weaviate专题

我的第2个AI项目-RAG with Gemma hosted on HuggingFace and Weaviate in DSPy
目录 项目简介概述时间kaggle地址主要工作和收获技术栈数据集模型表现 未来项目说明思路和原则为什么不把现在的项目做深一点?博客风格转变 bug修复版本兼容问题 项目简介 概述 本项目简要介绍了如何使用 DSPy 构建一个简单的 RAG 管道,且利用了托管在 Hugging Face 上的 Gemma LLM模型 和 Weaviate 向量数据库。 时间 2024.09
私有化文本嵌入(Embedding) + Weaviate
weavaite向量库可以集成第三方托管的模型,这使得开发体验得到了增强,例如 1、将对象直接导入Weaviate,无需手动指定嵌入(Embedding) 2、使用生成式AI模型(LLM)构建集成检索增强生成(RAG)管道 同时weaviate也可以与Transformers库无缝集成,允许用户直接在Weaviate数据库中利用兼容的模型。这些集成使开发人员能够轻松构建复杂的人工智能驱动应用
动态 ETL 管道:使用非结构化 IO 将 AI 与 MinIO 和 Weaviate 的 Web
在现代数据驱动的环境中,网络是一个无穷无尽的信息来源,为洞察力和创新提供了巨大的潜力。然而,挑战在于提取、构建和分析这片浩瀚的数据海洋,使其具有可操作性。这就是Unstructured-IO 的创新,结合MinIO的对象存储和Weaviate的AI和元数据功能的强大功能。它们共同创建了一个动态 ETL 管道,能够将非结构化 Web 数据转换为结构化的、可分析的格式。 本文探讨了这些强大技术的


使用MinIO S3存储桶备份Weaviate
Weaviate 是一个开创性的开源向量数据库,旨在通过利用机器学习模型来增强语义搜索。与依赖关键字匹配的传统搜索引擎不同,Weaviate 采用语义相似性原则。这种创新方法将各种形式的数据(文本、图像等)转换为矢量表示形式,即捕捉数据上下文和含义本质的数字形式。通过分析这些向量之间的相似性,Weaviate提供了真正了解用户意图的搜索结果,从而超越了基于关键字的搜索的局限性。 本指南旨在演示

《向量数据库指南》——向量数据库Weaviate Cloud 特性对比
随着以 Milvus 为代表的向量数据库在 AI 产业界越来越受欢迎,传统数据库和检索系统也开始在快速集成专门的向量检索插件方面展开角逐。 例如 Weaviate 推出开源向量数据库,凭借其易用、开发者友好、上手快速、API 文档齐全等特点脱颖而出。同样,Zilliz Cloud/Milvus 向量数据库因为能够高性能、低时延处理海量数据而备受瞩目。 二者都是专为向量数据打造,但适用于
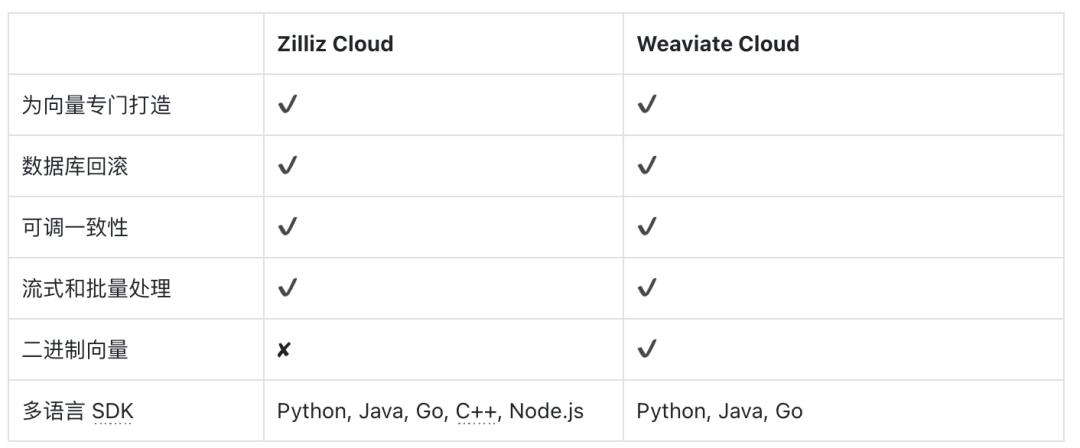
如何选择向量数据库|Weaviate Cloud v.s. Zilliz Cloud
随着以 Milvus 为代表的向量数据库在 AI 产业界越来越受欢迎,传统数据库和检索系统也开始在快速集成专门的向量检索插件方面展开角逐。 例如 Weaviate 推出开源向量数据库,凭借其易用、开发者友好、上手快速、API 文档齐全等特点脱颖而出。同样,Zilliz Cloud/Milvus 向量数据库因为能够高性能、低时延处理海量数据而备受瞩目。 二者都是专为向量数据打造,但适用于不同场景。