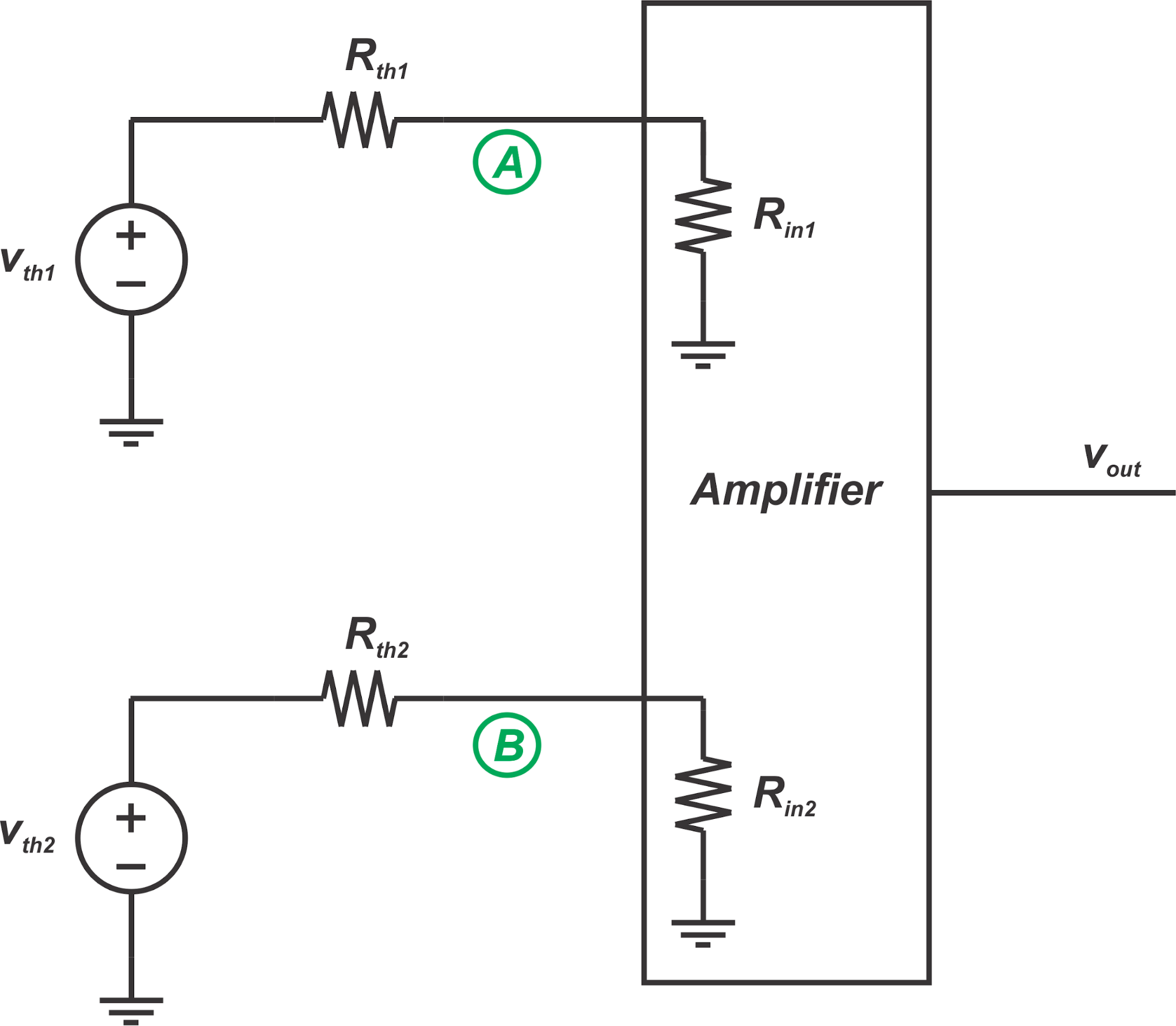
从公式 1 中可以看出,我们可以通过调整单个电阻器 R G的值来调整仪表放大器的差分增益。这很重要,因为与电路中的其他电阻器不同, RG的值不需要与任何其他电阻器匹配。 例如,如果我们尝试通过更改 R 5的值来设置增益,我们还需要相应地更改 R 6。实现匹配的可调电阻比调整单个电阻更具挑战性。 源电阻未出现在增益方程中 考虑下面图 2 所示的电桥测量系统。 图 2. 应用戴维南定

switch case结合枚举值使用,借助枚举的值来做case分支判断
场景描述 在写业务的时候,遇到这么个场景,有一个字段,在数据库中以多种不同的代码来区分,具体一点就是一个 类别_id,数据库里它是以 001/002/003/004 几个不同的字段形式去区分的。 在业务中需要将这些信息全部取出来,然后再通过字段区分,在区分时我在想能否借助switch case而不是一直在用的 if else if,放入对应的list中,并以键值对形式返回前端。 那么在这里就