书山专题
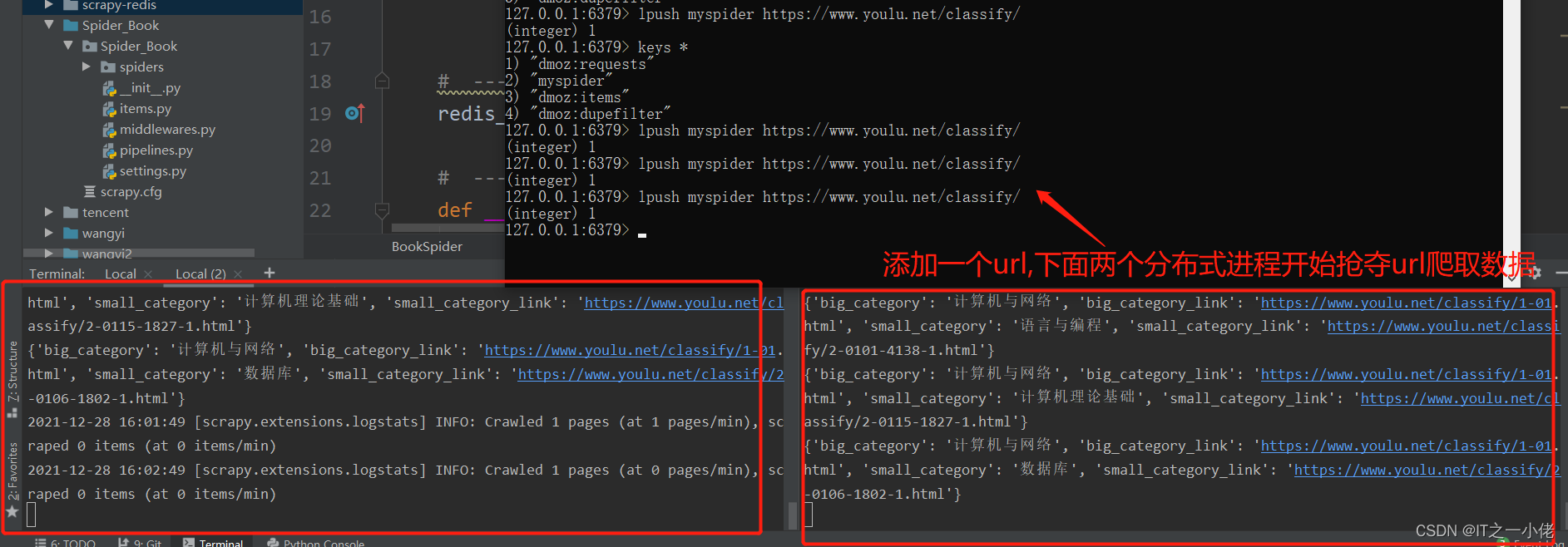
Scrapy_redis框架分布式爬虫的实现案例-书山有路网
普通爬虫: 流程: 创建项目明确目标创建爬虫保存内容 爬取书山有路网上图书页面:图书分类::有路网 - 买旧书 上有路 点击到浏览图书所有分类:图书分类::有路网 - 买旧书 上有路 详情页: 开始创建爬虫项目: 修改items.py文件: # Define here the models for your scraped items## See
书山有路之学习算法导论(二)--排序和顺序统计量
今天是大年初一,祝大家新年快乐啊! 这些天看了《算法导论》的第二部分,这一部分我也写了挺久的,接下来以排序为核心来讨论一下。 书山有路勤为径,加油! 二、排序和顺序统计量 排序问题的结构如下: 输入:一个n个数的序列<a1,a2,...,an> 输出:输入序列的一个排列<a1',a2',...,an'>,满足a1'<=a2'<=...<=an' 讨论具体算法之前再回顾一个概念--原址