weka专题

如何获取Weka源码
要研究数据挖掘,Weka是不可或缺的工具,下面就来说说如何在myeclipse中引入Weka源码。 1.首先官网上下载weka源码,有两种方式,一种是下载安装文件,安装后在安装目录中会有一个 weka-src.jar ,解压后即为源码,另一种是通过SVN下载: https://svn.cms.waikato.ac.nz/svn/weka/trunk/weka 机子上需要SVN工具
Java集成Weka做线性回归的例子
之前研究完分类的逻辑回归,继续搞一下线性回归看看。线性回归在数据挖掘领域应也是非常常见,即根据现有的数据集(行向量组成的矩阵),(训练)模拟出一个合适的规律(函数),来推测任何新给出的数据组合(向量)应该得到的值。 具体的描述可以参见各种博客,怎么推导的看来看去一知半解,但总而言之结果也简单,就是计算得到一个“适当”的多元线性函数Y=a0+a1*x1+a2*x2+a3*x3+…+ak*xk。

调用WEKA包进行kmeans聚类(java)
所用数据文件:data1.txt [plain] view plain copy print ? @RELATION data1 @ATTRIBUTE one REAL @ATTRIBUTE two REAL @DATA 0.184000 0.482000 0.152000 0.540000 0.152000 0.5
weka数据预测 分类回归 方法 参数 总结
1.线性回归(LinearRegression) 1.1原理 在统计学中,线性回归是利用称为线性回归方程的最小平方函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。 1.2最小二乘法原理 线性回归模型经常用最小二乘逼近来拟合,但他们也可能
通过weka.jar包来进行数据预处理
打开eclipse ,在对应的工程下右击,选择Build Path ->选择Configure Build Path ->选择Libraries ->点击Add External JARs ->然后到你的jar包所在路径选择它。即可。 一、特征选择 [java] view plain copy print ? package learning;

weka打开csv提示attribute names are not unique! Cause:
谢邀,人在实验室,没有中文补丁我要死了,希望weka没事 如题,初学weka,自己设了个CSV,想要试试weka的转换格式功能,没想到出现了提示attribute names are not unique! Cause:‘’ 这里的 Causes:‘85’,意思是自动识别首行的列名时,识别到了纯数字(数据如下图,首行有个 “85”),而纯数字不能作为列名* 加上列名后再导入就可以了
weka实战005:基于HashSet实现的apriori关联规则算法
这个一个apriori算法的演示版本,所有的代码都在一个类。仅供研究算法参考 package test;import java.util.Collections;import java.util.HashMap;import java.util.HashSet;import java.util.Iterator;import java.util.Vector;//用set写的a
weka实战004:fp-growth关联规则算法
apriori算法的计算量太大,如果数据集略大一些,会比较慢,非常容易内存溢出。 我们可以算一下复杂度:假设样本数有N个,样本属性为M个,每个样本属性平均有K个nominal值。 1. 计算一项频繁集的时间复杂度是O(N*M*K)。 2. 假设具有最小支持度的频繁项是q个,根据它们则依次生成一项频繁集,二项频繁集,....,r项频繁集合,它们的元素数量分别是:c(q, 1), c(q,

weka实战003:apriori关联规则算法的实现
weka实现的apriori算法是在weka.associations包的Apriror类。 在这个类,挖掘关联规则的入口函数是public void buildAssociations(Instances instances),而instances就是数据集,检查数据,设置参数,初始化变量,然后,用一个do-while循环计算关联规则。如果你看过上一篇,就知道其实就是从一项频繁集开始,逐
weka实战002:apriori关联规则算法
关联规则算法最出名的例子就是啤酒和尿布放一起卖。 假如我们去超市买东西,付款后,会拿到一张购物清单。这个清单就是一个Transaction。对关联规则算法来说,每个产品的购买数量是无意义的,不参与计算。 许许多多的人买东西,生成了N个购物清单,也就是N个Transaction。 那么,这些Transaction上的货物之间有什么有用的关系呢?这些关系可以用什么方式表达出来呢
Weka -- 数据格式基本介绍
Weka是什么不多介绍,直接切入正题,简单介绍Weka的数据格式。 Weka存储数据的格式是ARFF(Attribute-Relation File Format)文件,是一种ASCII文本文件。如下例,weka自带的weather.arff文件。 % ARFF file for the weather data with some numric features % @relati
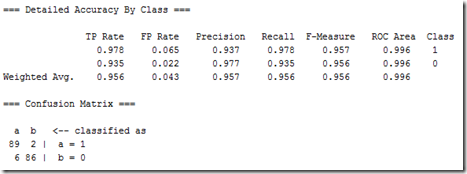
【转】weka里Detailed Accuracy By Class和 Confusion Matrix的含义
confusion matrix通常称为contingency table,我们现在讨论的case里有两个class。这个matrix可以非常大。正确分类的instances数是matrix的对角线上数字的和,其他的都是不正确分类的。斜对角线上的数字为假正和假负。 True positive(TP) rate,被正确分类为class x的比率。与recall相同。=正确分类为class
ubuntu14.04下设置weka访问数据库——数据分析环境搭建2
首先确保你已经做好了weka最基本的配置,详见 http://blog.csdn.net/tsinghuahui/article/details/49661795 1. 下载并安装mysql数据库: sudo apt-get mysql-server 通过以上命令安装后的mysql可以直接用~,可通过在命令行键入 "mysql -u root -p" 测试。 2. 下载JDBC驱动

