之聚类专题


mahout之聚类实现
人们常数"物以类聚,人以群分",聚类就是将一个给定的文档集中相似项目分成不同簇的过程。 聚类设计的过程: (1)一个聚类算法( k-means、模糊k-means、canopy等) (2)相似性和不相似性的概念 a.欧式距离 b.平方欧式距离 c. 曼哈顿距离

python机器学习之聚类算法K-Means——案例:聚类算法用于降维,KMeans的矢量量化应用
聚类算法用于降维,KMeans的矢量量化应用 重要属性: 重要接口: 案例 矢量量化的降维是在同等样本量上压缩信息的大小,即不改变特征的数目也不改变样本的数目,只改变在这些特征下的样本上的信息量。 用K-Means聚类中获得的质心来替代原有的数据,可以把数据上的信息量压缩到非常小,但又不损失太多信息。我们接下来就通过一张图图片的矢量量化来看一看K-Means如何实现压缩数据大小,却不

数学建模之聚类模型详解
聚类模型 引言 “物以类聚,人以群分”,所谓的聚类,就是将样本划分为由类似的对象组成的多个类的过程。聚类后,我们可以更加准确的在每个类中单独使用统计模型进行估计、分析或预测;也可以探究不同类之间的相关性和主要差异。聚类和分类的区别:分类是已知类别的,聚类未知。 K均值聚类算法 算法流程 一、指定需要划分的簇[cù]的个数K值(类的个数); 二、随机地选择K个数据对象作为初始的聚类中心(
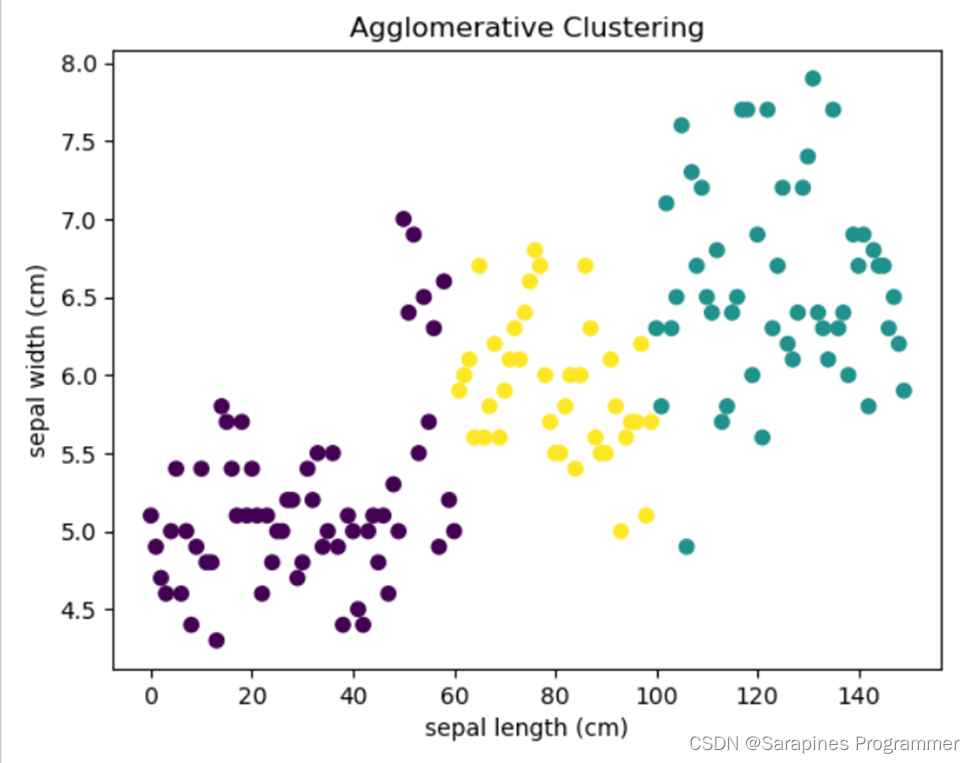
Python | 机器学习之聚类算法
🌈个人主页:Sarapines Programmer🔥 系列专栏:《人工智能奇遇记》🔖少年有梦不应止于心动,更要付诸行动。 目录结构 1. 机器学习之聚类算法概念 1.1 机器学习 1.2 聚类算法 2. 聚类算法 2.1 实验目的 2.2 实验准备 2.3 实验原理 2.4 实验内容 2.4.1 K-means算法 2.4.2 K-mean++算
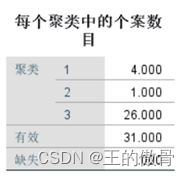
数学建模之聚类算法(K-means)
K-means聚类算法 k-means算法以k为参数,把n个对像分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低。 1、随机选择k个点作为初始的棸类中心。 2、对于剩下的点,根据其与棸类中心的距离,将其归入最近的簇。 3、对于每个簇,计算所有点的均值作为新的聚类中心。 4、重复2、3直到棸类中心不再发生改变。 K-means的案例分析 例1:现有1999年全国31个省份城镇居民家

机器学习-无监督学习之聚类
文章目录 K均值聚类密度聚类(DBSCAN)层次聚类AGNES 算法DIANA算法 高斯混合模型聚类聚类效果的衡量指标小结 K均值聚类 步骤: Step1:随机选取样本作为初始均值向量。 Step2:计算样本点到各均值向量的距离,距离哪个最近就属于哪个簇 Step3:重新计算中心点作为均值向量,重复第二步直到收敛常见距离 曼哈顿距离(街区距离)欧氏距离切比雪夫距离(棋盘距离)闵氏