xl专题

使用亚马逊Bedrock的Stable Diffusion XL模型实现文本到图像生成:探索AI的无限创意
引言 什么是Amazon Bedrock? Amazon Bedrock是亚马逊云服务(AWS)推出的一项旗舰服务,旨在推动生成式人工智能(AI)在各行业的广泛应用。它的核心功能是提供由顶尖AI公司(如AI21 Labs、Anthropic、Cohere、Meta、Mistral AI、Stability AI以及亚马逊自身)开发的多种基础模型(Foundation Models,简称FMs)。

A Tutorial on Near-Field XL-MIMO Communications Towards 6G【论文阅读笔记】
此系列是本人阅读论文过程中的简单笔记,比较随意且具有严重的偏向性(偏向自己研究方向和感兴趣的),随缘分享,共同进步~ 论文主要内容: 建立XL-MIMO模型,考虑NUSW信道和非平稳性; 基于近场信道模型,分析性能(SNR scaling laws,波束聚焦、速率、DoF) XL-MIMO设计问题:信道估计、波束码本、波束训练、DAM XL-MIMO信道特性变化: UPW ➡ NU

Stable Diffusion【XL Lora】推荐!AI助力服装设计,让服装拆分设计就是这么高效!
今天给大家介绍一个服装饰品分类背景的基于SDXL的Lora模型:分类背景 XUER。该模型是由作者(B站绪儿已成精)炼制,非常适合饰品服装分类背景。绪儿大佬其实推出了很多非常棒的模型,比如之前非常受大家喜欢的敦煌飞天、超梦幻场景等模型。 下面我们来实际体验一下,看使用这个模型出来的图片效果如何吧。 下载链接 https://www.liblib.art/modelinfo/c0

太赞了!MJ级细节质感!影视级数据升级!SD RealMyth-真神武侠XL丨写实国风-电影质感
今天带来了一款电影感武侠写实国风大模型——RealMythXL-神话,最新版本为本月发布的V5.5_Super版本。该版本为 V5 Super 的再精修版本 ,增强了国风神话元素,进行了领先于MJ级别的细节质感强化 ,作者在v5 版本的基础上进行了微调融合,采用了电影级的数据升级,并尝试了对建筑结构体的升级强化,提升了人像细节,增加了出图率,对古风传统服装元素以及中国神话概念进行了针对性的训练

Stable Diffusion【XL Lora】效果太赞了!AI助力服装设计,让服装拆分设计就是这么高效
今天带了一款 非常适合服装设计的SD XL Lora模型——【服装拆分】绪儿 分类背景 XUER,该模型是由绪儿大佬炼制,非常适合饰品服装分类背景。绪儿大佬其实推出了很多非常棒的模型,比如之前非常受大家喜欢的敦煌飞天、超梦幻场景等模型。 那么我们今天一起来看一看这款服饰拆分模型。 Lora模型下载地址: https://www.liblib.art/modelinfo/c0b7a367971

【XML】XL,SL,PL三者之间的区别与联系
在学习牛腩新闻发布系统的时候,我们用到了多种语言,例如 HTML ,C#,JavaScript,它们分别为超文本标记语言,程序语言,脚本语言。今天我们就讲一下这些语言之间的区别与联系。 一、定义 1、 ML 学习完了XML和HTML,这二者有什么共同点呢?是不是都有ML呢?他们都属于ML。 今天我们先介绍一下ML(Mar

挑战Midjourney,融合近百个SD大模型的通用模型AlbedoBase XL
在SDXL的通用模型中,DreamShaperXL和juggernautXL这2款大模型一直都深受广大AI绘画者的喜爱,不可否认,这2款通用模型在很多方面表现都相当出色。 今天再给大家介绍一款基于SDXL的通用大模型:AlbedoBase XL,作者的目标是直接测试所有公开上传到Civitai**的大模型和LoRA的性能,通过多个过滤器后合并被判定为最优的大模型。该大模型将超越Midjourne

Aosp8.1 pixel xl 生成vendor.img
编译android 8.1 marlin ,默认不会生成vendor.img 这个是因为在build/core/MakeFile中 build vendorimage 条件不满足 ----build/core/MakeFile 是软连接 实际路径在 /system/build/make/下面 makefile 缺少参数 BOARD_VENDORIMAGE_PARTITION_SIZE 所以
Diffusion Model, Stable Diffusion, Stable Diffusion XL 详解
文章目录 Diffusion Model生成模型DDPM概述向前扩散过程前向扩散的逐步过程前向扩散的整体过程 反向去噪过程网络结构训练和推理过程训练过程推理过程优化目标 详细数学推导数学基础向前扩散过程反向去噪过程 Stable Diffusion组成结构运行流程网络结构变分自编码器 (VAE)文本编码器 (CLIP Text Encoder)噪音预测器 (Unet) 训练过程和损失函数V

