何恺明专题

RCG:何恺明新作,无条件图像生成新SOTA
丰色 发自 凹非寺量子位 | 公众号 QbitAI 大佬何恺明还未正式入职MIT,但和MIT的第一篇合作研究已经出来了: 他和MIT师生一起开发了一个自条件图像生成框架,名叫RCG(代码已开源)。 这个框架结构非常简单但效果拔群,直接在ImageNet-1K数据集上实现了无条件图像生成的新SOTA。 它生成的图像不需要任何人类注释(也就是提示词、类标签什么的),就能做到既保真又具有多样性。

何恺明新作RCG:无自条件图像生成新SOTA!与MIT首次合作!
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 点击进入—>【视觉和Transformer】微信交流群 扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文,强烈推荐! 在CVer微信公众号后台回复:RCG,即可下载论文pdf和代码链接!快学起来! 转载自:量子位 大佬何恺明还未正式入职MIT,
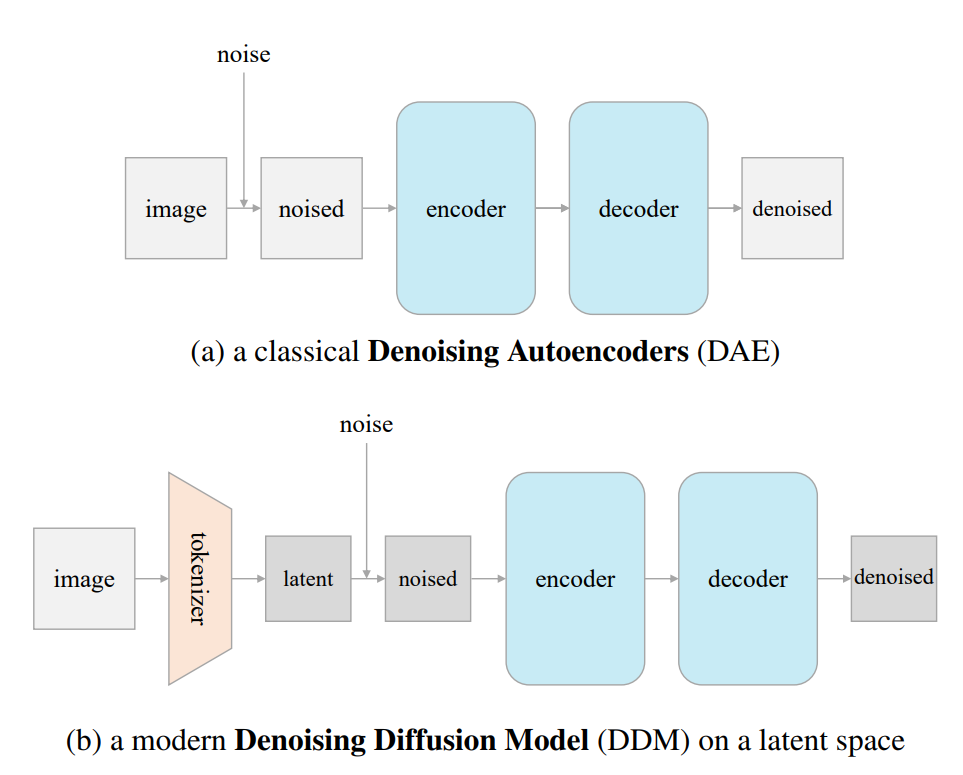
何恺明最新力作:一文解构扩散模型,l-DAE架构或将颠覆AI认知?
CV大神何恺明也进军扩散模型啦!这可是计算机视觉领域的一大新闻。何大神的最新研究成果刚刚发布在arXiv上,立刻就引起了广泛关注。他这次的研究可不是小打小闹,而是对扩散模型进行了深度解构,提出了一个超级简洁的新架构——l-DAE。 工作流程就非常简单:输入是一张有噪声的图片,噪声添加在PCA潜空间里。输出是原始的干净图片。 为了让大家更好地理解扩散模型的工作原理,何恺明还特意拿自己的视觉自监
NeurIPS 2022 | 改进何恺明的MAE!GreenMIM:将Swin与MAE结合,训练速度大大提升!
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 点击进入—> CV 微信技术交流群 杨净 发自 凹非寺转载自:量子位(QbitAI) 自何恺明MAE横空出世以来,MIM(Masked Image Modeling)这一自监督预训练表征越来越引发关注。 但与此同时, 研究人员也不得不思考它的局限性。 MAE论文中只尝试了使用原版ViT架构作为编码器,而表现更好的分层设计结构


何恺明经典去雾算法 还北京一个碧洗蓝天?
一:由简至美的最佳论文(作者:何恺明 视觉计算组) 【视觉机器人:个人感觉学习他的经典算法固然很重要,但是他的解决问题的思路也是非常值得我们学习的】 那是2009年4月24日的早上,我收到了一封不同寻常的email。发信人是CVPR 2009的主席们,他们说我的文章获得了CVPR 2009的最佳论文奖(Best Paper Award)。我反复阅读这封邮件以确认我没有理解错误。这真是一件令人