wav2vec专题

⌈ 传知代码 ⌋ 语音预训练模型wav2vec
💛前情提要💛 本文是传知代码平台中的相关前沿知识与技术的分享~ 接下来我们即将进入一个全新的空间,对技术有一个全新的视角~ 本文所涉及所有资源均在传知代码平台可获取 以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!! 以下内容干货满满,跟上步伐吧~ 📌导航小助手📌 💡本章重点🍞一. 概述🍞二. 基本原理🍞三. 未来应用与挑战🍞四. 参考案例🍞五
Wav2Vec 2.0:语音表示自监督学习框架
Wav2Vec 2.0是目前自动语音识别的模型之一。 Wav2Vec 2.0 代表了无监督预训练技术在语音识别领域的重大进步。这些方法通过直接从原始音频中学习,无需人工标记,因此可以有效利用大量未标记的语音数据集。相比于传统的监督学习数据集通常只有大约几百小时的标记数据,这些新方法已经能够扩展到使用多达 1,000,000 小时的未标记语音进行训练。在标准基准测试上进行微调后,这种方法在低数据环

WAV2VEC:语音识别非监督预训练模型
1 简介 本文根据2019年《WAV2VEC: UNSUPERVISED PRE-TRAINING FOR SPEECH RECOGNITION》翻译总结的。 在图像、NLP领域,预训练已大放异彩,而语音识别领域尚缺乏。本文提的WAV2VEC就是语音识别方面的非监督预训练模型,也如论文题目所说。相比Deep Speech 2,WER(word error rate)从3.1%降到2.43%。
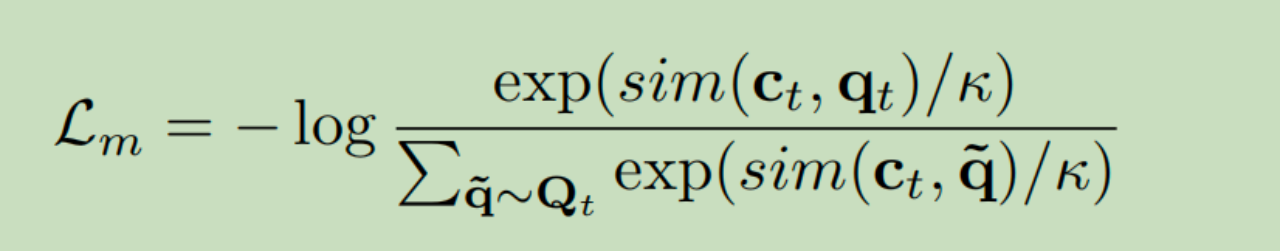
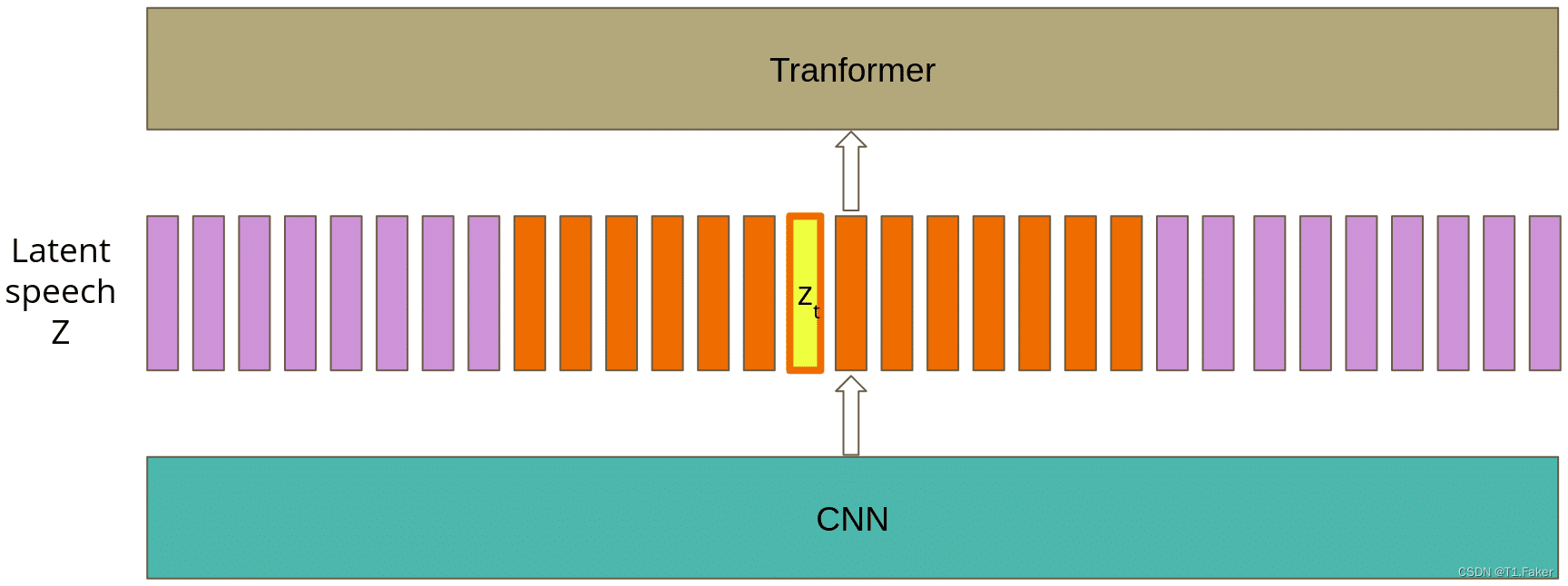
wav2vec 2.0:一种自监督的语音识别方法
总体框架: 主要分为2个大模块:1:语音特征提取模块 2:语音特征向量融合模块 1:特征提取模块 输入:音频 输出:音频特征向量 过程: 1)跟具体采样率有关,如果一段1S的音频,采样率是16K,则这段1S的音频可以用1*16000的矩阵表示。 2)此模块的结构: 文章使用了7层的CNN,步长为(5,2,2,2,2,2,2),卷积核宽度为(10,3,3,3,3,2,2),假设输入语音