Stable Diffusion 模型分享:CyberRealistic XL(真实)cyberrealisticXL_v11VAE.safetensors
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里,订阅后可阅读专栏内所有文章。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八 下载地址 模型介绍 这是 CyberRealistic 的 SDXL 版本。 该模型的标准是使用简单性和多功能性。所以,没有复杂的提示(如果你愿意的话也可以);只需释放您的想象力。享受并玩得开心! 条目

chrome的异常Uncaught ReferenceError: xl_chrome_menu is not defined
Chrome的javascript控制台中出现下所示的异常,目前发现的原因是因为安装了迅雷的下载插件。删除之,问题解消。 [img]http://dl.iteye.com/upload/attachment/0069/5519/d5abfa06-b7b4-3cd3-92e1-96032aea7f15.png[/img]

信捷 XD/XL plc 单精度/双精度浮点数比较 ECMP,EDCMP
对于单精度浮点数,用ECMP指令。 对于双精度浮点数,用EDCMP指令 注意:EDCMP 指令中寄存器的首地址必须为偶数。
ElementUI响应式Layout布局xs,sm,md,lg,xl
响应式布局 参照了 Bootstrap 的 响应式设计,预设了五个响应尺寸:xs、sm、md、lg 和 xl。 <el-row :gutter="10"><el-col :xs="8" :sm="6" :md="4" :lg="3" :xl="1"><div class="grid-content bg-purple"></div></el-col><el-col :xs="4" :sm="6

AI Benchmark v4 Device选择:Google Pixel 4/XL简析
田海立@CSDN 2020-10-07 AI Benchmark v4测试项更新以及榜单数据解读知道了AI Benchmark执行的时候可以选择NNAPI,也可以直接用TFLite里的Delegate。Google Pixel 4/XL里用的芯片是高通骁龙855+Google TPU Edge,设备如何选择,选择的是否合理,这里简要分析之。 把榜单soc数据拷贝下来,复制到Excel表格

Stable Diffusion XL之使用Stable Diffusion XL训练自己的AI绘画模型
文章目录 一 SDXL训练基本步骤二 从0到1上手使用Stable Diffusion XL训练自己的AI绘画模型2.1 配置训练环境与训练文件2.2 SDXL训练数据集制作(1) 数据筛选与清洗(2) 使用BLIP自动标注caption(3) 使用Waifu Diffusion 1.4自动标注tag(4) 补充标注特殊tag(5) 训练数据预处理(标注文件整合) 2.3 SDXL微调(fi
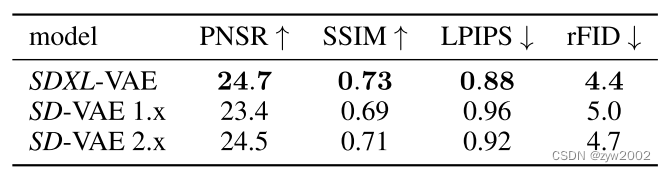
Stable Diffusion XL之核心基础内容
Stable Diffusion XL之核心基础内容 一. Stable Diffusion XL核心基础内容1.1 Stable Diffusion XL的主要优化 一. Stable Diffusion XL核心基础内容 1.1 Stable Diffusion XL的主要优化 与Stable Diffusion 1.x-2.x相比,Stable Diffusion XL
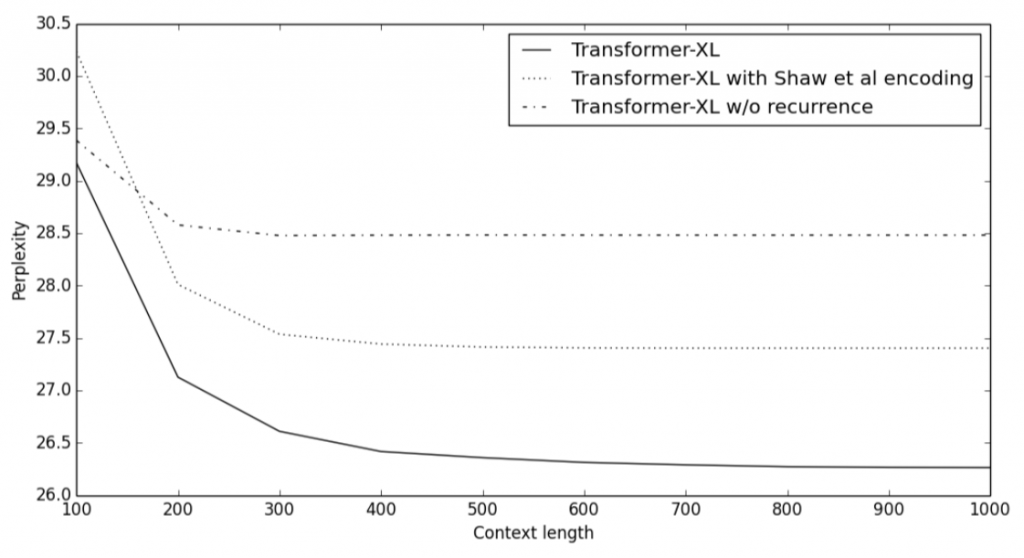
[论文笔记] Transformer-XL
这篇论文提出的 Transformer-XL 主要是针对 Transformer 在解决 长依赖问题中受到固定长度上下文的限制,如 Bert 采用的 Transformer 最大上下文为 512(其中是因为计算资源的限制,不是因为位置编码,因为使用的是绝对位置编码正余弦编码)。 Transformer-XL 能学习超过固定长度的依赖性,而不破坏时间一致性。它由 段

