中文信息专题

用codeblocks编写C 代码输出中文信息 怎么出现了乱码
Code::Blocks缺省文件编码是UTF-8 从菜单Settings->Compiler and debugger。。。。 打开编译器设定对话框,在Compiler setting tab上,选择Other Option,添加下面的设定 -fexec-charset=GBK -finput-charset=UTF-8 告诉编译器,文件输入字符编码是utf-8,执行时以gbk编码对待

eclipse ant 中文路径以及echo 中文信息的问题(转载)
在eclipse中运行ant build文件如果有中文路径或者echo的信息中包含中文(如:<echo message="正在创建目录,复制相关资源..." />),则build文件将无法正常运行。 解决办法:在run as ant build...配置想中修改字符集为utf-8,如下所示: 做了以上设置的话,控制台就能正常输出中文了。如下: <echo message

(深度学习快速入门)图对比学习综述笔记-中文信息学报2023第37卷第5期
文章目录 引言问题定义和相关背景图定义及其类型对比学习图神经网络图分析的下游任务 节点级图对比学习方法实例对比跨级别对比 边级别图对比学习图级别对比学习图对比学习扩展不同类型图上的扩展结合监督信息的图对比学习 图数据集介绍 引言 传统的图数据分析通常采用监督学习的框架,即通过人为特征提取或端到端图深度学习模型将图数据作为输入

论文笔记 中文信息学报 2019|基于联合标注和全局推理的篇章级事件抽取
文章目录 1 简介1.1 动机 2 方法3 实验 1 简介 论文题目:基于联合标注和全局推理的篇章级事件抽取 论文来源:中文信息学报 2019 论文链接:https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFDLAST2019& filename=MESS201909011&uniplatform=
《中文信息学报》佳文共赏∣ 袁毓林 李强:怎样用物性结构知识解决“网球问题”?(上)
文章导读 “网球问题”指怎样把racquet(网球拍)、ball(网球)和net(球网)之类具有情境联想关系的词汇概念联系起来、发现它们之间的语义和推理关系。这是一个自然语言处理和相关的语言知识资源建设的世界性难题。该文以求解“网球问题”为目标,对目前比较主流的几种语言词汇和概念知识库系统(包括WordNet、VerbNet、FrameNet、ConceptNet等)进行检讨,指出它们在解决

从JSP页面向数据库提交信息,乱码。读取数据库中原有的中文信息不乱码
从JSP页面向数据库提交信息,乱码。读取数据库中原有的中文信息不乱码 软件说明:Dreamweave+Mysql 解决方法:在jsp页面中插入以下代码,使发送和接收的代码类型统一。页面、数据库的代码也都要设置为gb2312 <%request.setCharacterEncoding("gb2312");%> <%response.setCharacterEncoding("gb231
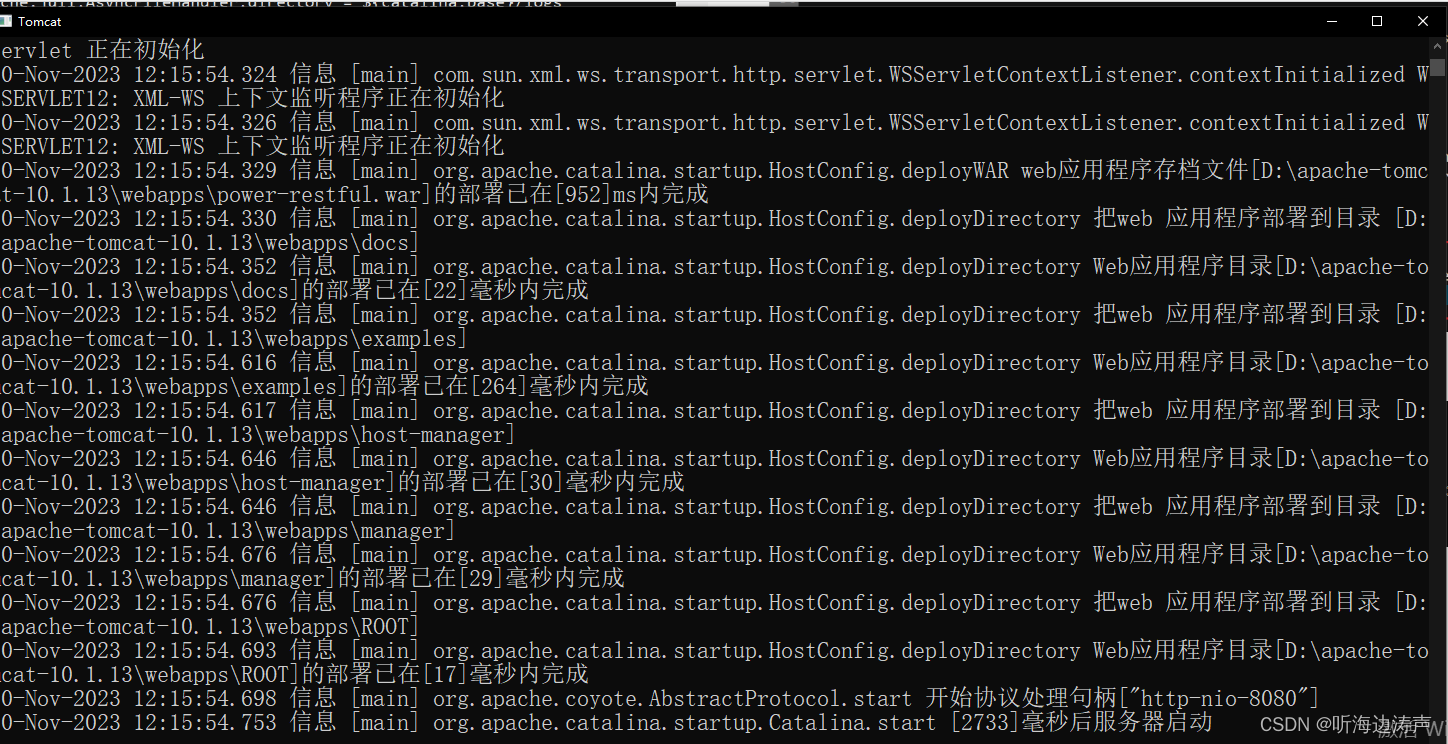
tomcat控制台中文信息显示乱码
问题现象 我的tomcat版本是10.1版本。 在cmd下启动tomcat,会新打开控制台输出窗口: 控制台窗口输出的中文信息是乱码: 问题原因 产生这个问题的原因是:控制台窗口的编码和输出到控制台窗口的日志信息编码不一致。 查看tomcat控制台窗口的编码 可以看到,tomcat控制台窗口当前的代码页是936,也就是GBK。 查看tomcat输出日志信息到控制台的编码