ubuntu14.04下weka的安装与配置——数据分析环境搭建1
首先请确保你已经配置好了JDK。详细过程参见“虫师”的博客 http://www.cnblogs.com/fnng/archive/2013/01/30/2883815.html 1. 下载weka 下载地址为:http://www.cs.waikato.ac.nz/ml/weka/downloading.html 我选择的时developer version,与linux对应的版本

关于机器学习的Weka软件详细教程(转载)
转载自https://www.cnblogs.com/hxsyl/p/3307343.html 下载与安装:链接:https://pan.baidu.com/s/14GMxr1mss_bm0bUoLNJnIw 密码:fvby (64位) Weka提供的功能有数据处理,特征选择、分类、回归、聚类、关联规则、可视化等。本文将对Weka的使用做一个简单的介绍,并通过简单的示例,使大家了解使用weka
数据挖掘-Weka的安装与使用
目录 一、下载与安装 1.下载 2.安装 二、启动以及初步使用 三、其他教程 1.weka环境变量的配置 2.weka更详细的使用教程! 一、下载与安装 1.下载
weka源码调试libSVM出现libsvm classes not in CLASSPATH
在eclipse中调试weka,在使用LibSVM时,发现直接运行的时候提示libsvm classes not in CLASSPATH 解决方式: Run Configuration-Classpath-Add External JARs 添加LibSVM.jar 即可。 weka 3.6.10

J48 源码学习| Weka
J48 C4.5决策树算法源码学习 TODO: J48 的分类效率分析。 题记: 之前虽然对 J48 用得比较多,是由于它能方便的区别特征的好坏。 工作了,希望自己能更深入, 如是开始了这个算法学习系列。 希望和大家共同进步。 个人对看算法源代码也没有很好的流程,计划先采用 按类Class 做架构介绍;再深入代码具体逻辑的方式展开。 欢迎大家提出好的算法源码阅读流程。 另外,求推
weka 学习资料链接
[1] Primer – Weka Wiki 链接 [2]《Data Mining Practical Machine Learning Tools and Techniques》Chapter 15:471-485 [3] 在weka中加入自己的算法 链接 [4]《Data Mining Practical Machine Learning Tools and Techniques》Chapte
weka 中的算法名说明
1) 数据输入和输出 WOW():查看Weka函数的参数。 Weka_control():设置Weka函数的参数。 read.arff():读Weka Attribute-Relation File Format (ARFF)格式的数据。 write.arff:将数据写入Weka Attribute-Relation File Format (ARFF)格式的文件。 2) 数

基于WEKA实现时间序列的预测
时间序列预测是根据客观事物发展的规律性,运用历史数据来推测未来的发展趋势。 时序预测是一项应用非常广的技术,如股票预测,天气预测等。 然而时序预测也是一项比较难的地方,主要是短期预测可能还比较准,而对一段时间的预测则会比较难。 在学习时序预测过程中,先看了WEKA的功能。WEKA本身是不带这功能的,不过还好,WEKA方面倒是这样的分析插件,运行一下,里面提供的界面还是相对可
Weka source code sample good website
http://weka.sourcearchive.com/documentation/3.6.0/ThresholdVisualizePanel_8java-source.html
一步一步构建自己的BayesNet代码-基于Weka
首先要把握清楚BayesNet大体上是怎么用:有一个主特征:Class,目的就是判断这个Class的值,BayesNet从训练数据中学习出一个模型,用这个模型做预测,预测测试数据中的Class的值,每个实例是一行,Class T1 T2......Tn T是指特征也就是属性。所以我们的目标任务功能就是自己写代码,完成上述这个过程。好了现在开始。 (套用Weka中的解释: WEKA把分类