Stable Diffusion 模型分享:AAM XL (Anime Mix)(动漫截屏风格 XL)
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八 下载地址 模型介绍 AAM XL (Anime Mix) 是一个动漫截屏风格的模型,是 AAM - AnyLoRA Anime Mix 模型的 SDXL 版本。即使在原始 AAM 或 AnyLoRA 上进行训练,它也无法与 SD1.
Stable Diffusion 模型分享:FenrisXL(芬里斯XL)
本文收录于《AI绘画从入门到精通》专栏,专栏总目录:点这里。 文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十

Stable Diffusion 模型下载:DreamShaper XL(梦想塑造者 XL)
文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十 下载地址 模型介绍 DreamShaper 是一个分格多样的大模型,可以生成写实、原画、2.5D 等多种图片,能生成很棒的人像和风景图。 DreamShaper是一个通用的SD模型,旨在做好一切,照片,艺术,动漫,漫画。它的设计是为了对抗其他通用模型和管道,如Midjourney和DAL

Cadence Virtuoso ADE_XL 仿真初使用(基于Cadence 617)
Cadence Virtuoso ADE_XL 仿真初使用(基于Cadence 617) 在进行virtuoso仿真时,为满足电路的设计指标,难免会在多个工艺角和PVT条件下仿真,用ADE_L又麻烦又慢,ADE_XL完美解决问题! 下面以两级运放为例,讲述使用方式。 初探ADE_XL Cadence Virtuoso ADE_XL 仿真初使用(基于Cadence 617) 1.仿真设置2.
Stable Diffusion 模型下载:Juggernaut XL - V8+RunDiffusion
文章目录 模型介绍生成案例案例一案例二案例三案例四案例五案例六案例七案例八案例九案例十 下载地址 模型介绍 Juggernaut XL 是一个偏真实的模型,在人物的表现力方面还是很逼真的,包裹肤质、光影等细节都能绘制得很到位。对于场景、物体、风景等的表现力也有做了训练。 V8 的重点是手、脚、皮肤细节和照片输出。然而,手脚是一个正在进行的项目,在 V

Pixel3 XL 刷Android原生系统,刷Magisk 进行ROOT
Pixel3 XL 刷Android原生系统,刷Magisk 进行ROOT 前言一、基本信息二、解锁OEM和BL三、驱动安装下载四、刷入google官方镜像五、刷入面具Magisk,ROOT总结 前言 本篇博客记录pixel3xl 刷机,Magisk root过程。本操作会重置系统,故需要提前备份系统信息。 一、基本信息 手机基本信息:欧版,4G/64G设备名称
Transformer-XL解读(论文 + PyTorch源码)
前言 目前在NLP领域中,处理语言建模问题有两种最先进的架构:RNN和Transformer。RNN按照序列顺序逐个学习输入的单词或字符之间的关系,而Transformer则接收一整段序列,然后使用self-attention机制来学习它们之间的依赖关系。这两种架构目前来看都取得了令人瞩目的成就,但它们都局限在捕捉长期依赖性上。 为了解决这一问题,CMU联合Google Brain在2019年

利用GPU加速自定义风格图像生成-利用GPU加速结合了ControlNet/ Lora的Stable Diffusion XL
点击链接完成注册,参加本次在线研讨会 https://www.nvidia.cn/webinars/sessions/?session_id=240124-31319 随着AI技术的发展, 数字内容创建业务也变得越来越火热。生成式AI模型的发布, 让我们看到了人工智能在各行各业的潜力。您只需要用语言简单描述自己希望看到的画面, AI便可以自动生成画作。生成式AI模型的广泛应用,不仅提高了我们的
【自然语言处理】Transformer-XL 讲解
Transformer-XL 首先需要明确,Transformer-XL(XL 是 extra long 的简写)只是一个堆叠了自注意力层的 BPTT 语言模型,并不是 Transformer 原始论文中提到的编码器-解码器架构,也不是原始 Transformer 中的编码器部分或者解码器部分,根据其大致实现可以将其理解为丢弃 cross attention 模块的 Transformer 解码